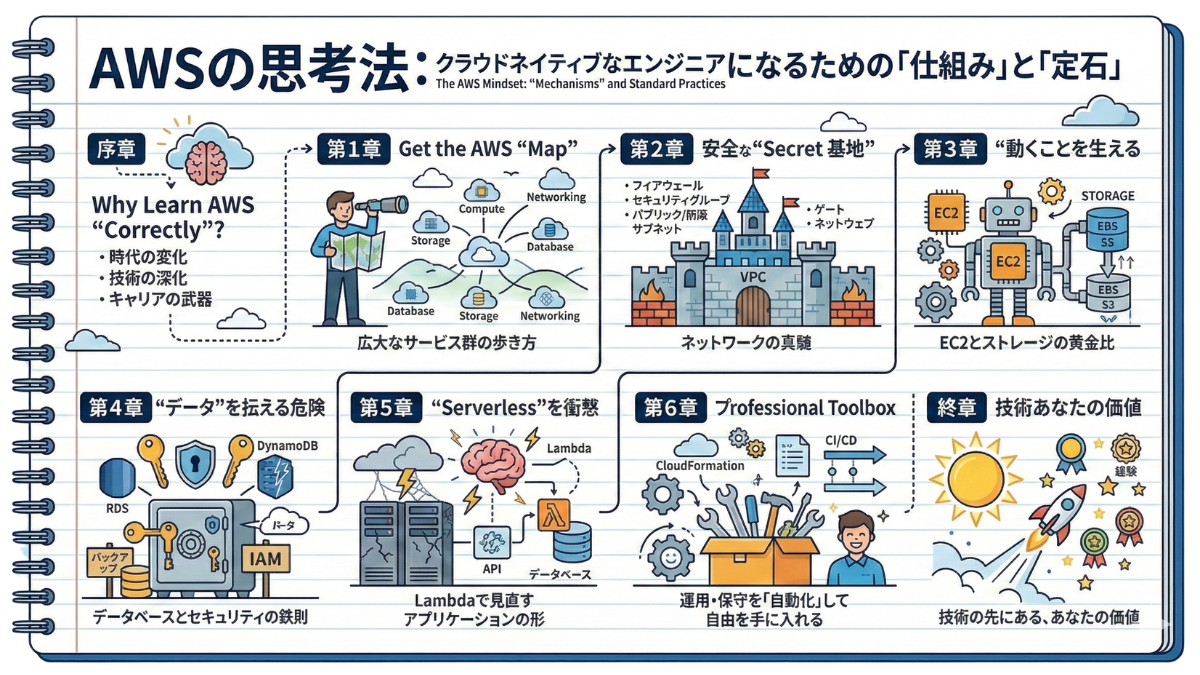
『AWSインフラ構築・設計完全ガイド|初心者から現場で活躍するための思考法と技術を網羅』
—— とりあえずチュートリアルの通りに画面をクリックしたら、サーバーは動いた。でも、自分が何を作ったのかは、実はよくわかっていない。
もしあなたが今、そんな「透明な壁」にぶつかっているのなら、どうか安心してください。それは、クラウドという新しい世界に足を踏み入れたすべてのエンジニアが必ず直面する、避けては通れない壁です。
AWSのアカウントを開設し、手順書をなぞってEC2インスタンスを立ち上げる。そこまでは誰でも到達できます。しかし、いざ「本番環境に耐えうるセキュアなインフラを設計してほしい」と言われた途端、ピタリと手が止まってしまう。
VPCのサブネット設計で正解がわからず迷い、IAMの複雑な権限エラーに頭を抱え、月末に届くかもしれない想定外の請求書に怯える。マネジメントコンソールに並ぶ数百ものサービス群を前に、「自分は本当にクラウドを理解できているのだろうか」と静かな絶望を覚えた経験は、決してあなただけのものではありません。
「知っているつもり」と「現場で使える」という2つの地点の間には、想像以上に深く、険しい断絶が横たわっています。
なぜ、このようなギャップが生まれてしまうのでしょうか?それは多くの場合、AWSを単なる「便利な機能の寄せ集め」や「操作手順の暗記科目」として捉えてしまっているからです。
AWSは、完成されたシステムを貸してくれるサービスではありません。用途に合わせて組み合わせる「ビルディングブロック」であり、世界最高峰のビジネスインフラを支えてきた「設計思想」そのものです。つまり、私たちが本当に学ぶべきは、明日にはアップデートで変わってしまうかもしれない画面のボタンの位置ではなく、ブロックを正しく組み合わせるための『AWSの思考法』なのです。
すぐに陳腐化する小手先のテクニックではなく、流行り廃りに流されないクラウドネイティブなインフラを構築するための「普遍的な仕組み」と、プロが現場で息をするように使っている「定石」です。
本記事は、初級者の殻を破り、自信を持って「自分はAWSで価値を生み出せる」と宣言したい中級者への架け橋として執筆しました。
オンプレミス(物理サーバー)思考からの脱却から始まり、堅牢なネットワークの構築、止まらないシステムの設計、そして運用・保守の自動化に至るまで。これまであなたの頭の中でバラバラに散らばっていた知識の「点」が、明確な根拠を持って繋がり、一本の美しい「線」を描き出す瞬間を約束します。
さあ、クラウドの迷宮を抜け出すための「羅針盤」を手に入れる準備はできましたか?あなたのエンジニアとしての市場価値を根底から引き上げる、至高のロードマップへようこそ。
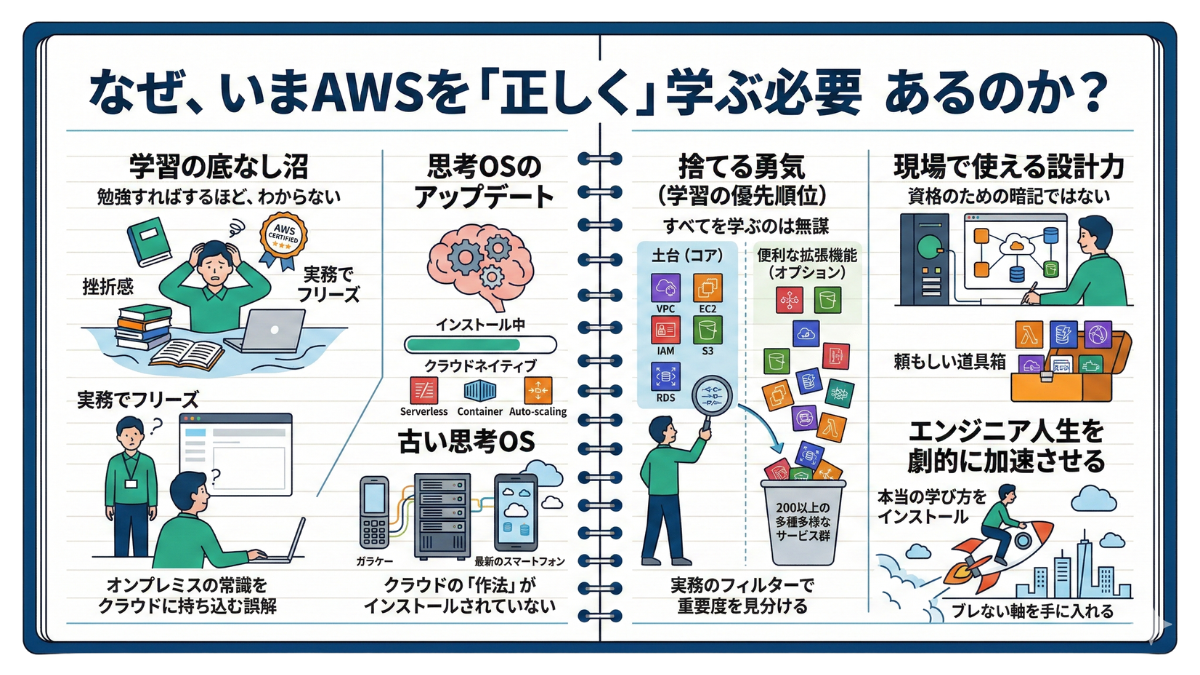
【序章】なぜ、いまAWSを「正しく」学ぶ必要があるのか?
—— 勉強すればするほど、わからなくなる。そんな学習の底なし沼に、あなたも足を踏み入れていませんか?
AWSの学習を始めた多くのエンジニアが、最初の数週間で強烈な挫折感を味わいます。例えば、AWS認定資格のテキストを読み込み、用語を暗記し、模擬試験では高得点が取れるようになったとしましょう。知識のストックは確実に増えているはずです。しかし、いざ「自社の新しいWebサービスをAWSで構築してみてよ」と実務を振られた途端、頭が真っ白になる。真っ新なマネジメントコンソールを前にして、何から設定していいのか見当もつかない。
それは、あなたが努力していないからでも、エンジニアとしてのセンスがないからでもありません。ただ、AWSに対する「学び方のルール」を誤解しているだけなのです。
なぜ、あるエンジニアはAWSを魔法のように使いこなし、息をするようにシステムを構築できるのに、あなたはフリーズしてしまうのでしょうか。その決定的な違いは、知っているサービスの「数」ではありません。頭の中で稼働している「思考のOS」にあります。
AWSで行き詰まる人の多くは、オンプレミス(物理環境)で培ったネットワークやサーバー構築の常識を、そのままクラウドに持ち込もうとします。それは例えるなら、最新のスマートフォンを、昔のガラケーの取扱説明書を読みながら操作しようとするようなものです。画面(UI)は似ていても、裏側で動いている哲学は全く異なります。
クラウドには、クラウド特有の「作法」が存在します。それをインストールしないまま、どれほど公式ドキュメントを読み漁っても、辞書をAから順に暗記するような苦痛が続くだけです。だからこそ本章ではまず、あなたの頭の中にある設計OSを「クラウドネイティブ」へと書き換える作業から始めます。
そして、視界を劇的にクリアにするもう一つのカギ。それが「捨てる勇気(学習の優先順位)」です。 現在のAWSには、200を超える多種多様なサービス群が存在します。これらをすべて均等に学ぼうとするのは、フルマラソンを全速力で走り出そうとするような無謀な行為です。実務において、すべてのサービスをマスターする必要は一切ありません。入門書を開く前に絶対に知っておくべきこと。それは「どのサービスがインフラの『土台(コア)』であり、どれが便利な『拡張機能(オプション)』なのか」を瞬時に見分ける、プロのフィルターです。
本章であなたにお伝えするのは、明日には画面が変わってしまうかもしれない操作手順ではありません。あなたの中の学習OSを根本からアップデートし、「資格のための暗記」を「現場で使える設計力」へと昇華させるための『ブレない軸』を手に入れることです。
この章を読み終える頃には、無数に見えて恐怖すら感じていたAWSのサービス群が、自分の手で自由に操れる「頼もしい道具箱」のように身近で、楽しいものに変わっているはずです。
さあ、これまでのがむしゃらな学習を一度リセットして、AWSの「本当の学び方」をインストールしましょう。あなたのエンジニア人生を劇的に加速させる準備は、ここで整います。
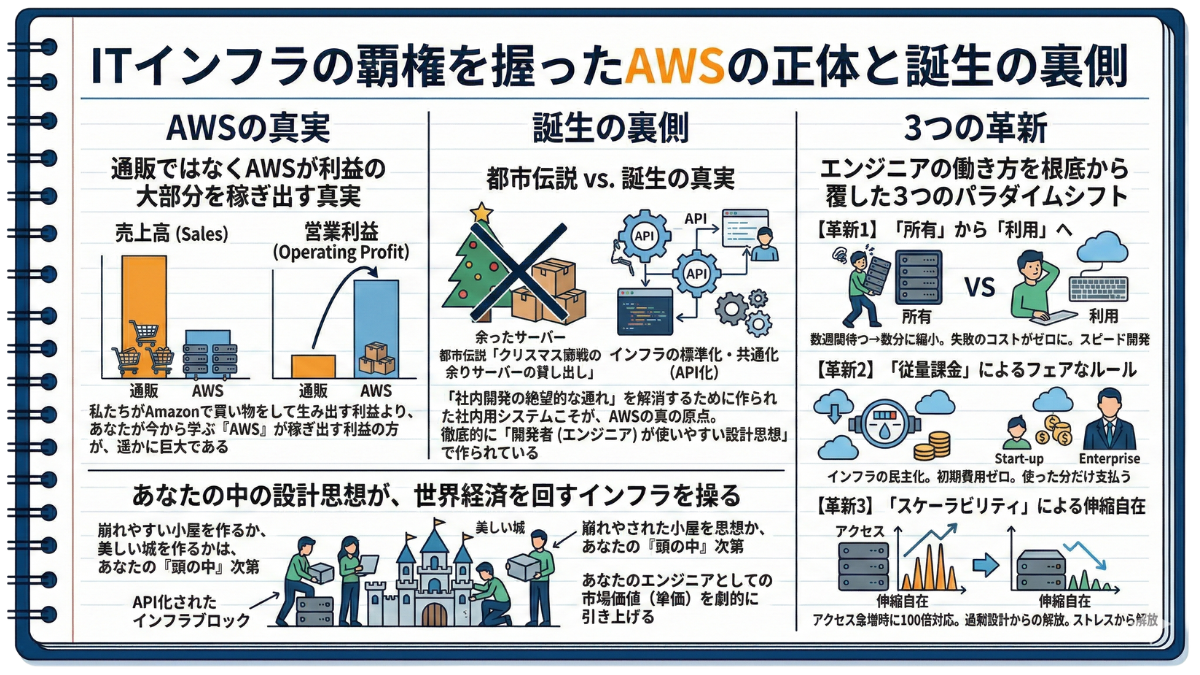
私たちが普段使っているAmazon。実はその利益の大部分を稼ぎ出しているのが「通販」ではなく「AWS」だと知っていますか?
本節では、ITインフラの覇権を握ったAWSの驚くべき正体と、その誕生の裏側に迫ります。
『AWS』の正体:巨大ECサイトの「裏方」が世界のビジネスを支配するまで
—— 私たちがAmazonで買い物をして生み出す利益より、あなたが今から学ぶ『AWS』が稼ぎ出す利益の方が、遥かに巨大である。この事実をご存知でしょうか?
画像嗄声性から
IT業界に身を置いていれば、誰もが知ることになる「AWS(Amazon Web Services)」。 多くの入門書は、「Amazonが提供するクラウドコンピューティングサービスです」という無味乾燥な一行で説明を済ませてしまいます。
しかし、その程度の理解では、現場で生きたインフラを設計することはできません。AWSの全貌を正しく把握するためには、「何であるか」だけでなく、「なぜ生まれ、どうやって世界を制したのか」を紐解く必要があります。
—— 通販の「おまけ」が「最強の稼ぎ頭」になるという衝撃
まず、エンジニアとして絶対に知っておくべきビジネスの真実をお伝えします。
Amazonといえば「世界最大の通販サイト」というイメージですが、実は会社の「営業利益(本業の儲け)」の過半数を叩き出しているのは、通販部門ではなく、この『AWS』なのです。
売上高全体で見れば通販事業の方が圧倒的に大きいにもかかわらず、利益面ではAWSがAmazonという巨大帝国の屋台骨を支えています。
なぜこの事実を知るべきなのか?それは、「現代のビジネスにおいて最も効率よく利益を生み出すエンジンの裏側」を、あなたがこれから習得しようとしているからです。
世界経済を回すインフラを操れるようになること。それは直結して、あなた自身のエンジニアとしての市場価値(単価)を劇的に引き上げることを意味します。
—— 都市伝説と「AWS誕生の真実」
「AWSは、クリスマス商戦のために大量に用意して余ったサーバーを、他社に貸し出したのが始まりだ」
IT業界ではこんな都市伝説がまことしやかに語られますが、実はAmazonの経営陣はこれを明確に否定しています。
AWS誕生の本当の理由は、「社内開発の絶望的な遅れ」でした。
2000年代初頭、Amazon社内では新しいプロジェクトを立ち上げるたびに、エンジニアがゼロからデータベースやネットワークを構築しており、開発スピードが完全に鈍化していました。
「このままではダメだ。インフラ部分を共通の部品(API)として標準化し、誰でもすぐに呼び出せるようにしよう」
この、自社の開発現場の痛みを解決するために作られた社内用システムこそが、AWSの真の原点です。だからこそAWSは、徹底的に「開発者(エンジニア)が使いやすい設計思想」で作られています。
—— エンジニアの「設計思想」を根底から覆した3つのパラダイムシフト
自社の課題解決から生まれたシステムは、結果的に世界のインフラの標準(デファクトスタンダード)となりました。それは、以下の3つの要素で「エンジニアの働き方」の常識を完全に破壊したからです。
✔︎ 【革新1】「所有」から「利用」へ(失敗のコストがゼロに)
かつては数百万のサーバー機器を注文し、納品を何週間も待つ必要がありました。AWSはこれを「数分」に縮めました。これによりエンジニアは、「とりあえず立ち上げて、ダメなら即座に消す」という圧倒的なスピード開発が可能になったのです。
✔︎ 【革新2】「従量課金」によるフェアなルール(インフラの民主化)
電気や水道と同じ「使った分だけ支払う」仕組みです。初期費用がゼロになったことで、名もなき学生のスタートアップ企業でも、資金力のある大企業と全く同じレベルの強力なインフラで勝負できるようになりました。
✔︎ 【革新3】「スケーラビリティ」による伸縮自在(過剰設計からの解放)
アクセスが急増した時だけ処理能力を100倍に増やし、波が去ったら元に戻す。この伸縮性により、エンジニアは「最悪の事態を想定した無駄にハイスペックな設計」を強いられるストレスから完全に解放されました。
私たちは今、物理的なケーブルに一切触れることなく、手元のキーボードから「API化された巨大なインフラのブロック」を意のままに組み合わせています。これこそがAWSのリアルな姿です。
しかし、圧倒的な「自由」を手に入れたということは、そのブロックを使って美しい城を作るか、崩れやすい小屋を作るかは、エンジニアの「頭の中」次第になったということでもあります。
AWSの正体と破壊力がわかったところで、次はいよいよその「人間の頭の中」にメスを入れます。 同じAWSという強力なツールを使っても、なぜエンジニアによって成果に雲泥の差が出るのか? 次回、『「できる人」と「できない人」を分ける、クラウド特有の思考回路』にて、その残酷なまでに明確な違いと解決策に迫ります。
■ AWSはAmazon最大の「稼ぎ頭」 Amazonの営業利益の過半数は、実は通販ではなくAWSが占めている。世界のビジネスを支えるインフラを操れるようになることは、エンジニア自身の市場価値(単価)の劇的な向上に直結する。
■ AWS誕生の真実(都市伝説の否定)
-
誤った噂:「クリスマス商戦で余ったサーバーの貸し出し」という話は経営陣が明確に否定している。
-
真の原点:深刻な「社内開発の遅れ」を解消するため、インフラを誰でもすぐ呼び出せる「共通部品(API)」として標準化したのが始まり。
■ 常識を覆した「3つのパラダイムシフト」
-
所有から利用へ(スピードと挑戦):サーバー調達が数週間から「数分」になり、とりあえず試してダメなら消すというスピード開発が可能になった。
-
従量課金(インフラの民主化):初期費用ゼロで使った分だけ支払う仕組みにより、資金力のないスタートアップでも大企業と同じインフラで勝負できるようになった。
-
スケーラビリティ(過剰設計からの解放):アクセスの波に合わせて処理能力を伸縮できるため、最悪の事態を想定した無駄なハイスペック設計から解放された。
■ 結論
-
自由だからこそ問われる設計力:インフラのブロックを意のままに操れる圧倒的な自由を手に入れた分、どんなシステムになるかはエンジニアの「頭の中」次第である。
同じAWSを使っても、息をするようにシステムを組む人と、エラー画面の前でフリーズする人がいます。その差は知識量ではなく「頭の中の前提」の違い。本節では、クラウドネイティブな思考回路の正体を解き明かします。
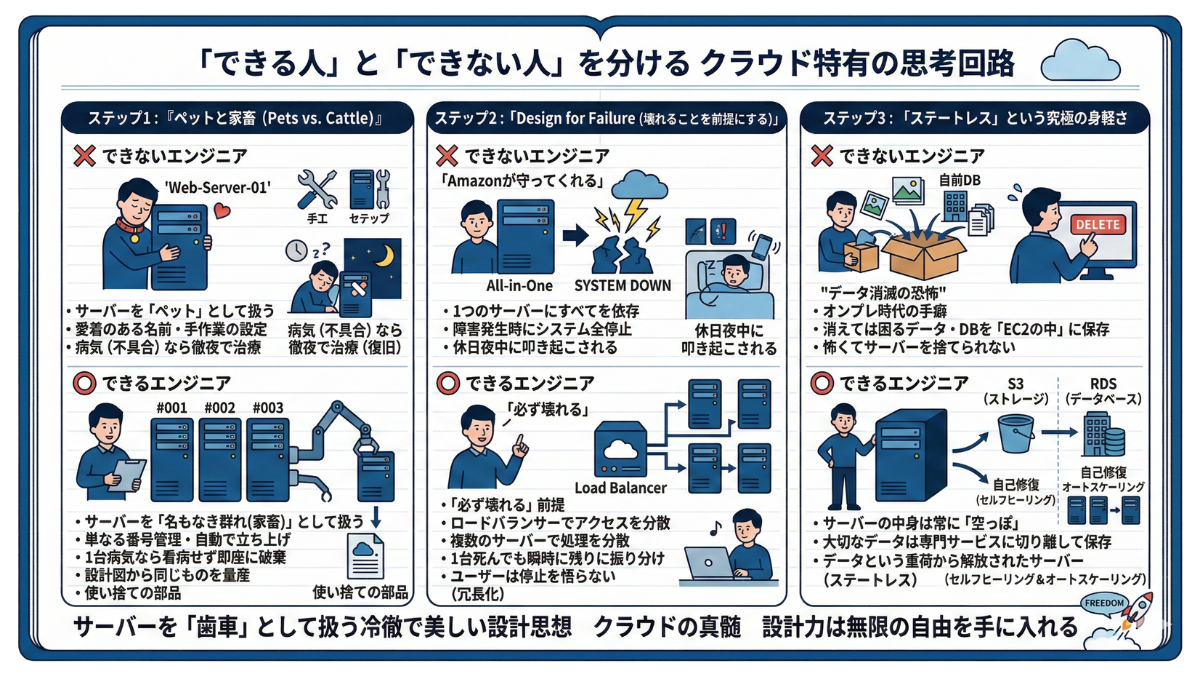
「できる人」と「できない人」を分ける、クラウド特有の思考回路
—— あなたが精魂込めて構築したそのサーバー、もし明日エラーを吐いたら、躊躇なく『捨てる』ことができますか?
AWSのアカウントを作り、入門書を見ながらEC2(仮想サーバー)を立ち上げた。そこまでは誰もがスムーズに到達します。しかし、いざ「実務のシステム」を設計しようとした瞬間、多くの初級者の手が止まってしまいます。なぜでしょうか。
それは、物理的なサーバー機器を扱う時代の常識——いわゆる「オンプレミス脳」のまま、クラウドという異次元の空間でシステムを組もうとしているからです。
「できるエンジニア」が息をするように実践し、「できない人」がいつまでも気づけない、クラウド特有の冷徹で美しい思考回路。それは、以下の3つのステップ(概念)を頭にインストールできているかどうかに懸かっています。
ステップ1:世界標準の法則『ペットと家畜(Pets vs. Cattle)』
クラウドエンジニアの思考回路を語る上で、世界中で最も有名な比喩があります。それが「サーバーをペットとして扱うか、家畜(群れ)として扱うか」という概念です。
❌ 【できないエンジニア】 サーバーを「ペット」のように扱います。「Web-Server-01」などと愛着の湧く名前をつけ、手作業で丁寧に設定を行います。もしそのサーバーが病気(不具合)になれば、原因を徹夜で調査し、なんとか治療(復旧)しようと付きっきりで看病してしまいます。
⭕️ 【できるエンジニア】 サーバーを「名もなき群れ(家畜)」として扱います。単なる番号で管理され、もし1台が病気になれば、絶対に看病などしません。即座にそのサーバーを破棄し、あらかじめ用意しておいた「設計図」から、全く同じ設定の新しいサーバーを自動で立ち上げさせます。
クラウドの世界では、「手塩にかけて育てた唯一無二のサーバー」を作ってはいけません。いつでも、何度でも、ボタン一つで同じものを量産できる「使い捨ての部品」として扱う。これがクラウド思考の第一歩です。
ステップ2:「Design for Failure(壊れることを前提にする)」
物理サーバーの時代、優秀なエンジニアの仕事は「絶対に壊れない頑丈なシステムを作ること」でした。しかし、AWSにおいてその思考は致命的な弱点になります。
AWSの裏側にあるのは、地球上のどこかにある巨大な物理マシンの集合体です。機械である以上、落雷やハードウェアの寿命で「いつか必ず壊れる瞬間」が訪れます。
❌ 【できないエンジニア】 「AWSなんだから、Amazonが絶対に落ちないように守ってくれるはずだ」と信じ込みます。「一度作ればずっと動くはず」という甘い幻想で1つのサーバーにすべてを依存した結果、障害発生時にシステムが全停止し、休日の夜中に叩き起こされることになります。
⭕️ 【できるエンジニア】 「AWSのサーバーも必ず壊れる」という前提(Design for Failure)に立ちます。だからこそ、あらかじめロードバランサー(アクセスの振り分け機)などを使って複数のサーバーに処理を分散させておき、1台が死んでも瞬時に健康な残りのサーバー群へアクセスを振り分け直し、ユーザーには1秒も停止を悟られない設計(冗長化)を最初から組み込むのです。
ステップ3:「ステートレス」という究極の身軽さ
ここまで読んで、鋭い方は一つの疑問を持ったはずです。「エラーが出たサーバーを躊躇なく捨てて(ステップ1)、隣のサーバーに引き継ぐ(ステップ2)なんてことをしたら、保存されていたデータが消えてしまうのではないか?」と。
その通りです。だからこそ、それらを実現するための「絶対条件」となる思考法が存在します。 それが、「ステートレス(状態を持たない)」という設計思想です。
❌ 【できないエンジニア】 オンプレ時代の手癖で、消えては困るユーザーの画像データや、自前でインストールしたデータベースなどを「EC2(サーバー)の中」に保存してしまいます。これでは、サーバーを破棄した瞬間にデータが消滅するため、怖くてサーバーを捨てられなくなります。
⭕️ 【できるエンジニア】 サーバーの中身は常に「空っぽ」にしておきます。大切なデータは、「S3(ストレージ)」や「RDS(データベース)」という、データを預かる専門のサービスに完全に切り離して保存します。
データという重荷から解放されたサーバーは、単に「処理をするだけのエンジン」になります。 データを外に置いているからこそ、サーバーが壊れて別のサーバーに処理が移っても、あるいは新しくサーバーが追加されても、すべてのサーバーが同じ最新データにアクセスでき、何事もなかったかのように処理を継続できるのです。
この「ステートレス」な状態を作れて初めて、クラウド最大の武器が解放されます。それが、寝ている間に勝手にサーバーが入れ替わって復旧する「自己修復(セルフヒーリング)」や、アクセス急増時に自動でサーバーが増える「オートスケーリング」です。
サーバーを「守るべき神殿」ではなく、いつでも交換可能な「歯車」として扱う。この冷徹で美しい設計思想こそがクラウドの真髄です。オンプレミス時代の「壊さないための執着」を捨て去った時、あなたの設計力は初めて無限の自由を手に入れます。
クラウドの思考回路が書き換わった今、あなたには新しい知識を吸収する準備が完全に整いました。 しかし、AWSの200以上のサービス群を前に、何から手をつけるべきか?次回、『マニュアルを読む前に知っておくべき、学習の優先順位』にて、あなたが「今」絶対に学ぶべきコアサービスと、後回しでいいものを仕分けしていきましょう。
「オンプレミス脳(物理サーバー時代の常識)」を捨て、クラウドネイティブな設計を行うための3つの重要な思考法。
-
① サーバーは「ペット」ではなく「家畜(群れ)」として扱う
-
❌ 愛着を持って手作業で復旧(看病)させる。
-
⭕️ 壊れたら即座に破棄し、自動で新しいサーバーと交換する「使い捨ての部品」として扱う。
-
-
② Design for Failure(壊れることを前提にする)
-
❌ 「AWSは壊れないはずだ」と1つのサーバーに依存する。
-
⭕️ 機械は必ず壊れる前提に立ち、ロードバランサー等で処理を分散させ、1台が死んでもシステムを止めない設計(冗長化)にする。
-
-
③ 「ステートレス(状態を持たない)」という究極の身軽さ
-
❌ サーバー内に大切なデータ(画像やDB)を保存してしまう。
-
⭕️ サーバーの中身は常に「空っぽ」にし、データはS3やRDSなど外部の専門サービスに完全に切り離して保存する。
-
最大のメリット: データを外に出すことで、自動でサーバーが復旧する「自己修復(セルフヒーリング)」や、負荷に応じて増減する「オートスケーリング」が可能になる。
-
■ 結論 サーバーは「守るべき神殿」ではなく、いつでも交換可能な「歯車」。壊さないための執着を捨て去ることで、初めてクラウドの無限の自由と圧倒的な自動運用が手に入る。
AWSには200以上のサービスが存在します。すべてを暗記しようとするのは、辞書の「あ」から順に読むようなもの。本節では、初心者が絶対に迷子にならないための「捨てる勇気」と「正しい学習の順番」を解説します。
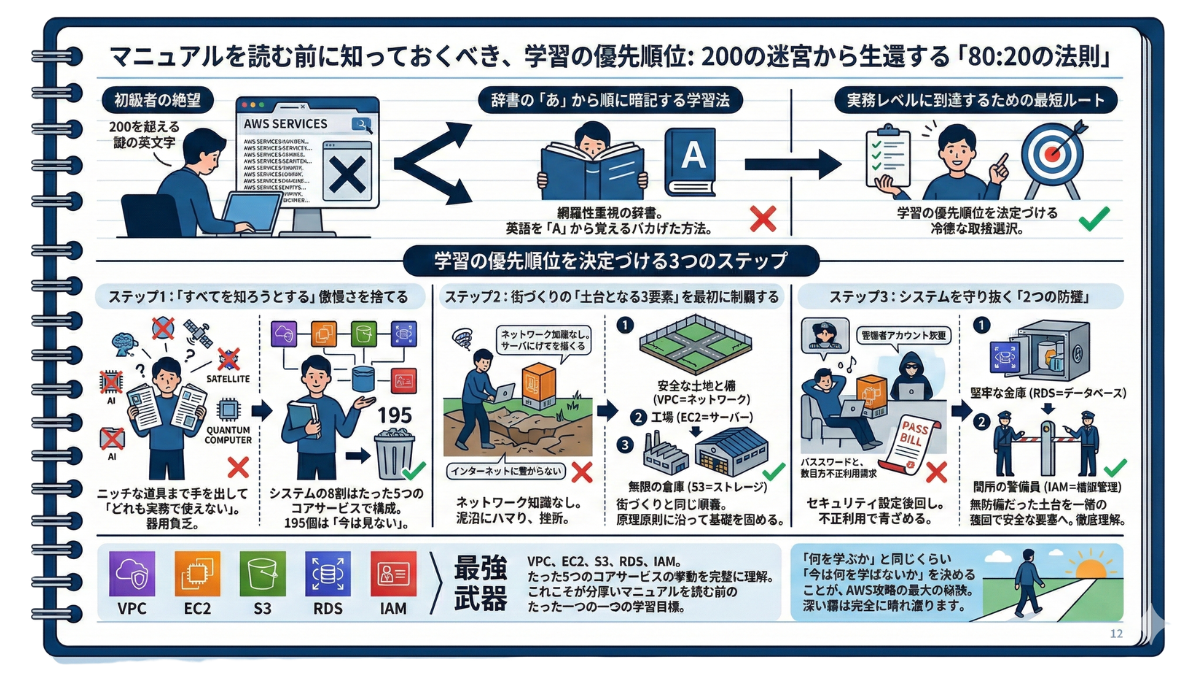
マニュアルを読む前に知っておくべき、学習の優先順位:200の迷宮から生還する「80:20の法則」
—— AWSの全サービス一覧を見た瞬間、そっとブラウザのタブを閉じた経験はありませんか? おめでとうございます。その『絶望』こそが、正しい学習のスタートラインです。
AWSのマネジメントコンソール(管理画面)を開き、サービス一覧のプルダウンをクリックする。そこにズラリと並ぶ200を超える謎の英文字の羅列を見た瞬間、初級者の心はへし折られます。
「これを全部覚えないと、エンジニアになれないのか……」
結論から言います。その必要は全くありません。
AWSの公式マニュアルは、網羅性を重視した「分厚い辞書」です。英語を学ぶ時に、辞書の「A」のページから順番に暗記していくバカげた学習法をとる人はいませんよね。
最短で「実務レベル」に到達するためには、何を学ぶかと同じくらい、「今は何を学ばないか」を決める冷徹な取捨選択が必要です。ここでは、学習の優先順位を決定づける3つのステップを紹介します。
ステップ1:「すべてを知ろうとする」傲慢さを捨てる
AWSには人工知能、人工衛星のデータ処理、量子コンピューティングなど、魔法のような最新サービスが山のようにあります。しかし、これらは「一部の専門家」に向けたニッチな道具です。
❌ 【できないエンジニア】 分厚いマニュアルを端から読み込み、最新のAIサービスやマイナーな機能まで手を出してしまい、結局「どれも実務で使えない」という器用貧乏に陥ります。
⭕️ 【できるエンジニア】 世の中のシステムの8割は「たった5つ程度の基本サービス」だけで構成されているという事実を知っています。だからこそ、まずは基本となるコアサービスだけに一点集中し、それ以外の195個のサービスを「今は絶対に見ない」と完全に切り捨てるのです。
ステップ2:街づくりの「土台となる3要素」を最初に制覇する
では、その絶対に学ぶべき「コアサービス」とは何か?それは、現実世界で街づくりをする順番と同じ「土台」となる3つの要素です。
❌ 【できないエンジニア】 入門書の手順に従い、いきなり「サーバー(EC2)」を立ち上げようとします。しかし、ネットワークの知識がないため、「なぜかインターネットに繋がらない」という通信エラーの泥沼にハマり、挫折します。
⭕️ 【できるエンジニア】 まずはシステムを配置するための「安全な土地と柵(VPC=ネットワーク)」を作ります。その安全な土地の上に「工場(EC2=サーバー)」を建て、隣に「無限の倉庫(S3=ストレージ)」を併設するという、原理原則に沿った順番で基礎を固めるのです。
ステップ3:システムを守り抜く「2つの防壁」
土台(VPC、EC2、S3)を理解したら、いよいよそれらを「安全なビジネスの場」として完成させます。ここで絶対に後回しにしてはいけないのが、システムを守る2つの防壁です。
❌ 【できないエンジニア】 サーバーが動いただけで満足してしまい、セキュリティ設定を後回しにします。「とりあえず管理者アカウント(ルートユーザー)でいいや」と放置した結果、パスワードが漏洩し、翌月に数百万円の不正利用の請求書が届いて青ざめることになります。
⭕️ 【できるエンジニア】 顧客の命であるデータを安全に保管する「堅牢な金庫(RDS=データベース)」と、誰がどこに入って良いかを厳格に審査する「関所の警備員(IAM=権限管理)」の仕組みを徹底的に理解します。これらを駆使して、無防備だった土台を「一つの強固で安全な要塞」として完成させるのです。
VPC、EC2、S3、RDS、IAM。この「たった5つのコアサービス」の挙動を完璧に理解すること。これこそが、分厚いマニュアルを読む前にあなたが設定すべき、たった一つの学習目標です。
「何を学ぶか」と同じくらい「今は何を学ばないか」を決めることが、AWS攻略の最大の秘訣です。不要な情報を削ぎ落とし、この5つのコアサービスという「最強の武器」を手にした時、あなたの目の前にあった深い霧は完全に晴れ渡ります。
学習すべき「5つのパーツ」は明確になりました。しかし、部品を一つひとつ眺めているだけでは、システムは動きません。次回、『【第1章】AWSの「地図」を手に入れる:5つのコアサービスとインフラの全体像』にて、これら5つのコアサービスが実務の現場で「どう美しく連動して動くのか」、その感動的な全体像をお見せします。
-
「何を学ばないか」を決めるのが最短ルート
-
200以上のサービスを順番に暗記するのは非効率。「分厚い辞書」を通読するような無駄を省く。
-
-
ステップ1:「5つのコアサービス」に一点集中する
-
世の中のシステムの8割は基本サービスで構成されている。AIなどのニッチな最新機能は一旦完全に切り捨てる。
-
-
ステップ2:街づくりの順番で「3つの土台」を固める
-
通信エラーで挫折しないよう、インフラの原理原則に沿って構築する。
-
VPC(ネットワーク): システムを置く「安全な土地と柵」
-
EC2(サーバー): 土地の上に建てる「工場」
-
S3(ストレージ): 隣に併設する「無限の倉庫」
-
-
-
ステップ3:システムを守り抜く「2つの防壁」を設置する
-
後回しにすると高額請求などの大事故に繋がるため、必ず最初に理解する。
-
RDS(データベース): 顧客のデータを守る「堅牢な金庫」
-
IAM(権限管理): 誰が入れるかを審査する「関所の警備員」
-
-
-
結論
-
マニュアルを読む前に設定すべき目標は、「VPC、EC2、S3、RDS、IAM」の5つを完璧に理解すること。不要な情報を削ぎ落とすことがAWS攻略の最大の秘訣である。
-
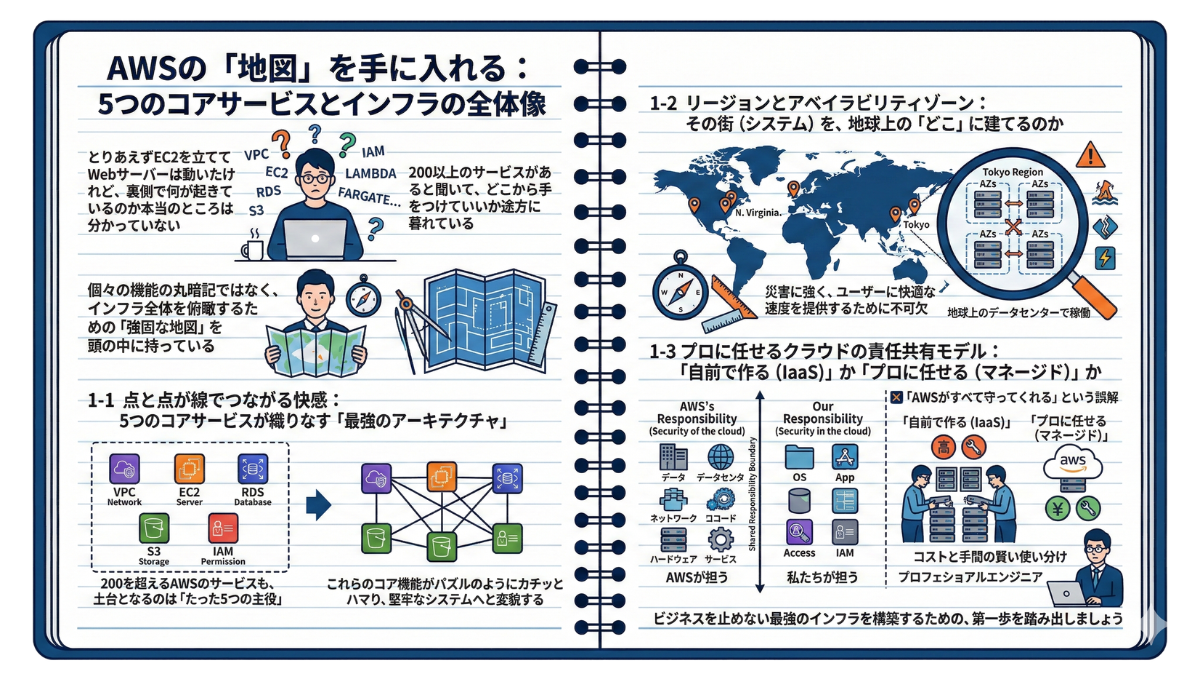
【第1章】AWSの「地図」を手に入れる:5つのコアサービスとインフラの全体像
広大な密林(Amazon)に、コンパスひとつ持たずに丸腰で放り込まれたような途方もなさ。初めてAWSの管理画面(マネジメントコンソール)を開き、アルファベット3文字の謎のサービス群がズラリと並んでいるのを目の当たりにした日のことを、あなたは今でも覚えているでしょうか。
「とりあえずネットの記事通りにEC2を立ててWebサーバーは動いたけれど、裏側で何が起きているのか本当のところは分かっていない」「200以上のサービスがあると聞いて、どこから手をつけていいか途方に暮れている」
もしあなたが今、そんな「クラウドの迷子」になりかけているとしたら、どうか安心してください。それは、AWSに挑むすべての人が必ず通る通過儀礼です。第一線で活躍するプロのインフラエンジニアであっても、膨大なAWSの全サービスを辞書のように完璧に暗記しているわけではありません。彼らが圧倒的なスピードで最適なシステムを設計できるのは、個々の機能の丸暗記ではなく、インフラ全体を俯瞰するための「強固な地図」を頭の中に持っているからです。
本章は、あなたにその「地図」を手渡すための章です。
暗闇の中で手探りをするような、場当たり的な学習はここで終わりにしましょう。ネットワーク、サーバー、データベースといった各要素がどう絡み合っているのか。クラウドという広大な世界に散らばる「点」が「線」としてつながり、バラバラだった知識が、理にかなった美しいアーキテクチャへと変貌していく瞬間の快感を、ぜひ本章で味わってください。
【本章で学ぶ3つのステップ】
1-1 点と点が線でつながる快感:5つのコアサービスが織りなす「最強のアーキテクチャ」
200を超えるAWSのサービスも、インフラの土台となるのは「たった5つの主役(VPC・EC2・RDS・S3・IAM)」です。これらのコア機能がパズルのようにカチッとハマり、堅牢なシステムへと変貌する「点と線」の全体像を紐解きます。
1-2 リージョンとアベイラビリティゾーン:その街(システム)を、地球上の「どこ」に建てるのか
クラウドとはいえ、物理的なサーバーは地球上のどこかのデータセンターで稼働しています。災害に強く、ユーザーに快適な速度を提供するために不可欠な「リージョン」と「AZ」の概念。世界地図を広げる感覚で、プロの立地戦略を学びましょう。
1-3 プロに任せるクラウドの責任共有モデル:「自前で作る(IaaS)」か「プロに任せる(マネージド)」か
クラウド最大の罠は「AWSがすべて守ってくれる」という誤解です。AWSと私たちが担うセキュリティ境界線「責任共有モデル」の鉄則を解説。その上で、どこまで自前で構築し(IaaS)、どこから運用をプロに丸投げするのか(マネージド)、コストと手間の賢い使い分けに迫ります。
ビジネスを止めない最強のインフラを構築するための、第一歩を踏み出しましょう。
200以上のAWSサービスに圧倒されていませんか?実は、たった5つのコアサービス(VPC, EC2, RDS, S3, IAM)の役割とつながりを理解するだけで、インフラの強固な土台は完成します。本記事で、点と線がつながる全体像を掴みましょう。
1-1 点と点が線でつながる快感:5つのコアサービスが織りなす「最強のアーキテクチャ」
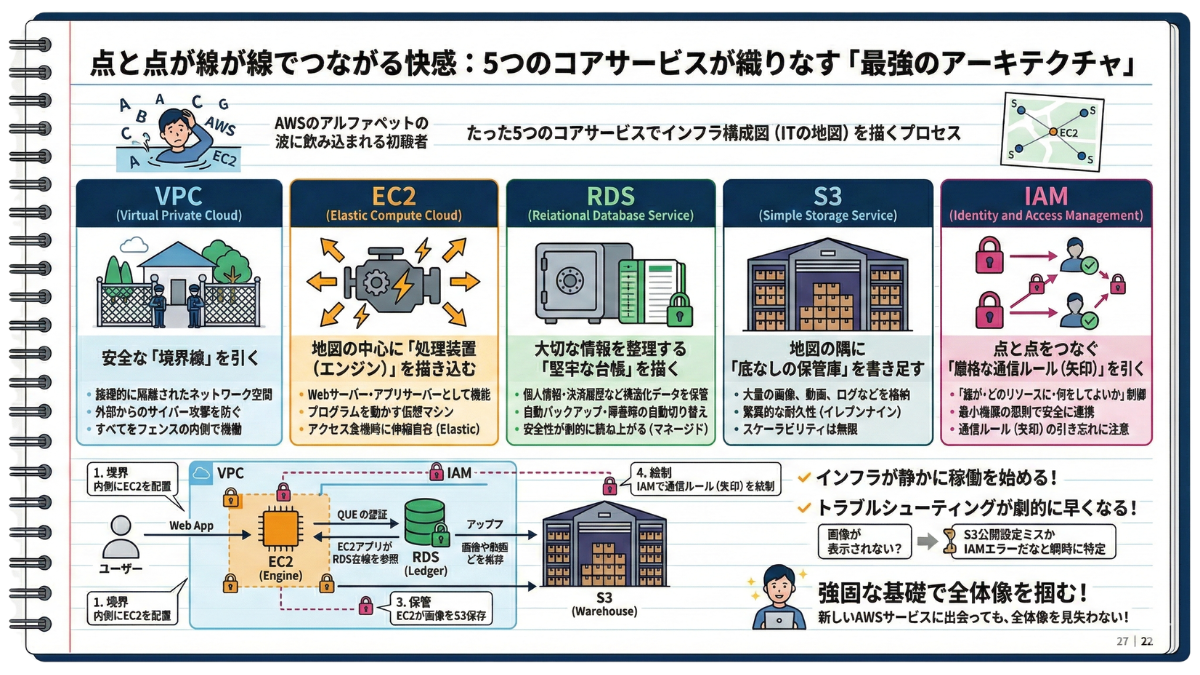
—— 「AWSをマスターしよう!」と意気込んで公式ドキュメントを開き、押し寄せるアルファベット3文字の波に飲み込まれて、そっとブラウザを閉じた経験は、あなただけのものではありません。でも、実は覚えるべき「主役」は、片手で数えられるほどしかないのです。
AWSには現在、AIから衛星通信まで200を超える多種多様なサービスが存在します。しかし、Webアプリケーションや企業の社内システムなど、一般的なビジネスインフラの8割以上は、「たった5つのコアサービス」の組み合わせで描かれています。
あなたの手元にあるノートの真っ白なページに、この5つの主役をどう配置し、どう連携させるか。それぞれの役割を「インフラ構成図(ITの地図)を描くプロセス」として理解した瞬間、目の前の霧は晴れ、理にかなった美しい設計図が姿を現します。
1. VPC:地図上に安全な「境界線」を引く
インフラ構築の第一歩は、ノートに枠線を引くことです。 VPC(Virtual Private Cloud)は、広大なAWS上にあなた専用の「論理的に隔離されたネットワーク空間」を作成します。この明確な境界線があるからこそ、外部からのサイバー攻撃を防ぎ、すべてのシステムを安全なフェンスの内側で稼働させることができます。
2. EC2:地図の中心に「処理装置(エンジン)」を描き込む
安全な枠線を引いたら、そこにプログラムを動かすサーバー(仮想マシン)のシンボルを描き込みます。それがEC2(Elastic Compute Cloud)です。Webサーバーやアプリサーバーとして機能するシステムの中核であり、最大の魅力は「Elastic(伸縮自在)」であること。アクセス急増時には数分でサーバーの台数やスペックを拡張し、波が去れば縮小できる可変エンジンです。
3. RDS:大切な情報を整理する「堅牢な台帳」を描く
ユーザーの個人情報や決済履歴など、絶対に失ってはいけない「行と列で整理されたデータ」を保管するのがRDS(Relational Database Service)です。EC2内に自前でデータベースを立てることも可能ですが、プロはRDSを選びます。自動バックアップや障害時の自動切り替え(フェイルオーバー)など、面倒な保守作業をAWS側に「お任せ(マネージド)」でき、運用の安全性が劇的に跳ね上がるからです。
4. S3:地図の隅に「底なしの保管庫」を書き足す
データベース(RDS)には適さない、大量の画像、動画、ログなどを格納するのがS3(Simple Storage Service)です。スケーラビリティは事実上無限。「99.999999999%(イレブンナイン)」という驚異的な耐久性を誇り、1万個のファイルを保存して1つ失われるのに1000万年かかる計算です。EC2で生成された重いファイルは、すかさずこのS3に逃がすのがアーキテクチャの鉄則です。
5. IAM:点と点をつなぐ「厳格な通信ルール(矢印)」を引く
これら4つのサービスを配置したあと、それらを安全につなぎ合わせるのがIAM(Identity and Access Management)です。IAMは「誰が・どのリソースに・何をしてよいか」を細かく制御します。「EC2上のアプリは、S3の画像を読み取ってよいか?」。このIAMによる『最小権限の原則』の矢印をノートに引くことで、各サービス間の連携が初めて安全なものになります。
■ 点が線になり、インフラが静かに稼働を始める
では、あなたのノートの上に描かれた5つの「点」を、線で結んでみましょう。
【1. 境界】 VPCという安全な枠線の内側に、ユーザーのアクセスを受け止めるEC2を配置する。
【2. 処理】 EC2上で動くアプリケーションが、ユーザー認証を行うためにRDS(データベース)の台帳を参照する。
【3. 保管】 ユーザーが画像をアップロードしたら、EC2は即座にそれをS3(底なしの保管庫)へ保存し、サーバーの負荷を逃がす。
【4. 統制】 この一連のデータリレーにおける「アクセスの許可(通信の矢印)」は、すべてIAMによって厳密に定義・管理されている。
バラバラだったアルファベットの羅列が見事に連携し、ノート上の地図が静かに稼働し始めました。
この「インフラの地図」が頭に入っていることの最大のメリットは、トラブルシューティング(障害原因の特定)が劇的に早くなることです。「画像が表示されない?ならばS3の公開設定(バケットポリシー)のミスか、あるいはIAMの権限エラー(矢印の引き忘れ)だな」と、瞬時にアタリをつけられるようになります。
これが、頭の中に強固なアーキテクチャを描いている最大の理由です。
5つの主役が織りなす連携の美しさをイメージできたでしょうか。この強固な基礎さえノートに刻まれていれば、今後新しいAWSサービスに出会っても、全体像を見失うことはありません。あなたはもう、クラウドの迷子ではないのです。
次回は『1-2 リージョンとアベイラビリティゾーン:その街(システム)を、地球上の「どこ」に建てるのか』について解説します。今回設計した美しいアーキテクチャを、地球上のどこに配置し、どうやって災害から守るのか。プロフェッショナルな「立地戦略」の極意に迫ります。
AWSインフラを支える「5つのコアサービス」と全体像 ■ 基礎となる考え方 AWSには200以上のサービスがあるが、一般的なビジネスインフラの8割は「5つのコアサービス」で構成されている。 これらを「ノートに描くインフラの地図(構成図)」として理解することで、システムの全体像が明確になる。 ■ 5つの主役とその役割 VPC(境界線): システムを外部の攻撃から守る、安全で隔離されたネットワーク空間。 EC2(処理装置): プログラムを動かすサーバー。アクセス増減に合わせて柔軟に拡張・縮小(Elastic)が可能。 RDS(堅牢な台帳): 顧客情報などを守るデータベース。バックアップなどの保守運用をAWSにお任せできる。 S3(保管庫): 画像やログを保存する、事実上容量が無制限のストレージ。99.999999999%(イレブンナイン)の極めて高い耐久性を持つ。 IAM(通信ルール): 「誰が・どのリソースに・何をしてよいか」を細かく制御する権限管理。 ■ アーキテクチャの連携と最大のメリット 連携の流れ: 「VPC」内に「EC2」を配置し、EC2上で動くアプリが「RDS」を参照しながら処理を行い、重いデータは「S3」へ保存する。これらの通信許可をすべて「IAM」が管理することでシステムが稼働する。 最大のメリット: この全体像(地図)を頭に入れていると、エラー発生時の原因特定(トラブルシューティング)が劇的に早くなる。
クラウドは「雲の中」にある魔法ではありません。物理的なサーバーは地球上のどこかで稼働しています。本記事では、システムを災害から守り、ユーザーに快適な速度を提供するためのプロの立地戦略「リージョン」と「AZ」の極意を解説します。
1-2 リージョンとアベイラビリティゾーン:その街(システム)を、地球上の「どこ」に建てるのか
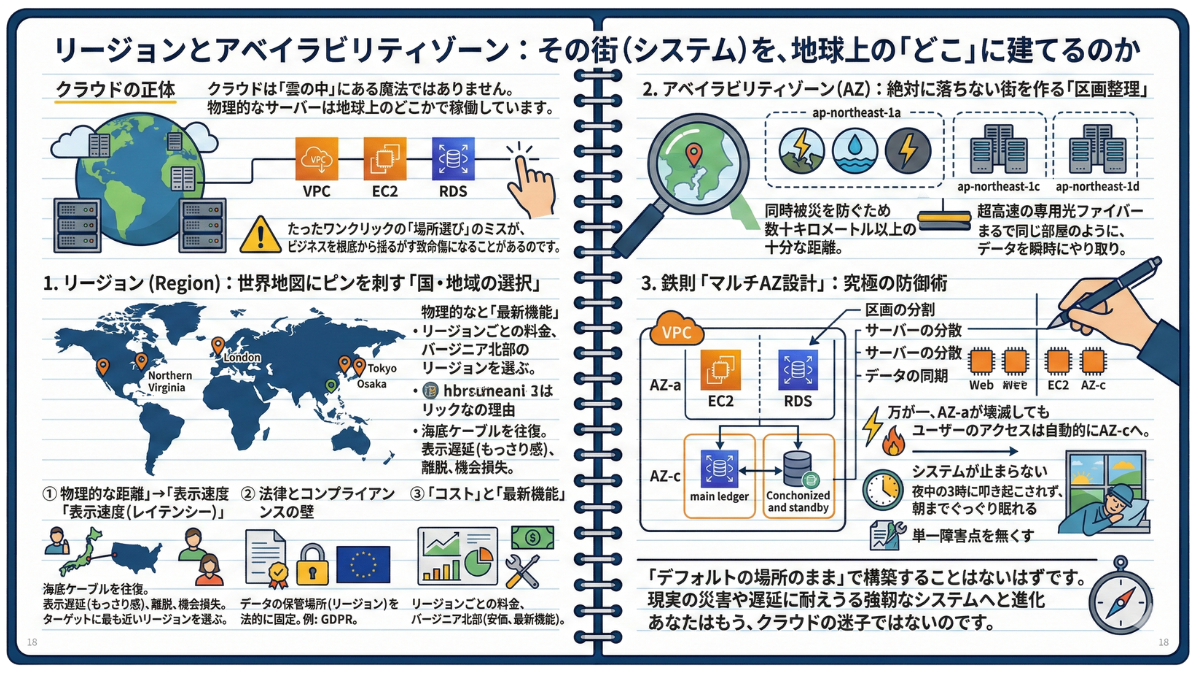
—— 「クラウドなんだから、サーバーの場所なんて世界中どこでもいいんでしょ?」もしあなたがそう思っているなら、今すぐその考えを捨ててください。たったワンクリックの「場所選び」のミスが、ビジネスを根底から揺るがす致命傷になることがあるのです。
「クラウド(雲)」という美しいネーミングは、私たちにある種の錯覚を抱かせます。データが空に浮かんでいるようなイメージです。
しかし、その実態は非常に泥臭く、物理的です。あなたがAWSの管理画面からクリック一つで立ち上げたEC2サーバーも、RDSのデータベースも、地球上のどこかにある「巨大な要塞のようなデータセンター」のラックに収められた、物理的な機械の上で動いています。
前回の記事で、私たちは手元のノートに、VPCやEC2を使った「美しいインフラ構成図」を描きました。本章では、その描いた地図を「地球上のどこに配置するのか」という、極めて重要な地理的戦略について解説します。
1. リージョン(Region):世界地図にピンを刺す「国・地域の選択」
AWSを始める際、一番最初に迫られる選択が「リージョン(Region)」の決定です。東京、大阪、バージニア北部、ロンドンなど、AWSは世界中にデータセンターの拠点を展開しています。この大きな地理的なくくりのことをリージョンと呼びます。
「とりあえずデフォルトでいいか」と適当に選んではいけません。プロのエンジニアは、以下の3つの明確な理由を持ってリージョンを選択します。
-
① 物理的な距離は「表示速度(レイテンシー)」に直結する
光の速度には限界があります。ターゲット層が日本のユーザーなのに、アメリカのリージョンを選んでしまうと、データは太平洋の海底ケーブルを往復することになります。このわずかな表示遅延(もっさり感)は、ユーザーの離脱率を跳ね上げ、ビジネスの機会損失に直結します。ターゲットに最も近いリージョンを選ぶのが鉄則です。 -
② 法律とコンプライアンスの壁
データは、保存されている国の法律に従います。例えば、ヨーロッパの顧客データを扱う場合、厳格なプライバシー保護法(GDPR)により「データをEU圏外に持ち出してはならない」といったケースがあります。扱う情報によっては、保管場所(リージョン)を法的に固定しなければならないのです。 -
③ リージョンによって「コスト」と「最新機能」が違う
実は、リージョンごとに土地代や電気代が異なるため、AWSの利用料金も異なります。一般的にアメリカのバージニア北部リージョンは安価で、最新のAWSサービスがいち早くリリースされるという特徴があります。
2. アベイラビリティゾーン(AZ):絶対に落ちない街を作る「区画整理」
リージョンを選んだら、次はそのリージョンの中にある「アベイラビリティゾーン(AZ)」を選びます。ここが、AWSの堅牢性を支える最大のキモです。
1つのリージョン(例:東京リージョン)は、1つの巨大なデータセンターで構成されているわけではありません。独立した複数のデータセンター群(AZ)が集まって、1つのリージョンを形成しています。東京リージョンの中には、「ap-northeast-1a」「ap-northeast-1c」「ap-northeast-1d」といった複数のAZが存在します。
各AZは、数十キロメートル以上の十分な距離を保って物理的に分離されています。なぜ離しているのでしょうか?それは、「同時被災を防ぐため」です。もし地震、水害、大規模な停電が発生し、1つのAZが完全に壊滅したとしても、数十キロ離れた別のAZは生き残るように設計されています。それでいて、各AZ間は超高速の専用光ファイバーで結ばれており、システム側からは「まるで同じ部屋にあるかのように」データを瞬時にやり取りできます。
3. 鉄則「マルチAZ設計」:究極の防御術
ここまでの知識が点と線でつながると、クラウドインフラにおける「最強の防御術」が導き出されます。それが「マルチAZ(Multi-AZ)設計」です。
あなたのノートの上に描かれた設計図に、少し手を加えてみましょう。ペンを使って、フラットでスッキリとした直線を書き足していくイメージです。プロのインフラエンジニアは、重要なシステムを決して1つのAZの中だけで完結させません。
-
【1. 区画の分割】 ノートに描いたVPC(境界線)の中に、中心で線を引いて「AZ-a」と「AZ-c」という2つの独立した区画を用意する。
-
【2. サーバーの分散】 Webサーバー(EC2)のシンボルを、両方のAZに1台ずつ分けて描き込む。
-
【3. データの同期】 データベース(RDS)も、メインの台帳をAZ-aに置き、常にリアルタイムで同期される予備(スタンバイ)をAZ-cに描き足す。
この地図通りに設計しておけば、万が一、深夜に落雷や火災でAZ-aのデータセンターが完全に沈黙しても、ユーザーのアクセスは自動的に生き残っているAZ-cへと振り分けられます。
つまり、システムが止まらないだけでなく、「あなたは夜中の3時に叩き起こされて、青ざめながら復旧作業をしなくても済む(朝までぐっすり眠れる)」ということです。
「単一障害点(そこが壊れたらシステム全体が止まる場所)を無くす」。これこそが、リージョンとAZの概念を理解した者がたどり着く、プロフェッショナルな立地戦略の正体です。
「どこに建てるか」という地理的な視点を持つことで、あなたのノートに描かれたインフラ構成図は机上の空論から、現実の災害や遅延に耐えうる強靭なシステムへと進化しました。もう「デフォルトの場所のまま」で構築することはないはずです。
次回は『1-3 プロに任せるクラウドの責任共有モデル:「自前で作る(IaaS)」か「プロに任せる(マネージド)」か』について解説します。クラウド最大の罠である「セキュリティの境界線」を見極め、運用を劇的に楽にするプロの賢い手抜き術を学びましょう。
クラウドインフラの立地戦略:「リージョン」と「AZ」の全体像 ■ クラウドの実態と「場所選び」の重要性 クラウドも実態は物理サーバーであり、「どこに配置するか」という地理的戦略のミスは、ビジネスに致命的な影響を与える。 ■ リージョン(国・地域の選択) 定義: 東京やバージニア北部など、データセンターの拠点となる大きな地理的エリア。 選定の3基準: ① 表示速度(レイテンシー): ターゲットユーザーから物理的に近い場所を選び、離脱率の悪化を防ぐ。 ② 法律・コンプライアンス: GDPRなど、扱うデータを保管する国の法律を遵守する。 ③ コストと最新機能: リージョンごとに異なる利用料金や、新機能のリリース時期を考慮する。 ■ アベイラビリティゾーン / AZ(独立した区画) 定義: 1つのリージョン内にある、数十キロメートル離れて独立した複数のデータセンター群。 役割: 地震や大規模停電による「同時被災」を防ぎつつ、各AZ間を超高速通信でつなぎ、堅牢なシステム基盤を作る。 ■ 鉄則「マルチAZ設計」 仕組み: システムを1つのAZに依存させず、複数のAZにサーバー(EC2)を分散し、データベース(RDS)の予備をリアルタイムで同期する設計。 最大のメリット: 「単一障害点(そこが壊れるとすべてが止まる弱点)」がなくなる。災害時でもシステムが自動継続するため、エンジニアが深夜の緊急対応から解放される。
「AWSが全部守ってくれる」という誤解は、時に致命的な情報漏洩を招きます。本記事では、クラウド最大の鉄則である「責任共有モデル」と、運用を劇的に楽にするマネージドサービスの賢い使い分けを解説します。
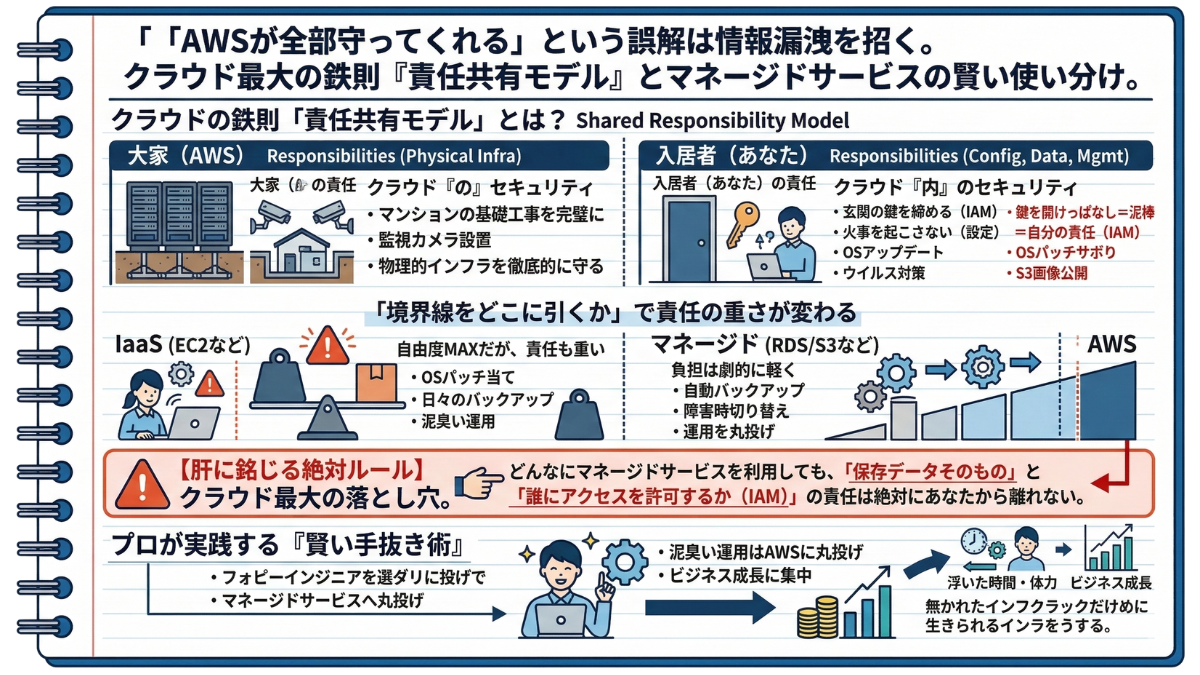
1-3 プロに任せるクラウドの責任共有モデル:「自前で作る(IaaS)」か「プロに任せる(マネージド)」か(RDS/S3)」か
—— クラウドに移行すれば、面倒なサーバー管理やセキュリティ対策からすべて解放される。もし心のどこかでそう信じているなら、今すぐその幻想を打ち砕いてください。その甘い期待こそが、世界中で起きているクラウド情報漏洩事故の最大の引き金なのですから。
これまでの記事で、私たちは手元のノートにVPCやEC2を配置し、災害に強いインフラの「地図」(システム図)を描き上げました。
しかし、ここで一つ極めて現実的な問いが生まれます。「この地図上のシステムがサイバー攻撃を受けたとき、あるいはデータが消えたとき、一体『誰』が責任を取るのでしょうか?」
AWSの根幹を成す、この最も重要なルールを「責任共有モデル(Shared Responsibility Model)」と呼びます。
1. クラウドの鉄則「責任共有モデル」とは?
AWSは、セキュリティに関して非常に明確な境界線を引いています。それは「クラウド『の』セキュリティ」と「クラウド『内』のセキュリティ」という境界線です。
マンションの賃貸契約をイメージしてください。
-
【大家(AWS)の責任】 マンションの基礎工事を完璧に行い、監視カメラを設置し、地震で建物が倒壊しないよう「物理的なインフラ」を徹底的に守る。
-
【入居者(あなた)の責任】 自分が借りた部屋の「玄関の鍵」をしっかり締め、部屋の中で火事を起こさないように管理する。
もしあなたが「玄関の鍵を開けっぱなしにして泥棒に入られた(=IAMの権限設定ミス)」としたら、それは大家の責任ではなく、あなたの責任です。OSのアップデートをサボってウイルスに感染したり、設定ミスでS3の極秘画像が全世界に公開されてしまった場合、それはAWSの責任ではなく「私たちの責任」として処罰の対象となります。
2. 「境界線をどこに引くか」で責任の重さが変わる この「責任の範囲」を理解すると、ノートにシステムを描き込む際の「選び方」が劇的に変わります。私たちが利用できるAWSサービスは、大きく2種類に分けられます。
-
① 自由度MAXだが、責任も重い「IaaS(EC2など)」 EC2は、まっさらな土地と建物(仮想サーバー)だけを貸してくれる形態です。好きなOSやソフトを入れられる「究極の自由」がありますが、その代わり、OSのセキュリティパッチ当てや日々のバックアップといった泥臭い運用責任はすべて「あなた」にのしかかります。
-
② 自由度は下がるが、運用を丸投げできる「マネージド(RDS / S3など)」 一方、RDS(データベース)などは、AWS側が運用まで巻き取ってくれる形態です。OSの深いカスタマイズはできませんが、毎日の自動バックアップや障害時の予備サーバーへの切り替えを、AWSの優秀なシステムが裏側で勝手にやってくれます。
つまり、マネージドサービスを使えば使うほど、ノート上の「責任の境界線」はAWS側に押しやられ、私たちの運用負担は劇的に軽くなるのです。
【※現役のエンジニア(プロ)が肝に銘じる絶対ルール】 ただし、一つだけ絶対に忘れてはいけないルールがあります。どんなにマネージドサービスを利用して運用をAWSに丸投げしても、「そこに保存されるデータそのもの」と「誰にアクセスを許可するか(IAMの設定)」の責任だけは、絶対にあなたから離れることはありません。ここがクラウド最大の落とし穴です。
3. 「賢い手抜き術」 クラウドインフラを設計する上で、プロのエンジニアは「マネージドサービスへの丸投げ(賢い手抜き)」を徹底します。
EC2の中に自前でデータベースを構築すること(IaaSの利用)は簡単です。しかし、それをやってしまうと、あなたは毎日のバックアップ確認に追われ、休日に冷や汗をかきながらデータベースのアップデート作業をするハメになります。それは「ビジネスの利益を1円も生み出さない作業」です。
プロは地図を描くとき、こう考えます。「自分たちで守りきれない泥臭い運用は、迷わずAWSにお金を払って任せよう。浮いた時間と体力で、自社のビジネスを成長させることに集中しよう」と。
クラウドの真の価値は、ただサーバーが画面上に作れることではありません。責任の境界線を見極め、マネージドサービスを巧みに使いこなして「自分たちの運用負荷を限界まで減らすこと」にこそ、真の価値が隠されているのです。
AWSとの「責任の境界線」を正しく引くこと。そして、任せられる運用はマネージドに丸投げすること。この賢い手抜きこそが、疲弊しないインフラ運用の極意です。これで第1章、クラウドの全体像を描く「地図」は無事に完成しました。
次回からは『【第2章】安全な「秘密基地」を設営する:VPCとネットワークの真髄』へと突入します。今回ノートに描いた「境界線(VPC)」の中に、誰にも破られない最強のプライベート空間をどう構築するのか。ネットワークのディープな世界へご案内します。
クラウドの「責任共有モデル」と賢いサービス選択 ■ クラウドの絶対ルール「責任共有モデル」 クラウド「の」セキュリティ(AWSの責任): データセンターなどの物理的なインフラ基盤を守る(例:マンションの基礎やオートロックの維持)。 クラウド「内」のセキュリティ(ユーザーの責任): OSの更新やアクセス権限の管理(例:自室の鍵締めや火の用心)。設定ミスによる情報漏洩は完全にユーザーの自己責任となる。 ■ サービスの選択で変わる「責任の境界線」 IaaS(EC2など): 自由度は高いが、パッチ当てやバックアップなど泥臭い運用責任がすべてユーザーにのしかかる。 マネージドサービス(RDSやS3など): カスタマイズの自由度は下がるが、日々の保守運用や障害対応をAWSに丸投げでき、運用負担が劇的に下がる。 ■ 【重要】「絶対ルール」 どれだけマネージドサービスを利用しても、「保存するデータそのもの」と「アクセス権限(IAMの設定)」の管理責任だけは、絶対にユーザーから離れることはない。 ■ 「賢い手抜き術」 利益を生まない泥臭いインフラ運用は、迷わずマネージドサービス(AWS)にお金を払って任せる。 浮いた時間と体力を「自社ビジネスの成長」に集中させることこそが、疲弊しないインフラ運用の極意。
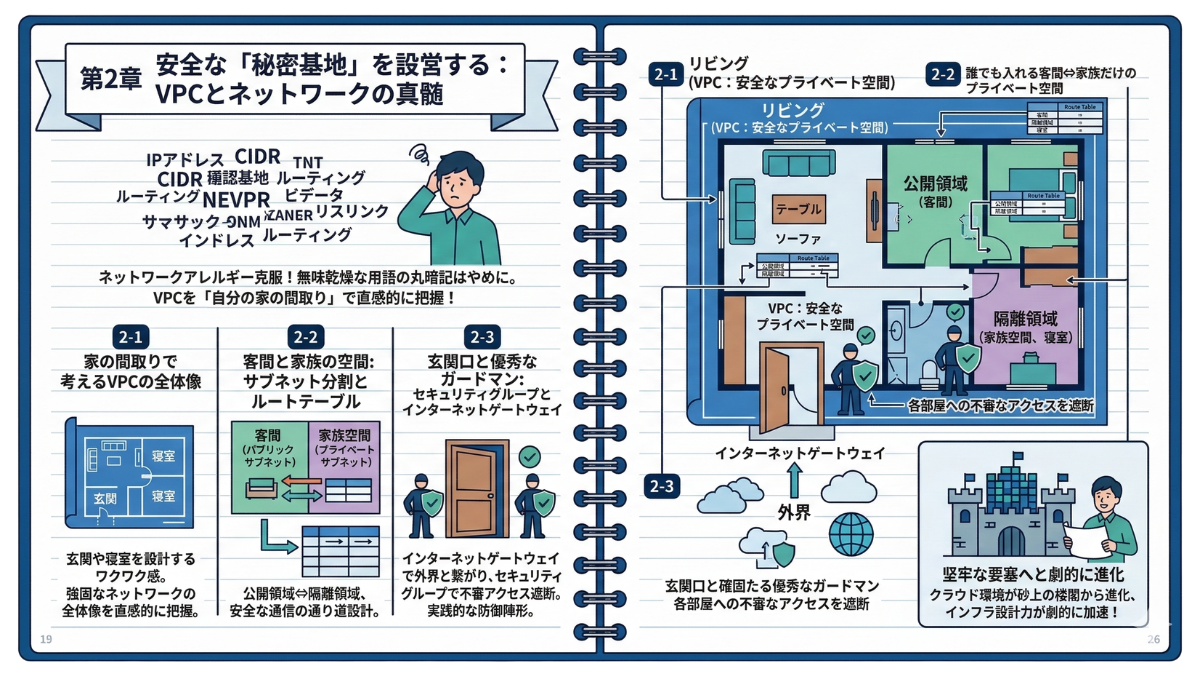
【第2章】安全な「秘密基地」を設営する:VPCとネットワークの真髄
誰もが一度は心躍らせた「自分だけの秘密基地」づくり。しかし、壁も扉もない野ざらしの空き地に大切な宝物を置くことがどれほど危険か、想像に難くないでしょう。
クラウドの世界へ足を踏み入れた多くの人が、最初にぶつかる高く険しい壁。それが「ネットワーク」です。IPアドレス、CIDR、ルーティング……。呪文のような専門用語の羅列を前に、「自分にはまだ早かったかもしれない」とそっとブラウザを閉じてしまいたくなる気持ちは、痛いほどよく分かります。
しかし、そこで立ち止まる必要はありません。その戸惑いこそが、すべてのエンジニアが必ず一度は通る「ネットワークアレルギー」の初期症状なのですから。
第2章で解説するAWSの「VPC(Virtual Private Cloud)」は、そのアレルギーを乗り越え、クラウドという広大な土地に「安全なプライベート空間」を構築するための、最も重要な基礎工事となります。
サーバーという大切な家具を配置する前に、まずは外敵から守る頑丈な外壁を作り、用途に合わせて部屋を区切り、適切な鍵をかける。どんなに最新で高性能なサーバーを用意しても、この「ネットワークという土台」が脆弱であれば、あなたのシステムは砂上の楼閣に過ぎません。
だからこそ本章では、無味乾燥なIT用語の丸暗記は一切やめにします。難解なネットワーク理論を、誰もが直感的にイメージできる「家の間取り」に完全置換し、実運用に耐えうるインフラ設計の真髄をお伝えします。
本章の学習ロードマップ
2-1 ネットワークアレルギーを克服する:VPCを「自分の家の間取り」で考える ネットワーク用語にアレルギーを起こしていませんか?本節では難解なVPCの概念を「家の間取り」に完全置換。玄関や寝室を設計するワクワクする感覚で、強固なクラウドネットワークの全体像を直感的に把握します。
2-2 パブリックとプライベートの境界線:サブネット分割とルートテーブルの役割 誰でも入れる客間と、家族だけのプライベート空間。この境界線をクラウド上に引くのが「サブネット」と「ルートテーブル」です。公開領域と隔離領域を適切に切り分け、迷子の出ない安全な通信の通り道を設計します。
2-3 最強の門番と出入り口:セキュリティグループとインターネットゲートウェイ 外部との安全な通信には、確固たる玄関口と優秀なガードマンが不可欠です。「インターネットゲートウェイ」で外界と正しく繋がり、「セキュリティグループ」で各部屋への不審なアクセスを遮断する、実践的な防御陣形を敷きます。
ネットワークの知識は、一朝一夕では身につきません。しかし、この「間取り」の概念さえ一度腹落ちしてしまえば、あなたのインフラ設計力は劇的に進化し、どんな複雑なシステム構成図を見ても迷うことはなくります。クラウド環境は単なる「お試しの実験場」から、外部の脅威を一切寄せ付けない「堅牢な要塞」へと劇的に進化するはずです。
ネットワーク構築は決して難しくありません!本記事では、AWSの土台となる「VPC」と難解な設定用語を「家の間取り」に完全翻訳。専門用語の壁を越え、あなただけの安全なクラウド環境を設計する第一歩を、一緒にノートへ書き留めていきましょう。
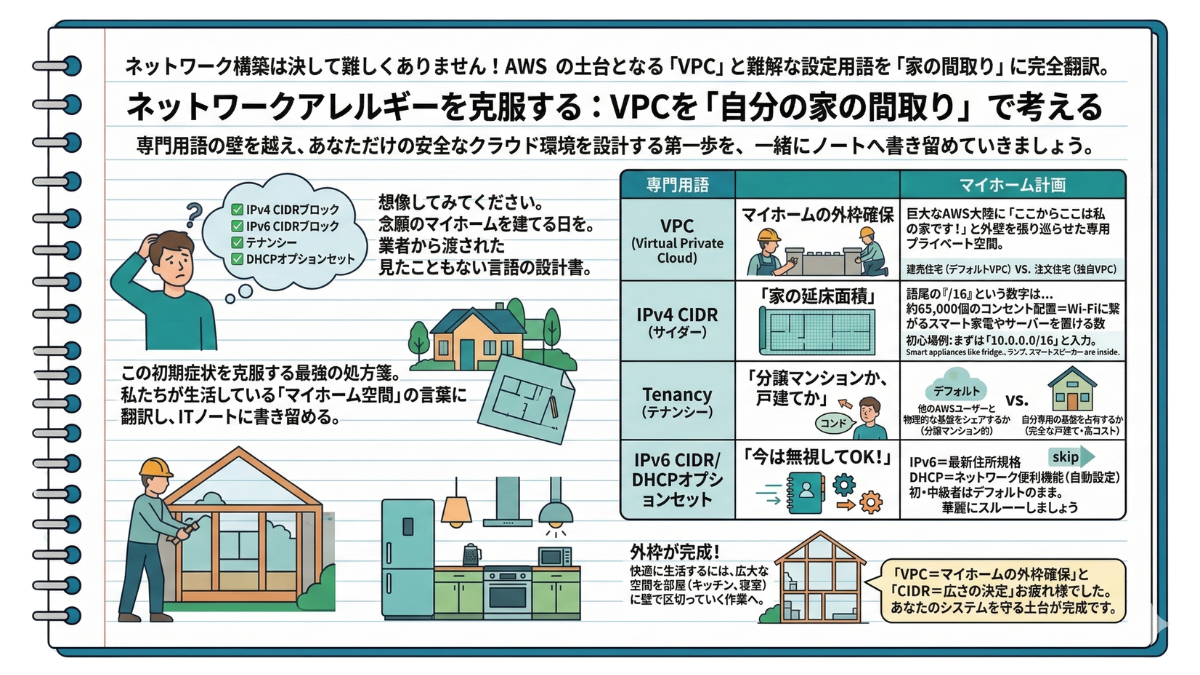
2-1 ネットワークアレルギーを克服する:VPCを「自分の家の間取り」で考える
—— あなたが念願のマイホームを建てる日を。しかし、業者から渡されたのは、見たこともない言語で書かれた分厚い設計書でした。今、AWSの構築画面を前にしたあなたの戸惑いは、まさにそれと同じです。
なぜ、私たちはネットワーク画面でフリーズするのか?
AWSのマネジメントコンソールを開き、「VPCを作成」ボタンを押した瞬間。多くの人がそっと息を呑みます。画面に並ぶのは、以下のような言葉たちです。
✅ IPv4 CIDRブロック
✅ IPv6 CIDRブロック
✅ テナンシー
✅ DHCPオプションセット
まるで暗号のような専門用語の羅列。「自分にはITの才能がない」とブラウザを閉じたくなりますよね。しかし、人間の脳は「目に見えないもの」を理解するのが苦手なだけ。雲を掴むようなクラウドルーティングに、アレルギー反応が出るのは当然のことなのです。
この初期症状を克服する最強の処方箋。それは、IT用語の丸暗記をやめ、私たちが普段生活している「マイホーム空間」の言葉に翻訳し、あなた専用のITノートに書き留めていくことです。
—— 専門用語を「マイホーム計画」に翻訳する
前章でお伝えした通り、VPC(Virtual Private Cloud)とは、巨大なAWSという大陸に「ここからここは私の家です!」と強固な外壁を張り巡らせた、あなた専用のプライベート空間です。
実はAWSには、最初からすぐに使える「建売住宅(デフォルトVPC)」が用意されています。しかし、これは利便性を優先した「誰でもアクセスしやすい開放的な間取り」になりがちです。外部の脅威から大切なデータを守る「安全な秘密基地」を作るには、ネットワークの基礎を理解し、一から「注文住宅(独自VPC)」を設計するスキルがどうしても必要になります。
では、注文住宅の設計画面に並ぶ忌まわしい用語たちは、何を意味しているのでしょうか?翻訳を書き込んでいきましょう。
【翻訳1】IPv4 CIDR(サイダー) ➡ 「家の延床面積」
VPCを作成する際、必ず入力させられる謎の数字。これは、「あなたが建てる家の広さ」です。
語尾の「/16」という数字は、「この家には約65,000個のコンセント(=Wi-Fiに繋がるスマート家電やサーバーを置ける数)を配置できますよ」という、とてつもなく巨大な大豪邸レベルの広さを指定しているに過ぎません。個人の学習やブログ構築の用途であれば、まずは「10.0.0.0/16」と入力しておけば問題ありません。
【翻訳2】テナンシー ➡ 「分譲マンションか、戸建てか」
デフォルト(Default)のままで問題ありません。これは「他のAWSユーザーと物理的な基盤をシェアするか(分譲マンション的)、自分専用の基盤を占有するか(完全な戸建て・高コスト)」を選んでいるだけです。
【翻訳3】IPv6 CIDR / DHCPオプションセット ➡ 「今は無視してOK!」
「IPv6」は最新の住所規格、「DHCP〜」はネットワークの便利機能(自動設定)のこと。しかし、初・中級者のマイホーム構築において、これらは「デフォルトのまま(または設定なし)」で全く問題ありません。今はまだ使わないオプション設備として、華麗にスルーしましょう。
—— 外枠が完成したら、次はどうする?
ここまでの設定で、外部の脅威を寄せ付けない強固な外壁(VPC)と、その面積(CIDR)が確定しました。AWSにおけるネットワーク構築の第一歩は、これだけで完了です。難しく考える必要はありません。
しかし、外壁と床だけの巨大な空間に、ベッドや冷蔵庫を野ざらしで置くわけにはいきませんよね。快適に生活するには、この広大な空間を「用途」に合わせて、壁で区切っていく必要があります。
「VPC=マイホームの外枠確保」と「CIDR=広さの決定」、お疲れ様でした。これであなたのシステムを守る絶対的な土台が完成です。次はこの空間の中に、キッチンや寝室といった「部屋」を、間取り図のように美しく配置していく作業に入ります。
次回、『2-2 パブリックとプライベートの境界線:サブネット分割とルートテーブルの役割』へ続きます。誰でもアクセスできる「客間」と、大切なデータを隠す「秘密の寝室」。AWS上でこの境界線をどう引くのか、安全で美しい間取り設計の極意を解説します。お楽しみに!
■ ネットワーク理解の基本スタンス 暗記はやめて「間取り」で考える: 難解なIT用語は、直感的にイメージできる「マイホームの空間設計」に置き換えて理解する。 「注文住宅」を建てるスキルが必須: 初めからある「建売住宅(デフォルトVPC)」は便利だが開放的すぎるため、安全な環境を作るにはゼロから「注文住宅(独自VPC)」の土台を設計する必要がある。 ■ AWS設定用語の「マイホーム」翻訳 VPC: 巨大なAWS上に作る「自分専用のプライベート空間(強固な外壁)」。 IPv4 CIDR(サイダー): 「建てる家の広さ」。学習やブログ構築の用途なら、迷わず大豪邸レベルの広さである「10.0.0.0/16」を入力すればOK。 テナンシー: 「基盤をシェアするか(分譲)、独占するか(戸建て)」。デフォルトのままでOK。 IPv6 / DHCPオプション: 「今は使わないオプション設備」。デフォルトのままで華麗にスルー(無視)してOK。 ■ 現状の進捗と次のステップ ここまでの設定で、外部の脅威からシステムを守る「絶対的な外枠」が完成。 次は、この外壁だけの広大な空間を、用途に合わせて「部屋」に区切っていく作業(サブネット分割)へと進む。
外壁だけの大空間に、用途に応じた「部屋」を作りましょう!本節ではAWSの「サブネット」と「ルートテーブル」を解説。誰でも入れる客間と、家族だけの秘密の寝室。その境界線を美しく引く設計の極意に迫ります。
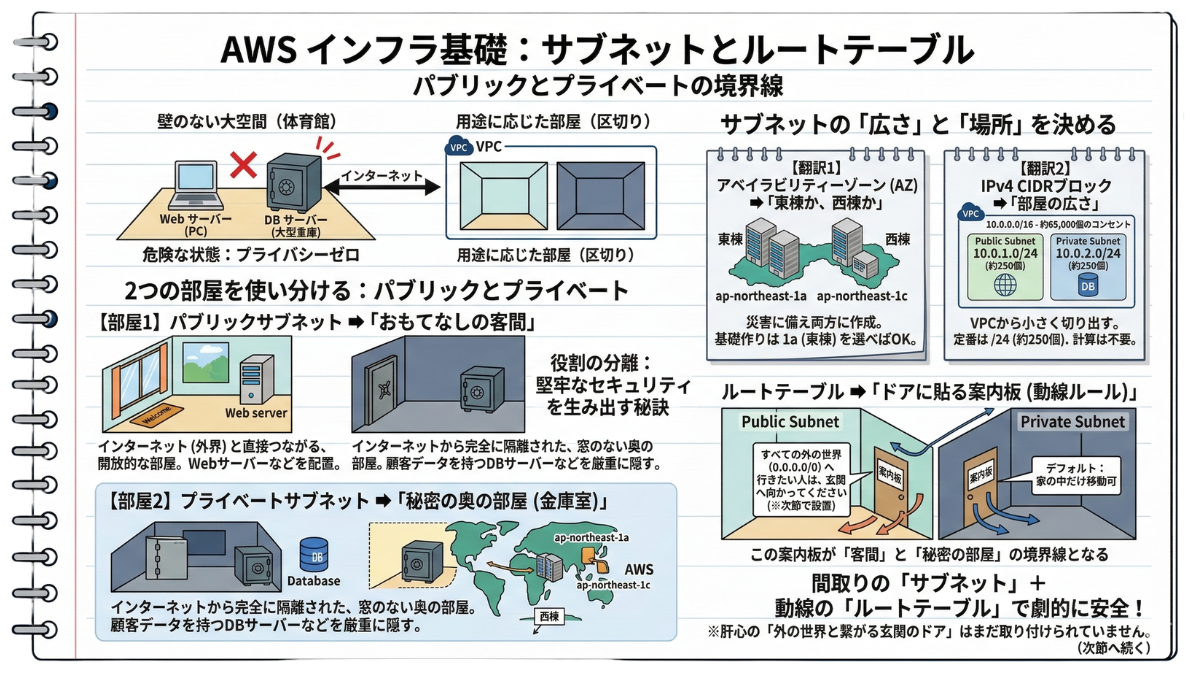
2-2 パブリックとプライベートの境界線:サブネット分割とルートテーブルの役割
—— 玄関の扉を開けると、そこはトイレもベッドも金庫もすべてが野ざらしに置かれた、壁のない体育館のような家。あなたはそんなプライバシーゼロの空間で、安心して眠りにつくことができるでしょうか?
なぜ、わざわざ空間を区切る必要があるのか?
前節では、AWS上に巨大な外壁(VPC)を構築し、外部からの脅威を遮断しました。 しかし、システムというものは「ただ隔離すればいい」わけではありません。
ブログやWebサービスを公開するには、世界中のユーザー(お客さま)を迎え入れる必要があります。 一方で、顧客情報やパスワードが詰まったデータベース(金庫)は、絶対に外部の目に触れさせてはなりません。
もし、この2つを「壁のない大空間」に並べて置いてしまったらどうなるでしょう? Webサイトを見に来たお客さまが、ちょっと横を向いただけで大切な金庫の中身まで丸見えになってしまいます。
この致命的なリスクを防ぐため、広大なVPCの内部に「壁」を作り、用途に合わせて「部屋」を分割する作業が必要になります。 これが「サブネット(Subnet)」の役割です。
—— 2つの部屋を使い分ける:パブリックとプライベート
AWSのインフラ設計において、作るべき部屋(サブネット)は大きく分けて2種類しかありません。 あなたの「ITノート」に、この2つの違いを明確に書き留めておきましょう。
✅ 【部屋1】パブリックサブネット ➡ 「おもてなしの客間」 インターネット(外界)と直接つながる、開放的な部屋です。お客さまを迎え入れるための「Webサーバー」などは、必ずこの部屋に配置します。
✅ 【部屋2】プライベートサブネット ➡ 「秘密の奥の部屋(金庫室)」 インターネットから完全に隔離された、窓のない奥の部屋です。絶対に流出してはならない顧客データを持つ「データベース(DB)サーバー」などは、この部屋に厳重に隠します。
客間(Web)で受けた注文だけを、奥の部屋(DB)にいる家族にこっそり伝達する。この「役割の分離」こそが、堅牢なセキュリティを生み出す最大の秘訣なのです。
—— サブネットの「広さ」と「場所」を決める
実際にAWSの画面で部屋(サブネット)を作る際、あなたは以下の「2つのこと」を問われます。ここもITノートに翻訳しておきましょう。
【翻訳1】アベイラビリティーゾーン(AZ) ➡ 「東棟か、西棟か」
AWSの大陸は、災害で家が全壊しないよう、物理的に離れた複数のデータセンター(棟)に分かれています。画面で「ap-northeast-1a」や「1c」といった選択肢が出ますが、これは「広大な敷地の東棟(1a)に部屋を作るか、西棟(1c)に作るか」を選んでいるだけです。 実務では万が一の災害に備えて両方の棟に部屋を作りますが、最初の基礎作りとしては、まず「1a(東棟)」を1つ選んでおけば間違いありません。
【翻訳2】IPv4 CIDRブロック ➡ 「部屋の広さ」
前節でVPC全体の広さを「10.0.0.0/16(約65,000個のコンセント)」という大豪邸サイズで確保しました。1つの部屋(サブネット)は、そこから小さく切り出します。
✅ 客間(パブリック)の広さ: 10.0.1.0/24
✅ 奥の部屋(プライベート)の広さ: 10.0.2.0/24
計算式を丸暗記する必要はありません。「サブネットの広さは『/24(約250個のコンセント)』で作るのが定番」とだけメモしておけば、まずは完璧です。
—— ルートテーブル ➡ 「ドアに貼る案内板(動線ルール)」
さて、壁を作って部屋の広さと場所を決めました。しかし、これだけではまだシステムは動きません。 「どの部屋から、どこへ向かって歩いていいのか」という動線のルールが決まっていないからです。
それを決定づけるのが「ルートテーブル(Route Table)」です。 ルートテーブルとは、各部屋のドアの裏に貼られた「案内板」だと考えてください。
AWSでは、部屋を作った直後、デフォルトで「家の中(VPC内)しか移動してはいけません」という案内板が全部屋に貼られています。つまり、最初は全部屋がプライベートサブネットなのです。
ここから特定の部屋を「パブリック(客間)」に変えるには、外への道順を書いた「新しい案内板」を作り、客間のドアに貼り替えてあげる(関連付ける)必要があります。
✅ パブリック用の案内板: 「すべての外の世界(0.0.0.0/0)へ行きたい人は、玄関(※次節で設置します)へ向かってください」と書き加えたものを新しく作って貼る。
✅ プライベート用の案内板: 最初からある「家の中だけ移動可」という案内板をそのままにしておく。
この「外への道順が書かれた案内板が貼られているかどうか」というたった一つの違いが、客間と秘密の部屋を決定づける絶対的な境界線となるのです。
間取りを区切る「サブネット」と、動線を決める「ルートテーブル」。この2つを制したことで、あなたのシステムは劇的に安全になりました。しかし、今の案内板には「玄関へ向かえ」と書いてあるのに、肝心の「外の世界と繋がる玄関のドア」自体がまだ家に取り付けられていません。
次節では、『2-3 最強の門番と出入り口:セキュリティグループとインターネットゲートウェイ』へ続きます。 完成した部屋に外界と繋がる「玄関口」を設置し、各部屋のドアに不審者を絶対にシャットアウトする「最強のガードマン」を配置します。
■ サブネットの役割(空間の分割) 目的: 広大なVPC(家)に壁を作り、用途に合わせて「部屋」を分けること。 理由: 外部に見せる「Webサーバー」と、隠すべき「データベース(金庫)」を分離し、情報漏洩の致命的なリスクを防ぐため。 ■ 2種類の部屋(パブリックとプライベート) ✅ パブリックサブネット(客間): インターネットと直接繋がる開放的な部屋。Webサーバーを配置する。 ✅ プライベートサブネット(奥の部屋/金庫室): インターネットから完全に隔離された部屋。データベース(DB)を厳重に隠す。 ■ サブネット作成時の2つの設定 AZ(アベイラビリティーゾーン): 部屋を配置する「場所(東棟か西棟か)」。最初の基礎作りは「1a」を選べばOK。 IPv4 CIDR: 部屋の「広さ」。計算式は暗記せず、定番サイズの「/24」(例:10.0.1.0/24)で切り出すと覚えておく。 ■ ルートテーブルの役割(動線のルール) 目的: 各部屋のドアに貼る「案内板」。どの部屋からどこへ移動して良いかを決める。 パブリックとプライベートの境界線: デフォルトはすべて「家の中だけ移動可(プライベート)」。 「外の世界(
0.0.0.0/0)への道順」を書き加えた新しい案内板を作成し、特定の部屋に貼り替える(関連付ける)ことで、その部屋が「パブリック(客間)」へと変わる。
家は完成したのに外に出られない?本節では、外界と繋がる「インターネットゲートウェイ」と、不審者を完全にシャットアウトする最強の門番「セキュリティグループ」を解説。あなただけのクラウド要塞、堂々の完成です!
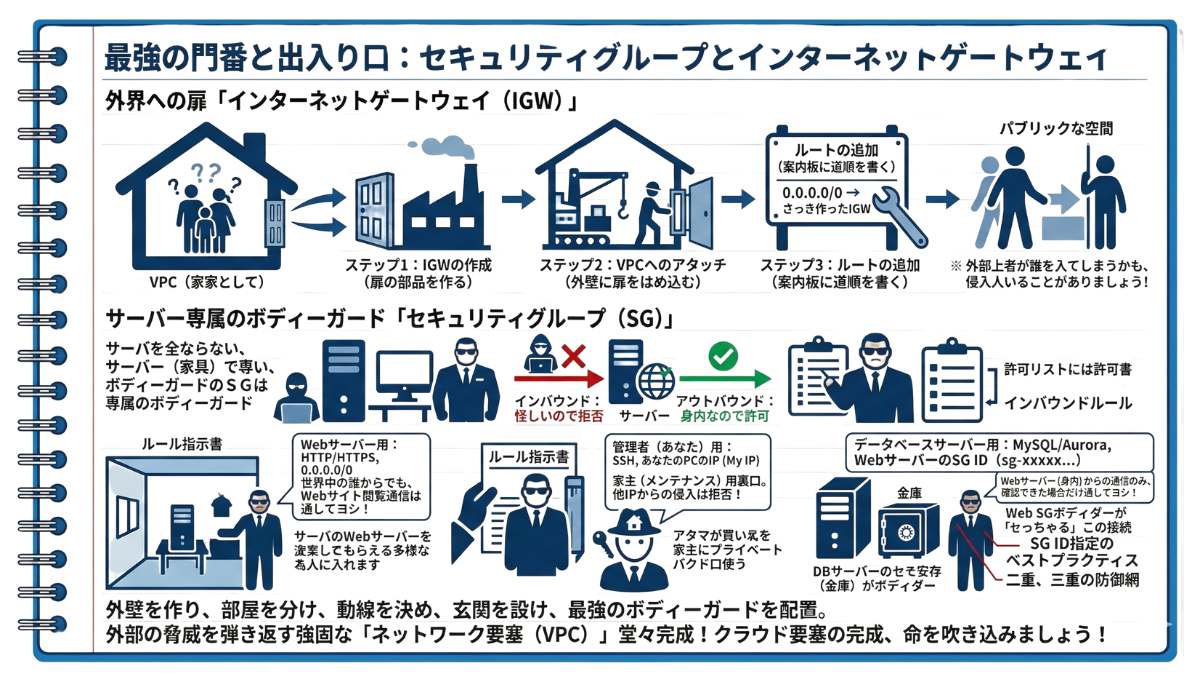
2-3 最強の門番と出入り口:セキュリティグループとインターネットゲートウェイ
—— 「外の世界へ向かえ」という案内板に従って廊下を進んだ先。そこにあったのは、冷たくそびえ立つコンクリートの壁でした。そう、私たちが丹精込めて造り上げたこの堅牢な家には、肝心の「玄関の扉」がまだ存在していなかったのです。
案内板の先にある外界への扉「インターネットゲートウェイ」。
前節で、客間(パブリックサブネット)のドアに「外の世界(0.0.0.0/0)へ行きたい人は、玄関へ向かえ」という新しい案内板(ルートテーブル)を貼り付けました。
しかし、AWSの初期状態では、外壁(VPC)に穴は一切空いていません。このままでは、お客さまが遊びに来ることも、中から外へ出かけることも不可能です。そこで、この分厚い外壁に大穴を開け、外界(インターネット)と安全に繋がるための立派な「玄関の扉」を設置します。これが「インターネットゲートウェイ(IGW)」です。
AWSでは、IGW(玄関)を作っただけではネットに繋がらず、VPCへの取り付けと、ルートテーブル(案内板)の書き換えという「3点セット」を必ず自力で行う必要があります。具体的なAWS画面での操作は、以下の3ステップになります。あなたの「ITノート」にしっかり書き留めておきましょう。
-
✅ ステップ1:IGWの作成(扉の部品を作る)
AWS画面の「インターネットゲートウェイ」メニューから、「インターネットゲートウェイの作成」ボタンを押します。この時点では、まだ壁に取り付けられていない「玄関の扉という部品」がポツンと出来上がっただけの状態です。 -
✅ ステップ2:VPCへのアタッチ(外壁に扉をはめ込む)
作成したIGWを選択し、「VPCにアタッチ(取り付ける)」という操作を行います。ここで自分のVPC(外壁)を指定することで、初めて壁に大穴が開き、扉がガチャンとはめ込まれます。 -
✅ ステップ3:ルートの追加(案内板に道順を書く)
ここが初心者が一番忘れやすいポイントです。客間(パブリックサブネット)に紐づいている「ルートテーブル」の編集画面を開きます。送信先に「0.0.0.0/0(すべての外界)」、ターゲットに「さっき作ったIGW」を指定して保存します。これで「外に行きたい人は玄関(IGW)へ向かえ」という道順が案内板に書き込まれ、ようやく通信が外へ抜けられるようになります。
この3つが揃って初めて、世界中のお客さまがあなたの客間へアクセスできる、本当の意味での「パブリックな空間」が誕生します。
—— 玄関が開いた!…でも、誰でも入り放題でいいの?
無事に玄関が開き、インターネットとの道が繋がりました。しかし、ここで新たな恐怖が生まれます。「玄関が開いているということは、悪意を持ったハッカーやウイルスも自由に入ってこられるのでは?」という当然の不安です。
ご安心ください。AWSには、サーバーを守るための最強のボディーガードが用意されています。それが「セキュリティグループ(Security Group)」です。
—— サーバー専属のボディーガード「セキュリティグループ」
多くの初級者が誤解しがちですが、セキュリティグループは「家全体(VPC)の門番」や「部屋のドアの鍵」ではありません。これから部屋の中に配置する「サーバー(家具)の真横にピタリと立つ、専属のボディーガード」です。
このボディーガードは極めて優秀ですが、融通が利きません。初期設定では以下のような極端なルールで動いています。
外からの訪問者(インバウンド): 怪しいので一切合切すべて拒否。
サーバー自身の外出(アウトバウンド): 身内なのでどこへでも自由に許可。
そのため、私たちが「こういうお客さまだけは通してあげてね」という許可リスト(インバウンドルール)を渡してあげる必要があります。(※ちなみに、一度入室を許可したお客さまに対する「返事・帰り道」は、ボディーガードが顔を覚えて自動で通してくれます。これを専門用語で「ステートフル」と呼びます)
—— ボディーガードへの具体的な指示書
実務において、ボディーガードに渡す許可リストは用途によって明確に分けます。AWSの画面設定(タイプとソース)と一緒に翻訳しておきましょう。
✅ Webサーバー(客間の家具)用の指示書
【タイプ】 HTTP(ポート80) / HTTPS(ポート443)
【ソース】 0.0.0.0/0【翻訳】 「世界中の誰からでも、Webサイトを見るための通信だけは通してヨシ!」
✅ 管理者(あなた)が設定作業をするための指示書(裏口)
【タイプ】 SSH(ポート22)など
【ソース】 あなたのPCのIPアドレス(My IP)【翻訳】 「家主である自分がメンテナンスに入る時だけは、この専用の裏口を通せ!他のIPアドレスからの侵入は絶対に許すな!」
✅ データベースサーバー(奥の部屋の金庫)用の指示書
【タイプ】 MySQL/Aurora(ポート3306)など
【ソース】 WebサーバーのセキュリティグループID(sg-xxxxx…)【翻訳】 「IPアドレスは偽装されるから信用しない!客間にいる『Webサーバー(身内)』からの通信であることを、ボディーガード同士で確認できた場合だけ通してヨシ!」
このように、ソース(通信元)にIPアドレスではなく「別のボディーガード(SGのID)」を指定する手法を、AWSのベストプラクティスと呼びます。部屋の壁(パブリック/プライベート)で守るだけでなく、サーバー自身にも強固なボディーガードを立たせる。この二重、三重の防御網こそが、クラウド要塞の真骨頂なのです。
外壁を作り、部屋を分け、動線を決め、玄関を設け、最強のボディーガードを配置する。本当にお疲れ様でした!これにて、外部の脅威を弾き返す強固な「ネットワーク要塞(VPC)」が堂々完成です。さあ、いよいよこの安全な空間に、システムという名の命を吹き込んでいきましょう!
次回、『【第3章】「動くもの」に命を吹き込む:EC2とストレージの黄金比』 へ続きます。美しく完成した部屋の中に、いよいよシステムの中核となるサーバー(EC2)を設置します。用途に合わせた最適なスペックの選び方と、大切なデータを守るストレージの極意を解説します。お楽しみに!
■ インターネットゲートウェイ(IGW):外界と繋がる「玄関の扉」 役割: VPC内のシステムがインターネットと通信するための出入り口。 開通のための必須3ステップ(※手順3を忘れずに!): 作成: IGWの部品(扉)を作る。 アタッチ: 作成したIGWをVPC(外壁)に取り付ける。 ルートの追加: 客間のルートテーブル(案内板)に、「外( ■ セキュリティグループ(SG):サーバー専属の「ボディーガード」 役割: 家や部屋全体ではなく、各サーバー(家具)の真横に立って通信を監視する門番。 初期設定の極端なルール: インバウンド(入室): すべて拒否(※私たちが「許可リスト」を渡す必要がある)。 アウトバウンド(外出): すべて許可。 ステートフル: 一度入室を許可した相手の「帰り道(返事)」は自動で通す。 ■ ボディーガードに渡す指示書(許可ルールの実例) ✅ Webサーバー用: 世界中(ソース: ✅ 管理者(自分)の作業用: 自分のPC(ソース: ✅ データベースサーバー用: 別のボディーガード(ソース:
0.0.0.0/0)へ行くならIGWへ向かえ」という道順を書き込む。
0.0.0.0/0)からの、Webサイト閲覧(タイプ:HTTP / HTTPS)だけを許可。My IP)からの、メンテナンス通信(タイプ:SSH等)だけを許可。WebサーバーのSG ID)からパスを渡された通信(タイプ:MySQL等)だけを許可する(★AWSのベストプラクティス)。
【第3章】「動くもの」に命を吹き込む:EC2とストレージの黄金比
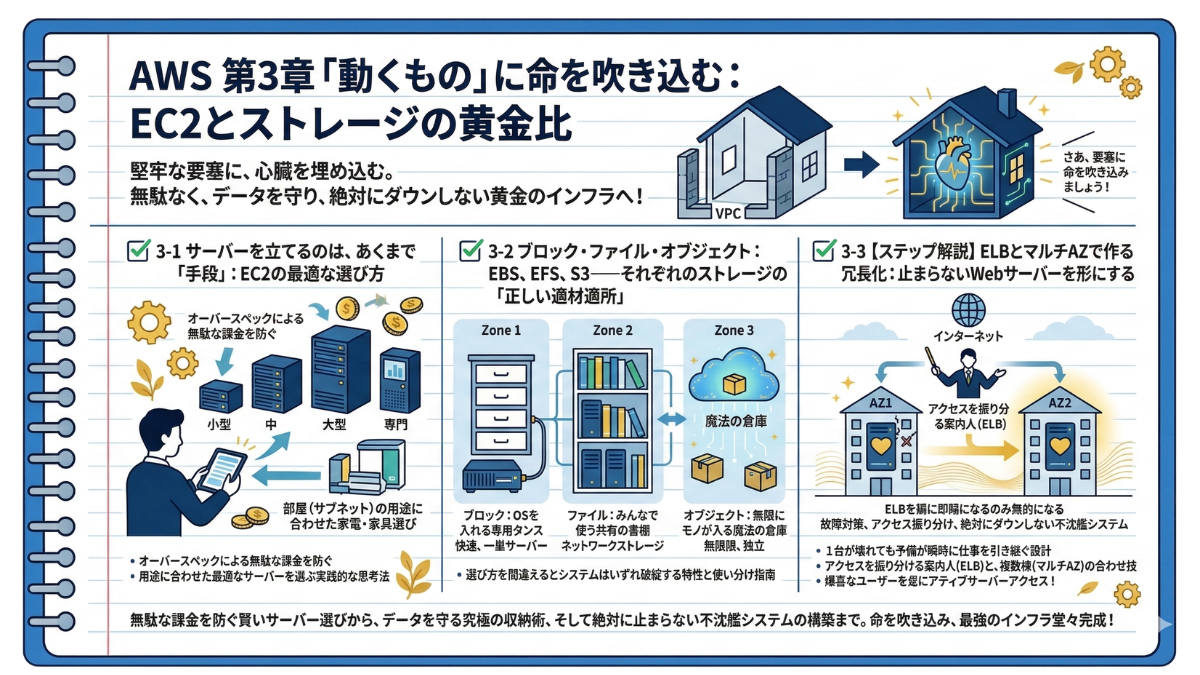
—— 誰もいない完璧な要塞に、心臓を埋め込む
堅牢な外壁、計算し尽くされた間取り、そして不審者を絶対に許さない屈強なボディーガード。 前章までで、あなたのAWS上には誰も破ることのできない「完璧な要塞(VPCネットワーク)」が完成しました。
しかし、いざ玄関の扉を開けて中に入ると、そこには不気味なほどの静寂が広がっています。 そう、この立派な家には、システムとして実際に稼働する「家電」も、大切な資産をしまう「収納」もまだ存在しないのです。
どんなに美しいネットワーク空間を構築しても、空っぽのままでは何の価値も生み出しません。システムに血を通わせ、世界中のお客さまにWebサービスを届けるための心臓部。それこそが、実際にプログラムを動かす「サーバー(EC2)」と、データを保管する「ストレージ」です。
本章では、静まり返った広大な空間に、システムの中核となる「動くもの」を配置していきます。サーバーが唸りを上げて動き出し、データが安全に保存され、大量のアクセスがさばかれる。あなたのITノートに、絶対に止まらない黄金のインフラを組み上げる極意を書き加えていきましょう。
本章で解説するステップは以下の3つです。
✅ 3-1 サーバーを立てるのは、あくまで「手段」:EC2の最適な選び方
サーバー構築=目的になっていませんか?EC2には数え切れないほどの種類(インスタンスタイプ)が存在します。オーバースペックによる無駄な課金を防ぎ、部屋の用途に合わせた最適な「家電・家具(サーバー)」を選ぶ実践的な思考法を解説します。
✅ 3-2 ブロック・ファイル・オブジェクト:EBS、EFS、S3——それぞれのストレージの「正しい適材適所」
データを保存する「収納」の選び方を間違えると、システムはいずれ破綻します。OSを入れる専用タンス(EBS)、みんなで使う共有の書棚(EFS)、無限にモノが入る魔法の倉庫(S3)。3つのストレージの特性と、絶対に間違えない使い分けを完全指南します。
✅ 3-3 【ステップ解説】ELBとマルチAZで作る冗長化:止まらないWebサーバーを形にする
どんなに高性能なサーバーも、機械である以上いつかは必ず故障します。「1台が壊れても、別の部屋に置いた予備が瞬時に仕事を引き継ぐ」。アクセスを振り分ける案内人(ELB)と、複数棟(マルチAZ)の合わせ技を駆使し、絶対にダウンしない不沈艦システムを形にします。
無駄な課金を防ぐ賢いサーバー選びから、データを守る究極の収納術、そして絶対に止まらない不沈艦システムの構築まで。空っぽの要塞に命を吹き込み、最強のインフラを共に完成させましょう!
サーバー構築が「目的」になっていませんか?本節ではAWSの心臓部「EC2」の選び方を解説。無駄な課金を防ぎ、部屋の用途に合わせた最適な「家電(サーバー)」を見極める、プロの思考法をノートに刻みましょう。
3-1 サーバーを立てるのは、あくまで「手段」:EC2の最適な選び方
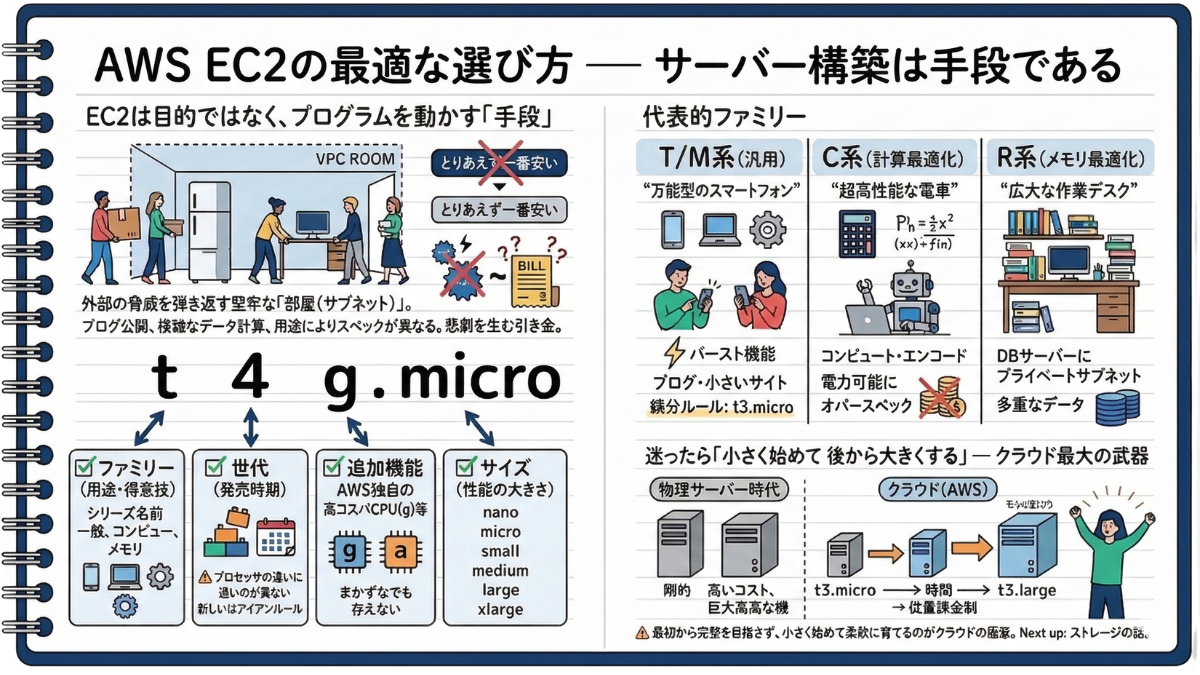
—— 「とりあえず一番安いサーバーでいいや」。AWS画面で適当なボタンを押そうとしているあなた、少し待ってください。その安易な選択が、数ヶ月後に「原因不明のシステムダウン」や「恐ろしい額の請求書」という悲劇を生む引き金になるかもしれません。
EC2は「目的」ではなく「手段」である。
これまで、外部の脅威を弾き返す堅牢な「部屋(サブネット)」を用意してきました。いよいよこの空っぽの空間に、システムの中核となる「家電(サーバー)」を運び込みます。AWSにおいて、この仮想サーバーの役割を担うのが「Amazon EC2(Elastic Compute Cloud)」です。
ここで多くの初級者が陥る罠があります。それは「EC2を立ち上げること」自体が目的になってしまうこと。しかし、サーバーはあくまでプログラムを動かすための「手段(ただの箱)」に過ぎません。ブログを公開したいのか、複雑なデータ計算をさせたいのか、用途(目的)によって選ぶべき家電のスペックは全く異なります。
—— 暗号を解読せよ!インスタンスタイプの見方
AWSの構築画面を開くと、「t3.micro」「c5a.large」といった謎の英数字がズラリと並びます。これをインスタンスタイプと呼びます。一見すると暗号のようですが、実は美しい法則があります。あなたの「ITノート」にこの法則を明確に書き留めておきましょう。
例:t4g.micro の場合
✅ 「t」 = ファミリー(用途・得意技) その家電が何を得意としているかの「シリーズ名」を示します(汎用、計算特化、メモリ特化など)。
✅ 「4」 = 世代(発売時期) 数字が大きいほど最新モデルです。基本的には最新世代を選ぶのが鉄則ですが、後述する「プロセッサの違い」には注意が必要です。
✅ 「g」 = 追加機能・プロセッサ(オプション)※つかない場合もあります。世代の後ろの小文字は、「AWS独自の高コスパCPU(g)」や「AMD製プロセッサ(a)」などの特徴を表します。
✅ 「micro」 = サイズ(性能の大きさ) 性能(CPUやメモリの容量)が大きくなり、比例して料金も高くなります。
・nano (最小)
・micro
・small
・medium
・large
・xlarge (大容量)
—— 代表的なファミリーの「適材適所」
実務でよく使う代表的な3つのファミリーを、家電に例えて翻訳しておきましょう。
✅ T系・M系(汎用ファミリー) ➡ 「万能型のスマートフォン」
何でもそつなくこなすバランス型の優等生です。特に「T系(t3など)」は、普段は省エネでサボりつつ、アクセスが急増した時だけ本気を出す「バースト機能」を持っています。個人のブログや小規模なWebサイトなら、まずは迷わず「T系のmicroやsmall」を選べば間違いありません。
(★注意点:先ほどの例に出した最新の「t4g」などはコスパ最強ですが、特殊な脳みそを持っているため初心者にはOS選びが困難です。最初は互換性トラブルが絶対に起きない『t3.micro』を選ぶのが最も安全な鉄則です)
✅ C系(コンピューティング最適化) ➡ 「超高性能な電卓」
複雑な計算処理や動画のエンコードなど、脳みそ(CPU)をフル回転させる重労働が得意です。しかし、一般的なブログなどの軽い用途には完全にオーバースペックとなり、無駄な課金が発生します。
✅ R系・X系(メモリ最適化) ➡ 「広大な作業デスク」
一度に大量のデータを広げて処理するのが得意です。前章で作った「奥の部屋(プライベートサブネット)」に置くデータベースサーバーなど、メモリ容量をガッツリ消費する重厚なシステムに向いています。
—— 迷ったら「小さく始めて、後から大きくする」
「自分のシステムにどれが最適か分からない…」と悩む必要はありません。EC2の名前の由来である「Elastic(弾力性・伸縮性)」こそが、クラウド最大の武器なのです。
物理サーバー時代は、最初に数百万円の巨大なサーバーを買ってしまったら最後、後から「やっぱりスペックを変えたい」は通用しませんでした。しかし、AWSは「使った分だけ(稼働した時間とサイズに応じて)支払う従量課金制」です。
だからこそ、「最初は一番安全で安い t3.micro で小さく始め、アクセスが増えて苦しくなったら、数分システムを止めるだけで t3.large に買い替える(スケールアップする)」という魔法のような運用が可能になります。
最初から完璧なサイジングを目指す必要はありません。用途に合わせたファミリー(アルファベット)だけを正しく選び、サイズは最小限からスタートする。これこそが、無駄なコストを極限まで抑えつつ最高のパフォーマンスを引き出す「EC2黄金の選び方」なのです。
EC2の選択は、用途を見極める「手段」に過ぎません。最初から完璧を求めず、小さく始めて柔軟に育てるのがクラウドの極意です。最適な家電(サーバー)が部屋に置かれた今、次はその中に入れる「収納(ストレージ)」の話へ進みましょう。
次の節は、『3-2 ブロック・ファイル・オブジェクト:EBS、EFS、S3——それぞれのストレージの「正しい適材適所」』へ続きます。サーバーの横に置く「専用タンス」から、限界のない「魔法の倉庫」まで。大切なデータを絶対に失わないための、AWSストレージ戦略の決定版をお届けします。お楽しみに!
■ EC2(サーバー)選びの基本スタンス サーバーは「手段」: EC2を立てることは目的ではなく、用途に合わせた「家電」を選ぶ作業。 クラウドの極意: AWSは従量課金制。最初から完璧なサイズを狙わず、「小さく始めて、アクセスが増えたら大きくする(スケールアップ)」のが鉄則。 ■ インスタンスタイプの法則(例: ■ 代表的なファミリーの「適材適所」 ✅ T系・M系(汎用): 万能型のスマートフォン。ブログや小規模サイトに最適。 ★初心者の鉄則: OSやソフトの互換性でつまずく心配が少ない、安全で安価な「 ✅ C系(計算最適化): 超高性能な電卓。動画処理など、CPUを酷使する重労働向け。 ✅ R系・X系(メモリ最適化): 広大な作業デスク。データベースなど、一度に大量のデータを処理する用途向け。
t4g.micro)
t(ファミリー): サーバーの得意分野(用途のシリーズ名)。4(世代): 発売時期。数字が大きいほど最新。g(オプション): 独自のCPUなどを示す追加機能(※つかない場合もある)。micro(サイズ): 性能と料金の規模(nano < micro < small < medium < large < xlarge)。
t3.micro」(Intel/AMD系)からスタートする。
サーバー(家電)を選んだら、次はデータをしまう「収納家具」選びです。これを間違えると大切な資産が一瞬で消え去ることも。本節ではAWSの3大ストレージ(EBS、EFS、S3)の適材適所を完全解説します!
3-2 ブロック・ファイル・オブジェクト:EBS、EFS、S3——それぞれのストレージの「正しい適材適所」
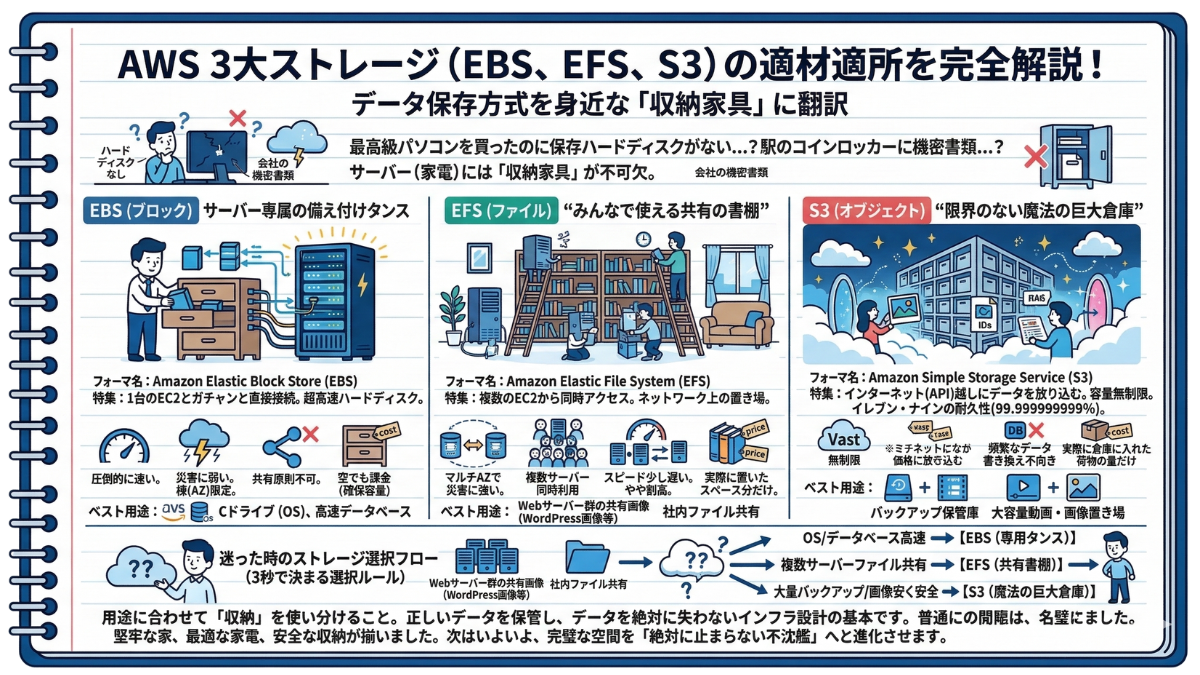
—— 最高級のパソコンを買ったのに、データを保存するハードディスクが付いていなかったら?あるいは、絶対に失ってはいけない会社の機密書類を、誰でも開けられる駅のコインロッカーに押し込んでしまったら?
サーバー(家電)には「収納家具」が必要不可欠。
前節で、用途に合わせた最適なサーバー(EC2)を選び、無事に部屋の中に配置しました。しかし、EC2という家電は、電源を入れただけでは何も覚えてくれません。OS(WindowsやLinux)をインストールし、お客さまのデータや画像を安全に保管するための「ストレージ(収納家具)」が絶対に必要になります。
AWSには10種類以上のストレージサービスが存在しますが、初級者が最初に覚えるべきはたったの3つだけです。データの保存方式である「ブロック」「ファイル」「オブジェクト」という小難しいIT用語を、わかりやすい「収納家具」の比喩に翻訳したので完璧にマスターしましょう。
1. EBS(ブロックストレージ) ➡ 「サーバー専属の備え付けタンス」
【正式名称】 Amazon Elastic Block Store (EBS)
【特徴】 1台のEC2(サーバー)にガチャンと直接つなぐ、超高速なハードディスクです。イメージとしては、その家電専用の備え付けタンスです。
【メリット】 読み書きのスピードが圧倒的に速いこと。
【デメリット(★超重要)】 サーバーと同じ棟(AZ)にしか置けません。その棟が災害などでダウンすると、タンスも一緒に開けなくなります。また、別の部屋にあるサーバーと共有することも原則できません。
【課金の罠】 「タンスの大きさ」を買うため、中身が空っぽでも、確保した容量(例:100GB)に対して毎月課金され続けます。
【適材適所】 EC2の「Cドライブ(OSを入れる場所)」や、高速な読み書きが求められる「データベース」の保存先として、必ずEC2とセットで使います。
2. EFS(ファイルストレージ) ➡ 「みんなで使える共有の書棚」
【正式名称】 Amazon Elastic File System (EFS)
【特徴】 複数のEC2から同時にアクセスできる、ネットワーク上のファイル置き場です。リビングに置かれた「家族全員で共有できる大きな書棚」を想像してください。
【メリット】 複数の棟(AZ)にまたがってデータを保存できるため災害に強く、何台のサーバーからでも同時に同じファイルを読み書きできます。
【デメリット】 EBS(専用タンス)と比べると、読み書きのスピードは少しだけ遅く、単価の料金もやや割高になります。
【課金の仕組み】 EBSと違い、「実際に本を置いたスペース分だけ」の自動課金です。あらかじめ巨大な書棚を買う必要はありません。
【適材適所】 複数台のWebサーバーで同じ画像を表示させたい場合(WordPressの画像フォルダなど)や、社内のファイル共有サーバーとして大活躍します。
3. S3(オブジェクトストレージ) ➡ 「限界のない魔法の巨大倉庫」
【正式名称】 Amazon Simple Storage Service (S3)
【特徴】 AWSが世界に誇る、最強のクラウドストレージです。EC2に直接つなぐのではなく、インターネット(API)越しにデータを放り込みます。
【メリット】 容量が無制限(いくらでも入る)で、料金が圧倒的に安いこと。複数の棟(AZ)に自動でコピーされ、「99.999999999%(イレブン・ナイン)」という天文学的な耐久性を持つため、預けたデータが消えることはほぼ100%ありません。
【デメリット】 データベースのような「データを頻繁に細かく書き換える作業」には全く向いていません。
【課金の仕組み】 こちらもEFSと同様、「実際に倉庫に入れた荷物の量だけ」の課金です。
【適材適所】 万が一のための「バックアップデータの保管庫」や、大容量の「動画・画像ファイルの置き場」として、最強のパフォーマンスを発揮します。
—— 迷った時のストレージ選択フロー
実務で迷わないよう、あなたのノートに以下の「3秒で決まる選択ルール」を書き留めておきましょう。
✅ OSを入れたり、データベースを高速で動かしたい ➡ 【EBS(専用タンス)】
✅ 複数のサーバーで、同じファイルを同時に共有したい ➡ 【EFS(共有書棚)】
✅ 大量のバックアップや画像を、とにかく安く安全に置きたい ➡ 【S3(魔法の巨大倉庫)】
どんなに立派な家(VPC)と、高性能な家電(EC2)を揃えても、用途に合わない収納(ストレージ)を選んでしまえば、システムはボトルネックを起こして破綻します。この3つの特性を理解し、正しい場所に正しいデータを保管することこそが、インフラエンジニアへの第一歩なのです。
用途に合わせて「収納」を使い分けること。これこそが、データを絶対に失わないインフラ設計の基本です。堅牢な家、最適な家電、そして安全な収納が揃いました。次はいよいよ、この完璧な空間を「絶対に止まらない不沈艦」へと進化させます。
次節、『3-3 【ステップ解説】ELBとマルチAZで作る冗長化:止まらないWebサーバーを形にする』へ続きます。どんなに立派な家や備え付けのタンス(EBS)でも、物理的な災害や故障からは逃れられません。アクセスを振り分ける案内人(ELB)と、複数棟(マルチAZ)で支え合う「絶対に止まらないシステム」の極意を解説します。
■ ストレージ選びの基本 サーバーは「手段」: EC2(家電)には、データを保管・記憶するための「ストレージ(収納家具)」が必須。 適材適所: 用途を間違えるとシステム破綻に繋がるため、3つの特性を理解して使い分ける。 ■ 1. EBS(ブロックストレージ):サーバー専属の備え付けタンス 特徴: 1台のEC2に直接つなぐ超高速ハードディスク。 注意点: サーバーと同じ棟(AZ)にしか置けず、他サーバーとの共有不可。「確保したタンスの容量分」の固定課金。 適材適所: OSを入れるCドライブ、高速処理が必要なデータベース。 ■ 2. EFS(ファイルストレージ):みんなで使える共有の書棚 特徴: 複数のEC2から同時にアクセスできるネットワーク上のファイル置き場。 注意点: 複数AZにまたがり災害に強い。料金は「使った分だけ」だが、EBSより少し遅く割高。 適材適所: 複数サーバーでのファイル共有(WordPressの画像など)、社内ファイルサーバー。 ■ 3. S3(オブジェクトストレージ):限界のない魔法の巨大倉庫 特徴: インターネット越しにデータを保存する、容量無制限のクラウドストレージ。 注意点: 圧倒的に安く、データ消失率がほぼ0%(イレブン・ナイン)。頻繁なデータの書き換えには不向き。料金は「使った分だけ」。 適材適所: 大量のバックアップデータ、動画・画像ファイルの保管庫。 ■ 迷った時の3秒ルール ✅ OSを入れたり、データベースを高速で動かしたい ➡ 【EBS】 ✅ 複数のサーバーで、同じファイルを同時に共有したい ➡ 【EFS】 ✅ 大量のバックアップや画像を、とにかく安く安全に置きたい ➡ 【S3】
どんなに高性能な家電(サーバー)も、機械である以上いつかは必ず壊れます。本節では、アクセスを案内する「ELB」と、複数棟にシステムを配置する「マルチAZ」を駆使し、絶対に止まらない不沈艦をノートに設計しましょう。
3-3 【ステップ解説】ELBとマルチAZで作る冗長化:止まらないWebサーバーを形にする
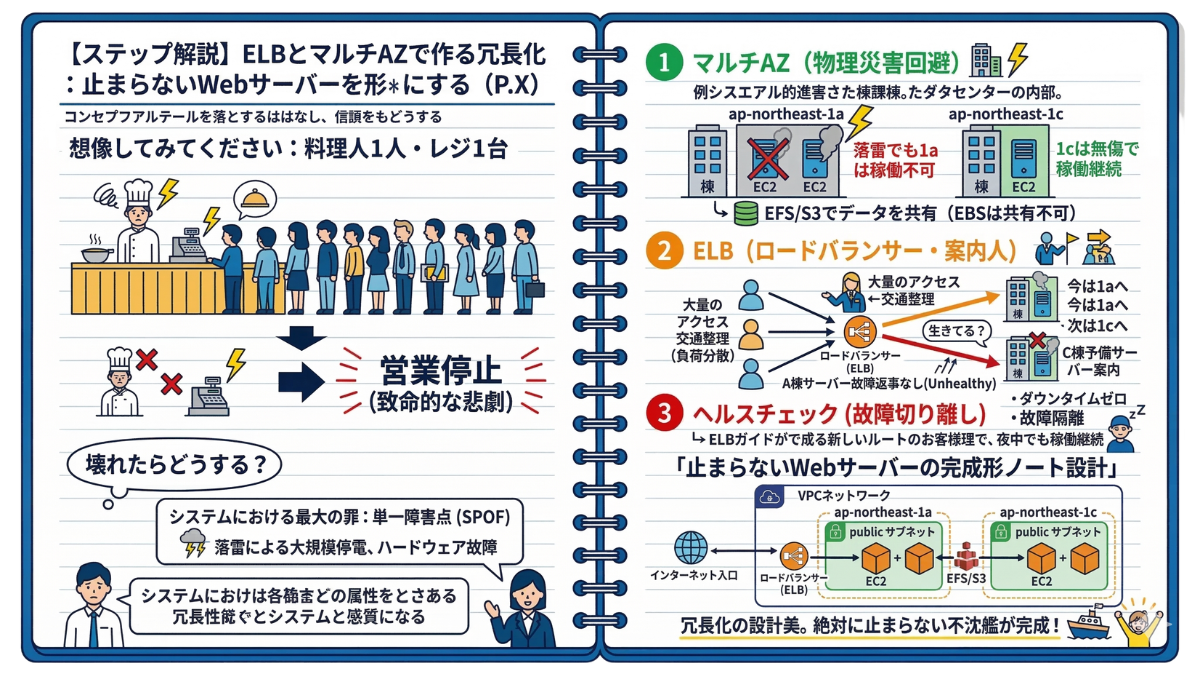
—— 大行列ができる大人気のレストランを開業したのに、料理人が1人しかおらず、レジも1台しかなかったら?もしその料理人が風邪を引いたり、レジが故障したりすれば、その瞬間に店は「営業停止」という致命的な悲劇を迎えます。
「1台しかない」はシステムにおける最大の罪。
前節までで、あなたのVPC(敷地)には最適なEC2(家電)とストレージ(収納)が配置されました。しかし、これを「1つのAZ(棟)」に「1台だけ」置いた状態で満足してはいけません。
AWSが誇る堅牢なデータセンターといえど、落雷による大規模停電や、ハードウェアの物理的な寿命による故障は必ず発生します。このように「そこが壊れたらシステム全体が死んでしまう単一の弱点」を、IT用語で「SPOF(単一障害点:Single Point of Failure)」と呼びます。
一流のエンジニアは、決してサーバーが「壊れないこと」を前提に設計しません。「壊れても、ユーザーに気づかれないうちに予備が引き継ぐこと」を前提にシステムを組み上げます。これが「冗長化」です。
ステップ1:マルチAZ(複数棟)で落雷の直撃を回避する
まずは、物理的な災害への備えです。AWSの「リージョン(東京など)」の中には、「AZ(アベイラビリティゾーン)」と呼ばれる、物理的に離れた独立したデータセンター群(棟)が複数存在しています。
もし「1a」という棟に落雷があっても、「1c」という数キロ離れた別の棟は無傷で稼働し続けます。これを利用し、「まったく同じ設定のサーバー(双子)を、別の棟にもう1台配置する」のです。これが「マルチAZ」構成です。
注意:この双子が「全く同じ内容」をお客さまに提供するためには、前節で学んだEFS(共有書棚)が活躍します。専用タンスであるEBSは別の棟と共有できないため、画像データなどをEFSやS3に逃がしておく設計がここで活きてくるのです。
ステップ2:ELB(ロードバランサー)という最強の案内人を雇う
サーバーを2つの棟に用意しました。しかし、このままではお客さま(アクセス)はどちらの棟に行けばいいのか迷ってしまいます。そこで、敷地の入り口(パブリックサブネット)に立つ優秀なコンシェルジュを雇います。
これが「ELB(Elastic Load Balancing)」です。ELBは、外からやってきた大量のアクセスを受け止め、「今はA棟が空いているからA棟へ」「次はC棟へ」と、交通整理(負荷分散)を行ってくれます。
ステップ3:ヘルスチェックで「死んだ死角」を瞬時に切り離す
ELBの頼もしさは、単なる交通整理だけではありません。ELBは数秒おきに、背後にいる各サーバーに「生きてる?」と定期連絡を入れ続けています。これを「ヘルスチェック」と呼びます。
もしA棟のサーバーが故障して返事がない(Unhealthy)と判断した場合、ELBは瞬時に「A棟は危険だ。すべてのお客さまをC棟の予備サーバーに案内しろ!」とルートを自動変更します。管理者が寝ている深夜にサーバーが1台火を噴いても、死んだサーバーを自動で隔離し、システム全体としては停止することなく稼働し続ける。これこそが、ユーザーにエラー画面を見せない「ダウンタイムゼロ」の極意です。
—— 止まらないWebサーバーの完成形
ここまで学んだ第2章・第3章のすべてを組み合わせた「最強のインフラ構成」をノートにまとめましょう。
・VPCという巨大な敷地(ネットワーク)を作る。
・1a棟と1c棟(マルチAZ)に部屋(サブネット)を分ける。
・インターネットの入り口にELB(案内人)を立たせる。
・各棟にEC2(双子のサーバー)を配置し、ELBに監視させる。
・共有すべきデータは、棟をまたげるEFSやS3(収納)に守らせる。
1台の故障を恐れない「冗長化」の設計美、いかがでしたか?これでネットワークという箱から、止まらないサーバーという心臓部まで、フロントエンドの基盤が完璧に完成しました。あなたのノートは今、とてつもない価値を持っています。
次回からはいよいよバックエンドの深淵へ。『【第4章】「資産」を預ける覚悟:データストアとアクセス権限の鉄則』へ続きます。顧客の個人情報という「絶対的資産」を守るデータベース(RDS)と、誰にも突破されない権限管理(IAM)の極意に迫ります。お楽しみに!
■ インフラ設計の絶対ルール SPOF(単一障害点)の排除: 「そこが壊れたらシステムが全滅する」という弱点(1台構成など)をシステムから無くすこと。 冗長化: サーバーは「必ず壊れる」前提に立ち、壊れても予備が自動で引き継ぐ仕組みを作ること。 ■ 止まらないWebサーバーを作る3つの鍵 マルチAZ(複数棟配置): 物理的に離れた別のデータセンター(AZ)に、双子のサーバー(EC2)を配置し、災害時の共倒れを防ぐ。※データ共有にはEFSやS3が必須。 ELB(ロードバランサー): 敷地の入り口に立つ案内人。大量のアクセスを受け止め、各棟のサーバーへ適切に振り分ける(負荷分散)。 ヘルスチェック(死活監視): ELBが数秒おきにサーバーの生存確認を行う機能。故障したサーバーを瞬時に自動隔離し、正常なサーバーのみに案内を続けることで「ダウンタイムゼロ」を実現する。 ■ 最強のインフラ構成(完成形) VPCという巨大な敷地(ネットワーク)を作る。 1a棟と1c棟(マルチAZ)に部屋(サブネット)を分ける。 インターネットの入り口にELB(案内人)を立たせる。 各棟にEC2(双子のサーバー)を配置し、ELBに監視させる。 共有すべきデータは、棟をまたげるEFSやS3(収納)に守らせる。
【第4章】「資産」を預ける覚悟:データストアとアクセス権限の鉄則
あなたは、お客様の「人生」を預かることができるか?
もしあなたの家が空き巣に入られたとして、一番困るのは「テレビや家具が盗まれること」でしょうか?いいえ、違います。本当に恐ろしいのは「通帳と印鑑」、あるいは「家族の思い出が詰まったアルバム」を奪われることです。
前章までで、私たちはどんなアクセスが来ても絶対に止まらない、最強の「双子のサーバー(EC2)」と「案内人(ELB)」を構築しました。しかし、どれほど立派な家(インフラ)と素晴らしい家具(サーバー)を揃えても、それだけではただの「空箱」です。システムが真の価値を生み出すのは、そこにお客様の個人情報や決済履歴、つまり絶対に失ってはいけない「資産(データ)」が流れ込んだ瞬間からです。
テレビ(サーバー)であれば、壊れたり盗まれたりしても、すぐに新しいものを買ってきて配置すれば(再構築すれば)元の生活に戻れます。しかし、一度漏洩した顧客の個人情報や、消失した決済データは、いくらお金を払っても二度と元には戻りません。
本章から踏み込む「バックエンド(データベースと権限管理)」の領域は、単なる技術論ではありません。お客様の大切な資産を預かるという「覚悟」を形にする場所なのです。
あなたのITノートに、堅牢な金庫の選び方と、誰にも突破されない鉄壁のルールを刻み込みましょう。
本章で解説するステップは以下の3つです。
✅ 4-1 RDSとDynamoDB:そのデータ、リレーショナルですか?NoSQLですか?
データには「厳密な表」と「自由なメモ」があります。顧客情報など絶対にズレが許されない表(RDS)と、大量のアクセスを瞬時にさばくメモ(DynamoDB)。データの性格を見極め、最適な金庫を選ぶ達人の選択術を解説します。
✅ 4-2 すべての操作はここから始まる:IAM(アイアム)による最小権限の原則
どんなに強固な金庫でも、全員にマスターキーを渡せば意味がありません。「誰が・何に・どう触れるか」を極限まで絞り込む「IAM」の最小権限の原則。内部からの操作ミスや情報漏洩を完全に防ぐ、アクセス管理の鉄則を学びます。
✅ 4-3 究極の防御は「戻せる」こと:もしもの時に「大丈夫」と言えるバックアップ設計
究極の防御とは「絶対に壊れないこと」ではなく、「壊れても昨日と同じ状態に必ず戻せること」です。人為的ミスによるデータ消去や脅威から資産を守り抜く。もしもの時に「大丈夫」と即答できるバックアップ設計を形にします。
お客様の「資産」を預かる覚悟はできましたか?絶対にズレない金庫の選び方から、鉄壁の鍵管理、そして時間を巻き戻す究極の防御策まで。あなたのノートに、信頼という名のバックエンド基盤を書き加える準備を始めましょう!
お客様の「資産」を預かる金庫選び。データをきっちり整理する「RDS」と、圧倒的なスピードと柔軟性を誇る「DynamoDB」。絶対に間違えられない2大データベースの使い分けを完全解説します!
4-1 RDSとDynamoDB:そのデータ、リレーショナルですか?NoSQLですか?
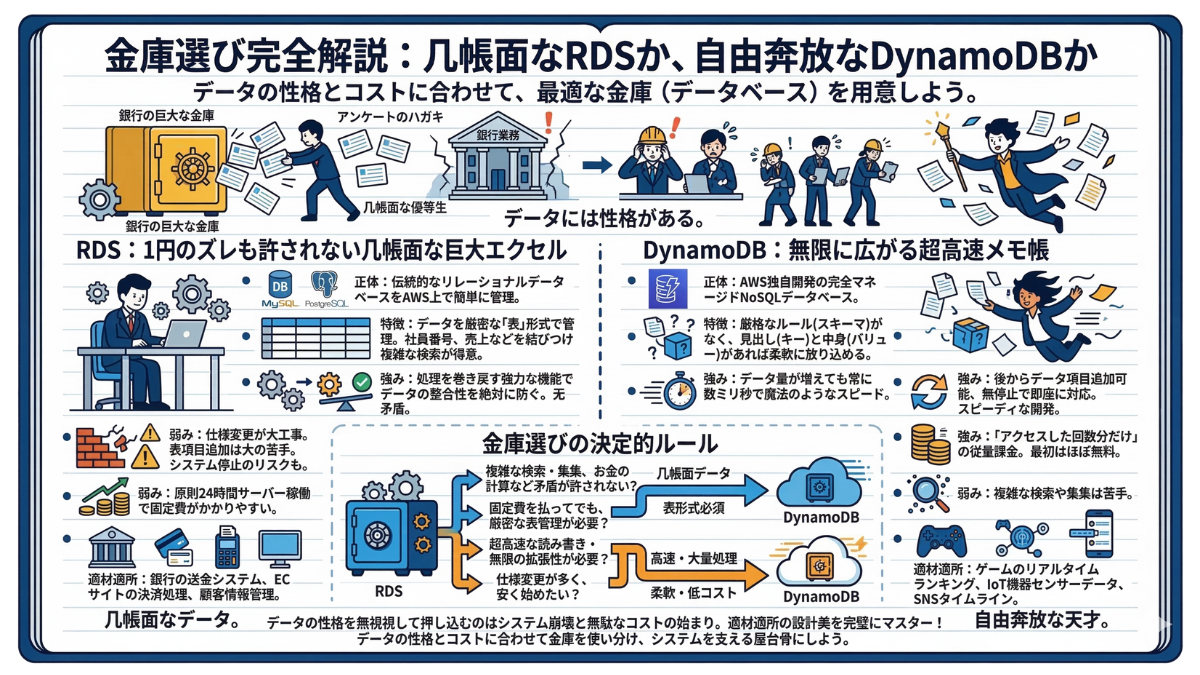
—— 1円のズレも許されない「銀行の巨大な金庫」に、毎日何百万枚も送られてくる「アンケートのハガキ」を無理やり詰め込もうとしたらどうなるでしょうか?瞬く間に金庫はパンクし、銀行の業務は完全に停止してしまうはずです。
データには「性格」がある。
前章までで構築したインフラという家に、いよいよ「データ」という命を吹き込みます。しかし、すべてのデータを同じ場所に保存してはいけません。
システムが扱うデータには、大きく分けて「几帳面な優等生」と「自由奔放な天才」の2つの性格があります。この性格を見極め、最適な「金庫(データベース)」を用意することこそが、優れたインフラ設計者の絶対条件です。AWSを代表する2つのデータベース、「RDS」と「DynamoDB」の決定的な違いを、あなたのITノートに図解とともに書き留めておきましょう。
—— RDS:1円のズレも許さない「几帳面な巨大エクセル」
-
【正体は?】 Amazon Relational Database Service。MySQLやPostgreSQLといった伝統的な「リレーショナルデータベース」を、AWS上で簡単に管理できるサービスです。
-
【特徴】 データを「行と列」を持つ厳密な表(テーブル)形式で管理します。社員番号と名前、部署と売上などを結びつけて、複雑な検索や集計を行うのが大得意です。
-
【強みと弱み】 途中で処理が失敗したら「完全に元の状態に巻き戻す」機能が強力で、データの不整合を絶対に防ぎます。一方で、「後から表の項目(列)を追加する」などの仕様変更が大の苦手であり、システム停止のリスクを伴う大工事になりがちです。また、原則としてサーバーを24時間稼働させるため、固定費がかかりやすい側面があります。
-
【適材適所】 銀行の送金システム、ECサイトの決済処理、顧客情報の管理など、「絶対に矛盾が起きてはいけない、きっちりしたデータ」の保管に最適です。
—— DynamoDB:無限に広がる「超高速なメモ帳」
-
【正体は?】 AWSが独自に生み出した、完全マネージド型の「NoSQL(非リレーショナル)」データベースです。
-
【特徴】 RDSのような厳格な表のルール(スキーマ)がありません。見出し(キー)と中身(バリュー)さえあれば、どんな形のデータでもポンポンと放り込める柔軟性を持っています。
-
【強みと弱み】 データ量がどれだけ増えても、常に「数ミリ秒」という魔法のようなスピードでデータを返し続けます。さらに、後からデータ項目を追加したい場合も無停止で即座に対応できるため、現代のスピーディなアプリ開発と相性抜群です。また、「アクセスした回数分だけ」の完全従量課金を選べるため、最初はほぼ無料でスタートできるのも魅力です。ただし、複雑な検索や集計は苦手です。
-
【適材適所】 ゲームのリアルタイムランキング、IoT機器から送られ続ける膨大なセンサーデータ、SNSのタイムラインなど、「形がバラバラで、とにかく大量かつ高速に処理したいデータ」に最適です。
—— 金庫選びの決定的ルール
実務で「どちらのデータベースを使うべきか?」と迷ったときは、以下のシンプルな基準で決断を下してください。
✅ 複雑な検索や、お金の計算など「絶対に矛盾が許されない」か? ➡ 【RDS】
✅ 「24時間稼働の固定費」を払ってでも、厳密な表管理が必要か? ➡ 【RDS】
✅ とにかく超高速な読み書きと、無限の拡張性が必要か? ➡ 【DynamoDB】
✅ 仕様変更が多く、最初は「使った分だけの課金」で安く始めたいか? ➡ 【DynamoDB】
データの性格を無視して、何でもかんでも一つのデータベースに押し込むのは、システム崩壊と無駄なコストの始まりです。用途に合わせて金庫を使い分ける「適材適所」の設計美を、ここで完璧にマスターしましょう。
厳密さを極めるRDSと、無限の速度と柔軟性を持つDynamoDB。データの性格とコストに合わせた金庫選びこそが、システムを支える屋台骨となります。大切な資産をしまう場所が決まったら、次はその「鍵」の管理です。
次節は、『4-2 すべての操作はここから始まる:IAM(アイアム)による最小権限の原則』へ続きます。どんなに頑丈な金庫を作っても、全員にマスターキーを渡してしまえば意味がありません。クラウドセキュリティの要となる「IAM」の鉄則を簡潔に解説します。
■ データベース(金庫)選びの基本 データには「几帳面な優等生」と「自由奔放な天才」の2つの性格がある。 性格を無視して1つの金庫に詰め込むと、システム崩壊や無駄なコストに繋がるため「適材適所」の見極めが必須。 ■ 1. RDS(リレーショナル):几帳面な巨大エクセル 特徴: 「行と列」の厳密な表形式で管理。複雑な検索やデータの結びつけ(集計)が得意。 強み: 処理失敗時に「巻き戻す」機能があり、データの矛盾や不整合を絶対に防ぐ。 弱み: 後からの仕様変更(項目の追加など)が苦手。原則24時間稼働のため、固定費がかかりやすい。 適材適所: お金の計算(決済)、顧客情報の管理など、1円のズレも許されないデータ。 ■ 2. DynamoDB(NoSQL):無限に広がる超高速なメモ帳 特徴: 厳格な表のルールがなく、見出しと中身だけでどんな形でも保存できる柔軟性を持つ。 強み: どれだけデータが増えても超高速(数ミリ秒)で応答。無停止での仕様変更が可能で、アクセス分だけの「完全従量課金」で安く始められる。 弱み: 複雑な検索やデータの結びつけ(集計)は苦手。 適材適所: ゲームのランキング、SNSのタイムライン、IoTのセンサーなど、形がバラバラで大量・高速に処理したいデータ。 ■ 迷った時の決断ルール ✅ 複雑な検索や、お金の計算など「絶対に矛盾が許されない」 ➡ 【RDS】 ✅ 固定費を払ってでも、厳密な表管理が必要 ➡ 【RDS】 ✅ とにかく超高速な読み書きと、無限の拡張性が必要 ➡ 【DynamoDB】 ✅ 仕様変更が多く、最初は「使った分だけの課金」で安く始めたい ➡ 【DynamoDB】
どんなに強固な金庫(データベース)を用意しても、全員に「魔法の合鍵」を渡してしまえばシステムは一瞬で崩壊します。本節では、AWSセキュリティの要「IAM」を使い、内部からの脅威を防ぐ「最小権限の原則」を徹底解説します!
4-2 すべての操作はここから始まる:IAM(アイアム)による最小権限の原則
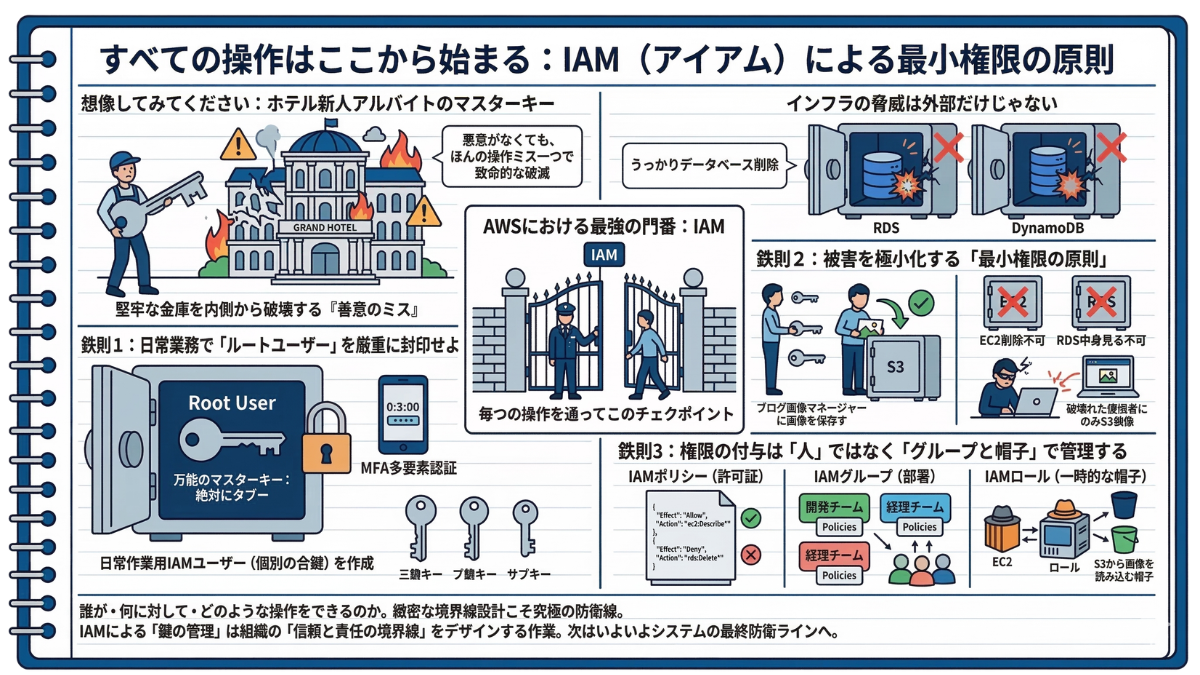
—— 入社初日の新人アルバイトに、ホテルの全客室はもちろん、支配人室や地下の巨大金庫まで開けられる「万能のマスターキー」をポツンと渡してしまったら……?悪意がなくても、ほんの操作ミス一つでホテル全体が致命的な破滅を迎える未来が容易に想像できるはずです。
堅牢な金庫を内側から破壊する「善意のミス」。
前節で、大切なデータを守る強固な金庫(RDSとDynamoDB)が完成しました。しかし、インフラにおける最大の脅威は、外部からのハッカーによる攻撃だけではありません。実は、システムを崩壊させる原因の多くは、内部の人間の「悪意のない操作ミス」なのです。
「ちょっと設定を見ようとしただけなのに、間違えて本番のデータベースを削除してしまった」こんな背筋の凍るような大事故を防ぐための、AWSにおける最強の門番。それが「IAM(Identity and Access Management:アイアム)」です。AWS上のすべての操作は、必ずこのIAMという関所を通らなければ実行できません。
鉄則1:日常業務で「ルートユーザー」を厳重に封印せよ
AWSアカウントを開設した際に作った、メールアドレスとパスワードの組み合わせ。これを「ルートユーザー」と呼びます。これは、AWS上のすべてのサービスを操作し、果てはアカウントそのものを解約(削除)することすらできる、先ほどの「万能のマスターキー」に他なりません。
このマスターキーを日常の作業に使ったり、開発メンバーで使い回したりするのは、絶対にやってはいけない最大のタブーです。まずはルートユーザーに「MFA(多要素認証:スマホのワンタイムパスワードなど)」という頑丈な南京錠をかけ、金庫の奥底に厳重に封印してください。そして、日常の構築作業を行うための「個別の合鍵(IAMユーザー)」を新たに作成することから、すべてが始まります。
鉄則2:被害を極小化する「最小権限の原則」
IAMの根幹をなす最も重要な考え方が「最小権限の原則」です。これは、「その人が仕事をするために必要な、最低限の権限しか絶対に与えない」という厳格なルールのこと。
例えば、ブログにアップロードする画像を管理するだけの担当者には、「S3(画像の保管庫)に画像を保存する権限」だけを与えます。「EC2(サーバー)を削除する権限」や「RDS(金庫)の中身を見る権限」は絶対に与えません。こうしておけば、万が一その担当者のパソコンが乗っ取られたり、操作手順を間違えたりしても、被害はS3の画像領域だけに限定され、システム全体が沈没する事態は防げます。
鉄則3:権限の付与は「人」ではなく「グループと帽子」で管理する
会社が大きくなり、メンバーが数十人に増えたとき、一人ひとりに個別の権限を手作業で設定していては管理が破綻し、設定漏れの原因になります。そこで、あなたのITノートに以下の3つの強力な概念を整理しておきましょう。
-
IAMポリシー(許可証): 「EC2を見てよし」「RDSを消してはダメ」という具体的なルールの箇条書きリスト(JSONという形式で書かれます)。
-
IAMグループ(部署): 「開発チーム」「経理チーム」といった箱を作り、そこに上記のポリシー(許可証)を貼ります。新しく入ってきたメンバーは、そのグループに入れるだけで自動的に正しい権限が与えられます。
-
IAMロール(一時的な帽子): 人間ではなく、「機械(EC2などのAWSサービス)」にかぶせる帽子です。たとえば、EC2に「S3から画像を読み込む帽子(ロール)」をかぶせることで、システムの中にパスワードを直接書き込むことなく、安全にAWSサービス同士を連携させることができます。
「誰が・何に対して・どのような操作をできるのか」。このIAMの緻密な境界線設計こそが、一流のエンジニアが最も神経を尖らせる究極の防衛線なのです。
IAMによる「鍵の管理」は、単なる初期設定ではなく、組織の「信頼と責任の境界線」をデザインする極めて重要な作業です。マスターキーの封印と厳格な権限管理が完了したら、次はいよいよシステムの最終防衛ラインへと向かいます。
次節は、『4-3 究極の防御は「戻せる」こと:もしもの時に「大丈夫」と言えるバックアップ設計』へ続きます。どんなに権限を絞り、システムを冗長化しても、大規模な災害や予期せぬ事故のリスクはゼロにはなりません。絶望の淵から時間を巻き戻し、大切な資産を復元する「究極の安心設計」を解説します。
■ IAM(アイアム)の基本と目的 最大の脅威への備え: システム崩壊の多くは外部攻撃ではなく「内部の悪意のない操作ミス」。これを防ぐAWSの最強の門番がIAM。 すべての操作の関所: AWS上のあらゆる操作は、必ずIAMで許可される必要がある。 ■ 権限管理を守る3つの鉄則 鉄則1:ルートユーザーの封印 アカウント作成時のルートユーザーは「万能のマスターキー」。日常業務での使用や使い回しは絶対NG。 必ずMFA(多要素認証)を設定して封印し、作業用の「IAMユーザー(個別の合鍵)」を作成して運用する。 鉄則2:最小権限の原則 仕事に必要な「最低限の権限」しか絶対に与えないルール。 アカウント乗っ取りや操作ミスが発生しても、被害の範囲(影響範囲)を極小化し、システム全体の沈没を防ぐ。 鉄則3:「人」ではなく「グループと帽子」による管理 個人単位での手作業は管理破綻や設定漏れを招くため、以下の3概念を活用する。 IAMポリシー(許可証): 「○○して良し・ダメ」を定めたルールのリスト(JSON形式)。 IAMグループ(部署): メンバーをまとめる箱。ここにポリシーを貼ることで、新メンバーにも自動で正しい権限が付与される。 IAMロール(一時的な帽子): 人間ではなく「EC2などの機械(AWSサービス)」にかぶせる権限。パスワードを直接システムに書き込まず、安全にサービス同士を連携させる。
どんなに堅牢なシステムでも、人為的ミスや災害のリスクはゼロになりません。本節では「絶対に壊れない」という幻想を捨て、「確実に元に戻せる」究極の防衛線、AWSのバックアップ設計の極意を刻みます。
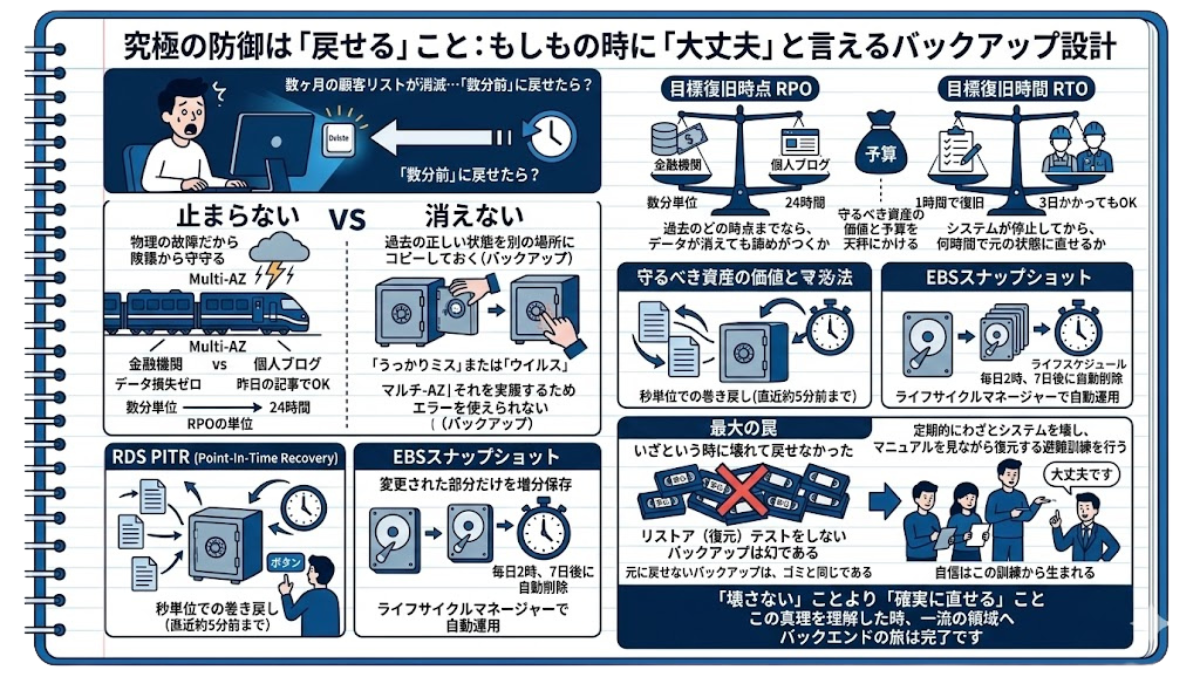
4-3 究極の防御は「戻せる」こと:もしもの時に「大丈夫」と言えるバックアップ設計
—— あなたが数ヶ月かけて徹夜で入力し続けた数万件の顧客リストが、たった1回の「Deleteキー」の押し間違いで、画面から完全に消滅してしまったその瞬間を。背筋が凍り、頭の中が真っ白になるあの絶望感……。しかし、もしその時、時計の針を「たった数分前」に巻き戻せるとしたらどうでしょうか?
「止まらない」と「消えない」は全く別の問題。
第3章で学んだ「マルチAZ(複数棟配置)」は、落雷などでサーバーが物理的に壊れた際に、別のサーバーが身代わりになってくれる素晴らしい仕組みでした。しかし、これには一つだけ「致命的な弱点」があります。
それは、「正しい権限を持った人間が、間違ったデータを上書きしてしまった場合、その間違った状態まで瞬時に同期されてしまう」ということです。前節のIAMで権限を絞っても、作業担当者自身の「うっかりミス」や、システム内部に入り込んだ未知のウイルスによるデータ破壊は防ぎきれません。だからこそ、システム設計における最後の命綱として「過去の正しい状態を、別の場所にコピーしておく(バックアップ)」という発想が必要になります。
1:バックアップ設計の2大指標「RPO」と「RTO」
実務において、「とりあえず全部バックアップしておこう」という思考停止は許されません。バックアップの頻度を上げれば上げるほど、莫大な保管コストがかかるからです。そこで、設計の最初に必ず以下の「2つの指標(天秤)」を決めます。
-
RPO(Recovery Point Objective:目標復旧時点)
「過去のどの時点までなら、データが消えても諦めがつくか」という指標です。例えば、1日1回深夜にバックアップを取る設計なら、最悪の場合「丸1日分のデータ」を失う覚悟が必要です(RPO=24時間)。 -
RTO(Recovery Time Objective:目標復旧時間)
「システムが停止してから、何時間で元の状態に直せるか」という指標です。「1時間で復旧させる」のか「3日かかってもいい」のかで、用意すべき復旧手順とコストが劇的に変わります。
金融機関のシステムなら「データ損失を限りなくゼロに近づける(RPOを数分単位にする)」ための多額のコストをかけますが、個人のブログであれば「昨日の記事が消えるくらいなら許容できる(RPO=24時間)」といったように、守るべき資産の価値と予算を天秤にかけるのが設計者の腕の見せ所です。
2:AWSが誇る「時間を巻き戻す魔法」
自前でサーバーを持っていた時代、バックアップはテープに記録して金庫にしまうなど、とてつもない労力がかかりました。しかしAWSでは、この作業が劇的に自動化されています。
-
RDSの「Point-In-Time Recovery(PITR)」
絶対にズレてはいけない金庫であるRDSには、恐ろしいほど優秀な機能が備わっています。毎日の自動バックアップに加えて、データの変更履歴を常に記録しているため、「今日の14時23分15秒の状態に戻して!」といった「秒単位での巻き戻し(※直近約5分前まで)」がクリック一つで可能なのです。 -
EBSの「スナップショット」
EC2(サーバー)の備え付けタンスであるEBSは、「変更された部分だけ」を効率よく写真に撮るように保存(増分バックアップ)してくれます。これを「ライフサイクルマネージャー」という機能と組み合わせれば、「毎日深夜2時に撮影し、古いものは7日後に自動で捨てる」という運用を手放しで実現できます。
3:【最大の罠】リストア(復元)テストをしないバックアップは幻である
最後に、インフラエンジニアとして最も肝に銘じるべき真理をお伝えします。それは「いざという時に元に戻せないバックアップは、ゴミと同じである」ということです。
「毎日バックアップを取っているから安心」と思い込んでいても、いざ障害が起きた時に「データが壊れていて戻せなかった」「戻す手順を誰も知らなかった」という悲劇が現場では後を絶ちません。定期的に「わざとシステムを壊し、マニュアルを見ながら復元(リストア)する避難訓練」を行うこと。もしもの時に社長や顧客へ「大丈夫です」と即答できる自信は、この訓練からしか生まれません。
「壊さない」ことより「確実に直せる」こと。この真理を理解した時、あなたのインフラ設計は一流の領域へと到達します。これで大切な資産を守るバックエンドの旅は完了です。
次回は新章へ。『【第5章】「サーバーなし」の衝撃:Lambdaで見直すアプリケーションの形』へ続きます。これまで苦労して構築してきたサーバー(EC2)を、あえて「捨てる」という逆転の発想。クラウドの真骨頂であるサーバーレスアーキテクチャの世界へご案内します。お楽しみに!
■ バックアップの絶対的な前提 「冗長化」の弱点: 人為的な操作ミスやウイルスによるデータ破壊は、冗長化されたシステム全体に瞬時に同期されてしまう。 究極の防御: 絶対に壊れないシステムを作るのではなく、「過去の正しい状態に必ず巻き戻せる(バックアップ)」仕組みを作ること。 ■ 設計を決める2大指標(天秤) RPO(目標復旧時点): 過去のどの時点までのデータ消失なら許容できるか。(例:1日1回の取得なら、最大24時間分のデータを失う覚悟が必要) RTO(目標復旧時間): システム停止から何時間で復旧(再稼働)させるか。 ※守るべき「資産の価値」と「かけられるコスト(予算)」を天秤にかけて決定する。 ■ AWSが提供する自動バックアップ機能 RDS(PITR機能): 毎日のバックアップと変更履歴を組み合わせ、直近約5分前までの「秒単位での巻き戻し」が可能。 EBS(スナップショット): 変更された部分だけを効率よく保存(増分バックアップ)。ライフサイクルマネージャーを使えば「毎日取得・7日後削除」といった自動化が手放しで実現できる。 ■ インフラ設計における最大の鉄則 復元(リストア)テストの実施: バックアップは取って終わりではない。「いざという時に戻せないバックアップはゴミと同じ」である。 避難訓練: 定期的にわざとシステムを壊し、手順書通りに元に戻せるかテストを行うことが、一流のインフラ設計の必須条件。
【第5章】「サーバーなし」の衝撃:Lambdaで見直すアプリケーションの形

「家を管理する」という常識を捨てる選択肢
これまで4つの章をかけて、落雷にも耐え、セキュリティも完璧な「最強のサーバー(家)」を苦労して建ててきたあなたに、「用途によっては、その家を管理する苦労すら手放せる魔法がある」と告げられたら。これまでの常識を心地よく揺さぶる、次なる衝撃。
前章まで、私たちはVPCという土地を耕し、EC2という強固なサーバーを立ち上げ、RDSという絶対確実な金庫を守る方法を学んできました。それは間違いなくITインフラにおける王道であり、絶対に知っておくべき必須科目です。
しかし、時代はさらにその先の「選択肢」を用意しています。「OSのアップデートをしなきゃ」「急にアクセスが増えたからサーバーの台数を増やさなきゃ」……そんなインフラ管理者の眠れない夜を、過去の遺物へと変えてしまう画期的な技術。それが「サーバーレス」という概念であり、その中心で輝くのがAWS Lambda(ラムダ)です。
もちろん、従来のサーバーが消滅するわけではありません。しかし、サーバーという「箱」の管理から解放される圧倒的な身軽さが、アプリケーションの作り方、そしてビジネスのスピードをどう変革するのか。新時代を切り拓くためのパラダイムシフトを観ていきましょう。
本章で解説するステップは以下の3つです。
✅ 5-1 サーバーレスはなぜ魔法なのか?:イベント駆動アーキテクチャの基本
「画像が投稿された」「ボタンが押された」という出来事(イベント)をキッカケに、必要な一瞬だけプログラムが起動する魔法の仕組み。常時稼働の常識を捨てる「イベント駆動」の根本的な考え方を紐解きます。
✅ 5-2 小さく作って、大きく育てる:マイクロサービスの第一歩
巨大で複雑なシステムを、ひとつの大きな塊として作る時代は終わりました。機能を「小さな部品」に切り分けて組み合わせる、現代の開発手法「マイクロサービス」の入り口と、その圧倒的な開発スピードに迫ります。
✅ 5-3 コストパフォーマンスを極める:必要な時だけ動き、使った分だけ払う
24時間分の家賃(固定費)を払い続けるのはもうやめましょう。プログラムが実際に動いた「ミリ秒単位」の時間にだけ課金される、サーバーレス最大の魅力。圧倒的なコスト削減を実現する究極の従量課金を解説します。
サーバーの呪縛から解放され、本当に価値のある「開発」だけに集中する。圧倒的な身軽さと低コストを実現する次世代のアーキテクチャ設計術を、お伝えします。
サーバーの維持管理から解放される「サーバーレス」の世界へようこそ。24時間稼働の常識を捨て、必要な一瞬だけ動く「イベント駆動」という魔法の仕組みとは?
5-1 サーバーレスはなぜ魔法なのか?:イベント駆動アーキテクチャの基本

—— あなたが眠っている深夜3時、突然SNSであなたのブログが爆発的に拡散され、普段の1万倍の読者が押し寄せたとしたら。これまでのあなたなら、サーバーダウンの恐怖で飛び起きたはずです。しかし、今日からは違います。あなたはただ、朝までぐっすりと眠り続ければいいのです。
「家(サーバー)」を持たないという究極の身軽さ。
前章まで、私たちはEC2という強固な「家(サーバー)」を建ててきました。家を持てば、OSのアップデート(掃除)や、アクセス増加への対応(増築)といった「管理の手間」が必ず発生します。
しかし、AWS Lambda(ラムダ)をはじめとする「サーバーレス」の技術は、この常識を根底から覆します。誤解を恐れずに言えば、サーバーレスとは「物理的なサーバーが存在しない」わけではありません。「あなたが管理すべきサーバーが存在しない(AWSが裏側で全て管理してくれる)」という意味なのです。
—— 魔法の正体「イベント駆動(Event-Driven)」
では、自分専用の家を持たずに、どうやってプログラムを動かすのでしょうか?その答えが、本節の核心である「イベント駆動(イベントドリブン)」です。
これを最も直感的に理解するなら、「自動販売機」を想像してください。自動販売機は、普段は何の処理も行わず、ただ静かに待機しています。しかし、「お金が入れられ、ボタンが押された」という出来事(イベント)が発生した瞬間にだけ、内部のシステムがガシャンと動き出し、飲み物を出して、また静かな待機状態に戻ります。
これと同じように、Lambdaは「何かの出来事」をキッカケにして、必要な一瞬だけ魔法のように起動します。
-
キッカケの例1: 読者がS3(保管庫)に画像をアップロードした(イベント) ➡ 即座にLambdaが起動し、スマホ用の小さな画像を作成して保存する。
-
キッカケの例2: 毎日深夜2時になった(イベント) ➡ Lambdaが起動し、データベースの集計処理を行う。
-
キッカケの例3: DynamoDBに新しいデータが書き込まれた(イベント) ➡ Lambdaが起動し、管理者に通知メールを送信する。
—— インフラ管理者の三大苦労からの解放
この「出来事があった時だけ、必要な分だけ動く」という仕組みは、私たちインフラ設計者に圧倒的なメリットをもたらします。
-
OSの管理・保守がゼロ: WindowsやLinuxの面倒なセキュリティ対策や定期アップデートは、すべてAWSが代行してくれます。
-
無限の自動拡張(オートスケール): 冒頭でお話しした「深夜の急激なアクセス増加」が起きても大丈夫です。アクセスが1万倍になれば、AWSが勝手に裏側でLambdaを1万個同時に起動して処理をさばき切ってくれます。私たちが慌てて設定を変更する必要はありません。
-
インフラ構築から「純粋な開発」へのシフト: サーバーを立ち上げ、ネットワークを繋ぐという重労働が消滅します。エンジニアは「どんなサービスを作るか(コードを書くこと)」という、本来最も価値のある仕事だけに100%の情熱を注げるようになります。
サーバーの呪縛を手放し、出来事をキッカケに一瞬だけ起動して仕事を終わらせる魔法の小人、Lambda。これこそが、現代のアプリケーション開発を加速させる「イベント駆動」の真髄です。
出来事をキッカケに一瞬だけ起動し、無限に増殖して仕事を終わらせる魔法の小人、Lambda。このイベント駆動の仕組みを理解したあなたは、もう後戻りできない圧倒的な身軽さを手に入れました。次はこの小人たちの賢い働き方に迫ります。
次節は、『5-2 小さく作って、大きく育てる:マイクロサービスの第一歩』へ続きます。巨大で複雑な一つのシステムを作るのではなく、この魔法の小人たちをパズルのように組み合わせて、変化に強いしなやかなシステムを作る「現代の設計術」をご紹介します。お楽しみに!
■ 「サーバーレス」の本当の意味 物理的なサーバーが無いわけではなく、「自分たちが管理・運用すべきサーバーが存在しない」(すべてAWSが裏側で管理してくれる)状態のこと。 ■ 魔法の正体「イベント駆動(Event-Driven)」 自動販売機の仕組み: 普段は静かに待機し、「ボタンが押された」という出来事(イベント)が発生した瞬間にだけ稼働して結果を返す。 AWS Lambdaの動き: 「S3に画像がアップされた」「深夜2時になった」「DBに書き込まれた」などのキッカケに反応し、必要な一瞬だけ自動で起動する。 ■ インフラ管理からの解放(3つの絶大なメリット) OSの管理・保守がゼロ: OSのセキュリティ対策や定期アップデートなどの面倒な作業はAWSが完全代行。 無限の自動拡張(オートスケール): アクセスが突然1万倍になっても、AWSが自動でLambdaを1万個起動してさばき切るため、サーバーダウンの恐怖や設定変更の手間がない。 「純粋な開発」への集中: サーバーやネットワーク構築の重労働が消滅し、最も価値を生む「コードを書くこと(サービス開発)」に100%の情熱を注げる。
巨大なシステムを丸ごと作る時代は終わりました。機能を「小さな部品」に切り分け、Lambdaでパズルのように組み立てる。変化に強く、開発スピードを劇的に上げる「マイクロサービス」の設計術を解説します!
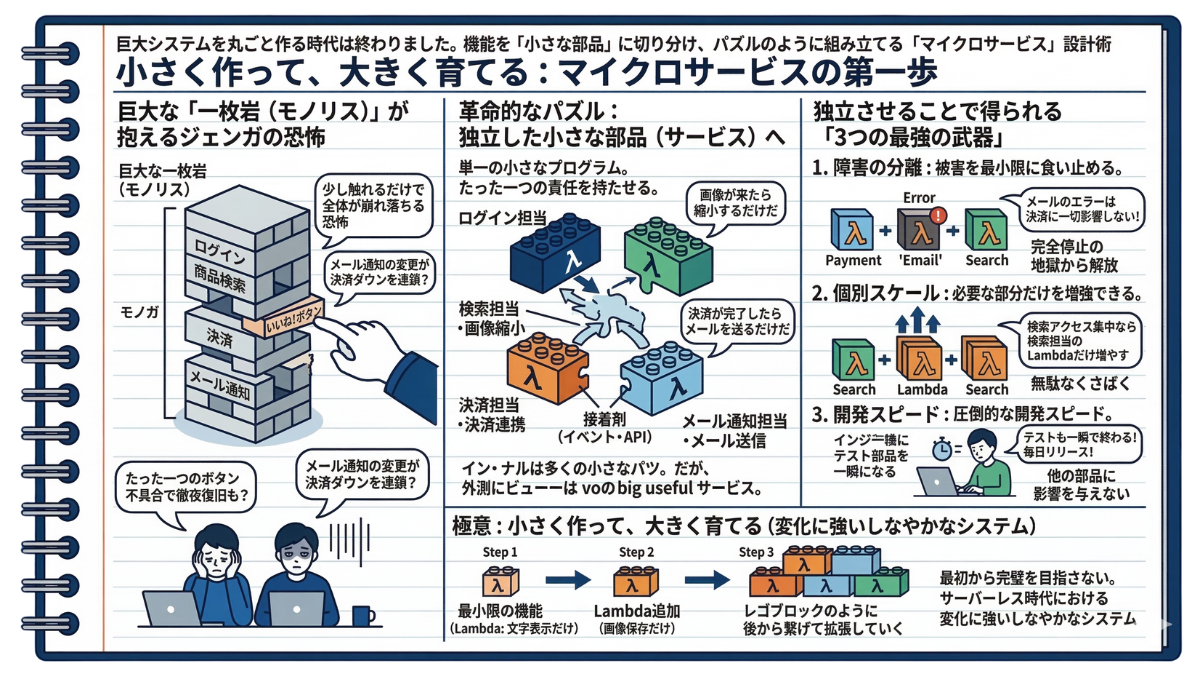
5-2 小さく作って、大きく育てる:マイクロサービスの第一歩
—— たった一つの小さな「いいね!」ボタンの不具合を直すために、システム全体の電源を落とし、何十人ものエンジニアが徹夜で復旧作業にあたる地獄の夜を。すべてが複雑に絡み合った巨大なシステムは、少し触れるだけで全体が崩れ落ちる「ジェンガ」のような恐怖を秘めているのです。
巨大な「一枚岩(モノリス)」が抱えるジェンガの恐怖。
これまで、Webサービスを作る時は、ログイン機能、商品検索、決済、メール通知など、すべての機能をひとつの巨大な箱(プログラム)に詰め込むのが当たり前でした。これをIT用語で「モノリス(一枚岩)」と呼びます。
しかし、この一枚岩には致命的な弱点があります。すべてが密接に絡み合っているため、「メール通知の文章を少し変えただけなのに、なぜか決済システムが連鎖的にダウンした」という悪夢が日常茶飯事に起こるのです。どこか一つをいじれば全体が崩れ落ちかねない、恐怖と隣り合わせの開発でした。
—— 「マイクロサービス」という革命的なパズル
この恐怖を終わらせる現代の設計術が「マイクロサービス」です。 システムを巨大な一枚岩として作るのではなく、「ログイン担当」「検索担当」「決済担当」といった具合に、機能ごとに独立した小さな部品(サービス)に切り分けて開発します。
これこそが、前節で学んだイベント駆動の要「Lambda」が最も輝く舞台です! Lambdaは「必要な一瞬だけ動く、単一の小さなプログラム」を作るのに最適です。一つひとつのLambdaに「君は画像が来たら縮小するだけだ」「君は決済が完了したらメールを送るだけだ」と、たった一つの責任を持たせます。
そして、ここからが重要です。分割した部品たちはバラバラに動くわけではありません。前節で学んだ「イベント(出来事)」や、「API」と呼ばれる通信の仕組みを「接着剤」として使い、Aの作業が終わったらBへバトンを渡すように連携させます。これにより、内部は小さな部品の集まりでありながら、ユーザーからは「ひとつの巨大で便利なサービス」として見えるのです。
—— 小さく作ることで得られる「3つの最強の武器」
システムを小さく独立させて切り分けることで、インフラには劇的な変化が訪れます。
-
被害を最小限に食い止める(障害の分離): もし「メール通知」のLambdaがエラーを起こして倒れても、それは完全に独立した部品なので「決済」や「商品検索」の機能には一切影響を与えません。システム全体が完全停止する地獄から解放されます。
-
必要な部分だけを増強できる(個別スケール): 「検索機能」だけが異常にアクセス集中した場合、昔はシステム全体が入った巨大な箱をまるごと増やすしかありませんでした。しかしマイクロサービスなら、「検索担当のLambda」だけを自動で大量に増殖させ、無駄なくさばき切ることができます。
-
圧倒的な開発スピード: 「この小さな部品だけ新しく作り直そう」という決断が即座にできます。他の部品に影響を与えないため、テストも一瞬で終わり、毎日でも安全に新しい機能をリリースできるようになります。
—— 極意。最初は小さく、後から大きく育てる
最初から完璧で巨大なシステムを作ろうとしないでください。 まずは「文字を表示するだけ」「画像を保存するだけ」という最小限の機能(Lambda)をひとつ作りましょう。そこから必要に応じて、決済の部品、通知の部品と、レゴブロックのように後から繋げて拡張していく。「小さく作って、大きく育てる」。これこそが、サーバーレス時代における変化に強いしなやかなシステムの絶対法則です。
巨大な一枚岩を砕き、独立した小さな歯車を精巧に組み合わせるマイクロサービス。Lambdaたちをバトンリレーのようにつなげば、この柔軟で強靭なシステムを圧倒的なスピードで構築できます。
次節は、この優秀な歯車たちの「お給料」の秘密に迫ります。『5-3 コストパフォーマンスを極める:必要な時だけ動き、使った分だけ払う』へ続きます。 24時間稼働の固定費から完全に解放され、プログラムが実際に動いた「ミリ秒単位」で課金される、サーバーレス最大の魅力である究極のコストカット術を解説します。
■ 従来の「モノリス(一枚岩)」の限界 ジェンガの恐怖: 全機能を1つの巨大な箱に詰める古い設計。一部を修正しただけでシステム全体が連鎖的に崩れ落ちる危険性がある。 ■ 現代の設計術「マイクロサービス」とは パズル型の設計: システムを「ログイン担当」「決済担当」など、機能ごとに独立した小さな部品に切り分けて作る手法。 Lambdaと接着剤: Lambdaに「たった一つの責任」を持たせ、部品同士を「イベント」や「API」という接着剤(バトンリレー)で連携させる。 ■ 小さく切り分ける「3つの最強の武器」 被害を最小限に食い止める(障害の分離): 1つの部品がエラーを起こしても他の機能は無事で、システム全体の完全停止を防げる。 必要な部分だけ増強(個別スケール): アクセスが集中した機能(例:検索だけ)をピンポイントで自動増殖させ、無駄なくさばき切れる。 圧倒的な開発スピード: 他の部品に影響を与えないため、テストが一瞬で終わり、安全かつスピーディに新機能を追加・修正できる。 ■ サーバーレス時代の絶対法則 「小さく作って、大きく育てる」: 最初から巨大な完成品を目指さず、最小限の機能を作り、後からレゴブロックのように繋げて拡張していく。
無駄な家賃を払い続けるのは今日で終わりにしましょう。プログラムが動いた「ミリ秒単位」で課金される、AWS Lambda最大の魅力。サーバーレスが実現する究極のコストカット術を。
5-3 コストパフォーマンスを極める:必要な時だけ動き、使った分だけ払う
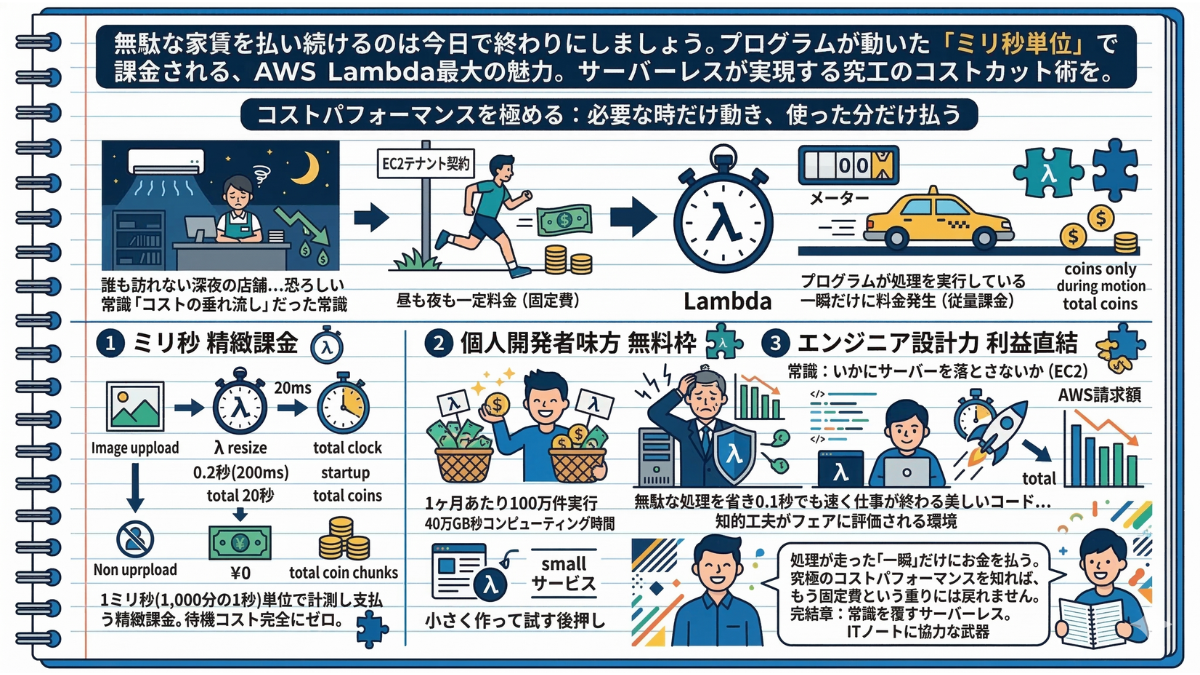
—— 誰も訪れない深夜の店舗。しかし、クーラーは全開で回り続け、店員はレジの前で直立不動のまま時給を消費し続けている……。もしあなたが経営者なら、この光景を見てどう思いますか?これまで私たちが常識だと信じて疑わなかった「サーバーの24時間稼働」は、実はこれと同じくらい恐ろしい「コストの垂れ流し」だったのです。
「家賃(固定費)」から「タクシー代(従量課金)」へのパラダイムシフト。
第2章で構築したEC2(サーバー)は、例えるなら「月極のテナント契約」です。昼間のピークタイムだろうが、誰もアクセスしてこない深夜だろうが、起動している限り常に一定の料金(家賃)が発生し続けます。システムを24時間走り続けるフルマラソンのように稼働させることは、安心感と引き換えに多額の固定費を伴っていました。
しかし、サーバーレス(Lambda)の課金モデルは全く異なります。これは「タクシーのメーター」をイメージしてください。お客さんが乗って、タイヤが転がっている(プログラムが処理を実行している)その瞬間にしか、料金は1円も発生しません。
ステップ1:究極の無駄を省く「ミリ秒単位」の精緻な課金
Lambdaの料金計算は、もはや「時間」や「分」という概念すら超越しています。プログラムが実行された時間を「1ミリ秒(1,000分の1秒)単位」で計測し、その分だけを支払うという、常軌を逸した精緻な従量課金システムを採用しているのです。
例えば、画像がアップロードされた時に「0.2秒(200ミリ秒)」だけ起動して画像を縮小するLambdaを作ったとします。この処理が1日に100回行われたとしても、課金されるのは「1日あたり合計たったの20秒分」だけ。誰も画像をアップロードしなかった日は、堂々の「請求額0円」です。待機時間に対するコストは完全にゼロになります。
ステップ2:個人開発者の味方、驚異の「無料枠」
そして、初級〜中級のインフラ設計者にとって最も嬉しい衝撃の事実をお伝えしましょう。AWS Lambdaには、毎月リセットされるとてつもない規模の「無料利用枠」が最初から用意されています。
なんと、「1ヶ月あたり100万件の実行」かつ「40万GB秒のコンピューティング時間」までは、永年無料で使い放題なのです。個人のブログや、立ち上げたばかりの小規模なWebサービスであれば、この無料枠を使い切ることすら困難です。「まずは小さく作って試す」という前節のマイクロサービスの極意を、コスト面から強力に後押ししてくれる最強の味方と言えます。
ステップ3:エンジニアの「設計力」が利益に直結する世界
これまでは、「いかにサーバーを落とさないか」がインフラエンジニアの腕の見せ所でした。しかし、サーバーレスの世界では「いかにプログラムの処理時間を短く(速く)するか」が、そのままダイレクトに「コスト削減(利益)」へと直結します。
無駄な処理を省き、0.1秒でも速く仕事が終わる美しいコードを書けば書くほど、毎月のAWS請求額が目に見えて安くなっていく。技術者の知的な工夫が、これほどフェアに評価される環境は他にありません。
処理が走った「一瞬」だけにお金を払う。この究極のコストパフォーマンスを知れば、もう固定費という重りには戻れません。これにて、常識を覆すサーバーレスの章は完結です。あなたのITノートに、また一つ強力な武器が書き込まれましたね。
次回は新章へ。『【第6章】プロの道具箱:運用・保守を「自動化」して自由を手に入れる』へ続きます。 構築したインフラの監視やバックアップを全自動化し、エンジニアが本当の「自由な時間」を手に入れるための実践的なテクニックを公開します。
■ 固定費から完全従量課金へのシフト EC2(月極テナント契約): 誰もアクセスしない深夜でも、24時間「家賃」が発生し続ける。 Lambda(タクシーのメーター): プログラムが処理を実行している「タイヤが転がっている瞬間」しか料金が発生しない。待機中のコストは完全なゼロ。 ■ 究極のコストカット「3つの真髄」 「1ミリ秒単位」の精緻な課金: 実行時間を1,000分の1秒単位で計測。例えば0.2秒の処理なら、1日100回実行されても合計20秒分しか課金されない。 驚異の「永年無料枠」: 毎月「100万件の実行」かつ「40万GB秒の計算時間」が無料で使い放題。個人のブログや小規模サービスなら、この無料枠だけで運用できる可能性が高い。 エンジニアの設計力=利益(コスト削減): 「いかにサーバーを落とさないか」から、「いかに処理を0.1秒でも速く終わらせるか」へ評価軸が変化。無駄のない美しいコードを書くほど、毎月のAWS請求額がダイレクトに安くなる。
【第6章】プロの道具箱:運用・保守を「自動化」して自由を手に入れる
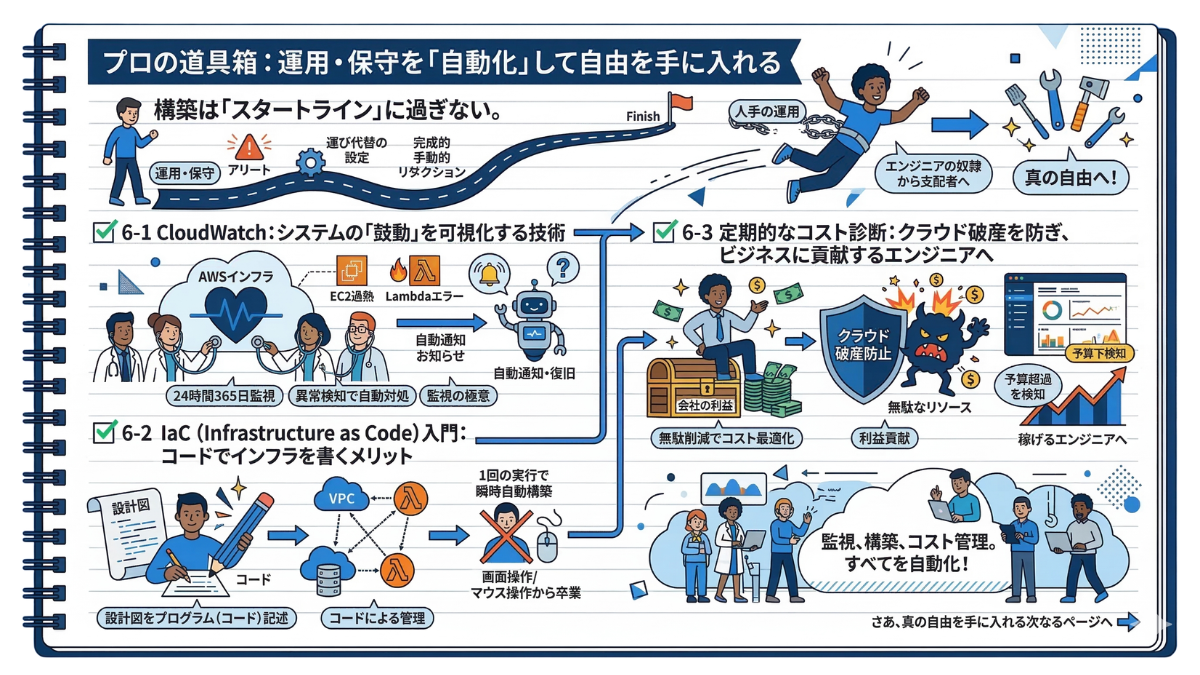
構築は「スタートライン」に過ぎない。
週末の穏やかな午後、突然スマートフォンに鳴り響く障害発生のアラート音。あるいは、複雑化するインフラ環境に同じ設定を手作業で繰り返し打ち込む、終わりの見えない単純作業の連続……。もしあなたが今、システムの維持管理に追われて「自分の時間」を奪われているなら、この章はあなたを救う希望の光となるはずです。
これまでの章で、私たちは堅牢なネットワーク(VPC)を築き、サーバー(EC2)を立ち上げ、時にはサーバーレス(Lambda)という魔法すら使いこなすまでに成長しました。あなたには、システムをゼロから生み出す確かな技術力が刻み込まれています。
しかし、システムの構築はあくまでスタートラインに立ったに過ぎません。サービスがリリースされたその瞬間から、例えるなら遠いゴールを目指して休むことなく走り続けるような、過酷で長い「運用・保守」という長距離走が幕を開けるのです。
—— 「人間の手」による運用からの脱却
前章でサーバーレスの身軽さを学びましたが、現実のシステムはEC2、RDS、Lambdaなどが複雑に連携するハイブリッド環境です。多くの初心者が陥る罠は、この入り組んだシステム全体の監視やメンテナンスを「人間の手と目」という己の体力のみに頼ってしまうこと。
画面に張り付いてエラーを探し、手動で環境を複製し、月末の請求書を見て青ざめる……。そんな労働集約型の運用は、エンジニアとしての貴重な時間と気力を確実に削り取ってしまいます。
一流のインフラエンジニアは、決して力技でシステムを守りません。彼らは「プロの道具箱」から適切なツールを取り出し、すべての運用を「自動化」することで、圧倒的な自由を手に入れているのです。本章では、人間がやるべきではない退屈でミスの起きやすい作業をAWSに丸投げし、あなたが本当に価値のある創造的な仕事に集中するための実践テクニックを解説します。
本章で解説するプロの道具箱は、以下の3つです。
✅ 6-1 CloudWatch:システムの「鼓動」を可視化する技術
24時間365日、あなたに代わってシステム全体の健康状態を監視する専属の主治医「CloudWatch」。サーバーの異常な発熱からLambdaのエラー兆候までを瞬時に検知し、自動で通知・復旧させる監視の極意を解説します。
✅ 6-2 IaC(Infrastructure as Code)入門:コードでインフラを書くメリット
画面操作(マウス)での手作業はもう卒業です。VPCからサーバーレスまで、インフラ全体の設計図を「プログラム(コード)」として記述し、たった1回の実行で全く同じ環境を何度でも一瞬で自動構築する「IaC」の衝撃をお届けします。
✅ 6-3 定期的なコスト診断:クラウド破産を防ぎ、ビジネスに貢献するエンジニアへ
構築して放置した無駄なリソースが招く「クラウド破産」の恐怖。予算超過を未然に防ぐ自動アラート機能や、コスト最適化ツールを活用し、会社の利益に直結する「稼げるエンジニア」への道を示します。
監視、構築、そしてコスト管理。これら全てを自動化するプロの道具箱を開けば、あなたは「インフラの奴隷」から「インフラの支配者」へと劇的に進化します。さあ、真の自由を手に入れる次なるページを開きましょう!
システムは生き物です。その「鼓動」を24時間365日見守り、異常があれば即座に知らせてくれる専属の主治医。属人的な目視確認からあなたを解放する「Amazon CloudWatch」の極意をノートに刻みます。
6-1 CloudWatch:システムの「鼓動」を可視化する技術
—— 自分の心拍数もペースも全く見えない状態で、マラソンを完走できるでしょうか? おそらく、ペース配分を誤り、途中で限界を超えて倒れてしまうはずです。システム運用も全く同じです。サーバーというランナーが今、どれくらい息を切らしているのか。その「見えない疲労」を可視化し、倒れる前に手を打つ。それがプロのインフラエンジニアの第一歩です。
見えない疲労を放置する恐怖。
EC2やRDSを立ち上げ、無事にサービスを公開できた。しかし、アクセスが増えてきた時、裏側でサーバーがどれだけ悲鳴を上げているか、あなたは把握できているでしょうか?
「サイトが重い」「エラー画面が出た」と、ユーザーからのクレームが入って初めて障害に気づく。これは、ランナーが脱水症状のサインを無視し続け、完全に意識を失って倒れてから慌てて救急車を呼ぶのと同じくらい手遅れな状態です。エンジニアの「勘」や「目視」に頼った運用は、いつか必ず大事故を引き起こします。
ステップ1:システムの「心拍計」を取り付ける(メトリクス)
そこで登場するのが、AWSが誇る監視サービス「Amazon CloudWatch(クラウドウォッチ)」です。
CloudWatchは、システム全体に取り付ける「高機能なスマートウォッチ」のようなものです。EC2の「CPU使用率(どれくらい頭を使っているか)」や、ネットワークの「通信量(どれくらいデータが出入りしているか)」といった様々な健康状態のデータ(これをメトリクスと呼びます)を、自動的に収集して美しいグラフにしてくれます。黒い画面(ターミナル)を睨み続けなくても、ダッシュボードを見れば、システムの「鼓動」が一目で分かるようになるのです。
ステップ2:倒れる前に知らせる「アラーム機能」
しかし、グラフ化するだけでは不十分です。私たちは24時間ずっとランナーの心拍計を見張っているわけにはいきません。そこでCloudWatchの真骨頂である「アラーム機能」を設定します。
「CPU使用率が80%を超えた状態が5分間続いたら、管理者のスマートフォンに緊急通知(メールやSlackなど)を送る」といったルールを直感的に作ることができます。これにより、ユーザーが異常に気づくよりも前に、「少し息が上がってきたな」という予兆の段階で給水(サーバーを増やすなど)を行うことが可能になります。
ステップ3:ログの集約で「倒れた原因」を秒速で特定する
万が一システムがダウンしてしまった時、最も時間がかかるのが「なぜ倒れたのか?」という原因究明です。何台もあるサーバーに一つずつログインして、膨大な記録を探し回るのは至難の業です。
CloudWatch Logsという機能を使えば、すべてのサーバーやLambdaから吐き出されるログ(詳細な活動記録やエラーのカルテ)を、一箇所に集めて保存・検索することができます。まるで、すべてのランナーのバイタルデータを一つの医務室で一括チェックできるようなものです。エラーのキーワードで検索すれば、瞬時に「いつ・どこで・何が起きたか」を特定し、迅速な治療(復旧)にあたることができます。
見えないインフラの動きを可視化し、異常を自動で知らせる。CloudWatchという主治医を手に入れたことで、あなたはもう監視画面に張り付く必要はありません。安心して、今夜はぐっすりと眠りについてください。
次節は、『6-2 IaC(Infrastructure as Code)入門:コードでインフラを書くメリット』へ続きます。マウスでポチポチと設定画面をクリックする手作業からついに卒業。インフラの設計図を「プログラム」として書き、何度でも一瞬で同じ環境を魔法のように自動構築するIaCの世界へご案内します!
■ 監視なき運用の危険性 ユーザーからのクレームで障害に気づくのは手遅れ。サーバーの疲労を可視化せず「エンジニアの目視や勘」に頼る運用は、いつか必ず致命的なシステムダウン(ランナーの昏倒)を招く。 ■ CloudWatchの3つの強力な機能(主治医の道具) メトリクス(心拍計と可視化): CPU使用率や通信量などの健康データを自動で収集し、グラフ化。黒い画面を睨まずとも、システムの「鼓動(負荷状況)」がダッシュボードで一目でわかる。 アラーム機能(異常の事前通知): 「CPU80%超えが5分継続」などのルールに基づき、管理者のスマホ(Slackやメール等)へ自動通知。システムが倒れる前に「給水(サーバー増強など)」の予防処置が可能になる。 CloudWatch Logs(カルテの一元管理): 全サーバーやLambdaのログ(活動記録・エラー)を1箇所に集約。万が一の障害時も、各サーバーを巡回することなくキーワード検索で「倒れた原因」を秒速で特定できる。 ■ 最大のメリット 24時間365日の監視体制をAWSに任せることで、エンジニアは「監視画面に張り付く労働」から解放され、夜も安心して眠ることができる。
マウスでポチポチ設定する手作業の時代は終わりました。インフラの設計図を「コード(設定ファイル)」として記述し、何度でも一瞬で完璧に同じ環境を複製する魔法、「IaC」の絶大なメリットを解説します!
6-2 IaC(Infrastructure as Code)入門:コードでインフラを書くメリット
—— 「あの時はうまく動いたのに、新しく作り直したらなぜか繋がらない…」徹夜でAWSの設定画面を睨みつけ、過去の自分の記憶と格闘した経験はありませんか? 人間の「手作業」と「記憶」に依存したインフラ構築は、いつか必ず致命的なミスを引き起こす時限爆弾なのです。
「秘伝のタレ」化したインフラの限界。
これまで私たちは、AWSの管理画面(マネジメントコンソール)を開き、マウスをクリックしながらVPCを作り、EC2を立ち上げてきました。初学者が直感的に学ぶには最高のステップですが、これを実際のビジネスの現場で続けると恐ろしい事態に陥ります。
「どの画面で、どのボタンを押して、どの数値を入力したか」という構築の手順が、作業した担当者の頭の中にしか残らないのです。これを業界では、作り方が誰にも分からない「秘伝のタレ」と呼びます。もしその担当者が退職してしまったら?本番環境と全く同じテスト環境をもう一つ作ってほしいと頼まれたら?記憶を頼りに手作業で全く同じものを寸分狂わず再現するのは、もはや不可能に近い神業となってしまいます。
—— 魔法の設計図「IaC(Infrastructure as Code)」とは
この手作業の呪縛から私たちを解放する革命的な技術が、「IaC(Infrastructure as Code:インフラのコード化)」です。AWS CloudFormationやTerraformといったツールが有名です。
「コード」と聞くと、難解なプログラミングを想像して身構えてしまうかもしれません。しかし、安心してください。IaCの多くは、複雑なロジックを組むのではなく、「人間が読んで理解しやすい設定ファイル(YAML形式など)」を書くだけです。
まるで料理のレシピのように、「VPCを1つ作る」「その中にEC2を2台置く」「セキュリティグループで80番ポートを開ける」と、最終的に欲しい状態を箇条書きのテキストで書き残します。そして、そのファイルを読み込ませると、AWSが自動的にレシピ通りのインフラを一瞬で組み上げてくれるのです。
—— IaCがもたらす「3つの絶大なメリット」
インフラをコード(テキスト)化することで、私たちの働き方は劇的に進化します。
-
究極の再現性(何度でも一瞬でクローンを作成): レシピさえあれば、魔法のコピー機のように「全く同じインフラ環境」を何度でも一瞬で作り出すことができます。開発環境、テスト環境、本番環境のズレがなくなり、「テスト環境では動いたのに、本番環境では動かない」という悪夢が完全に消滅します。
-
バージョン管理と過去へのタイムトラベル: テキストファイルであるため、Gitなどのツールを使って「誰が・いつ・どこを・なぜ変更したか」という履歴をすべて保存できます。もし設定変更で障害が起きても、ボタン一つで「昨日の安全な状態(過去のコード)」へと一瞬でロールバック(巻き戻し)できる無敵の安心感を手に入れられます。
-
属人化の排除(コードが最高の仕様書になる): 「どう設定されているか」はすべてコードに書かれています。退職した先輩の記憶を探る必要はありません。コードそのものが「絶対に嘘をつかない最新の仕様書」として機能し、チーム全員で安全にインフラを育てていくことができるのです。
インフラはもう、職人の手で作る芸術作品ではありません。誰もが安全に再現できる、精巧な工業製品へと進化を遂げたのです。
インフラをコード化するIaCは、エンジニアから手作業の苦痛を奪い、何度でも完璧に環境を蘇らせる「不老不死の魔法」です。この強力な設計図を手に入れたあなたは、もう二度と過去の記憶に怯えることはありません。
次節は、『6-3 定期的なコスト診断:クラウド破産を防ぎ、ビジネスに貢献するエンジニアへ』へ続きます。 構築、監視、自動化と進んできた私たちが最後に直面する「お金」のリアル。知らずに放置したリソースが招く悲劇を防ぎ、利益を生み出すためのコスト管理術を大公開します。
■ 手作業によるインフラ構築の危険性(秘伝のタレ化) マウス操作での構築は担当者の記憶に依存し、作り方が誰にも分からなくなる。 担当者の退職時や、全く同じテスト環境の複製が必要な際に、寸分狂わず再現することがほぼ不可能になる。 ■ IaC(Infrastructure as Code)とは インフラの構成を「人間が読みやすい設定ファイル(YAML形式など)」としてテキストで書き残す技術(CloudFormationやTerraformなど)。 複雑な開発スキルは不要で、料理のレシピのように「VPCを1つ、EC2を2台」と箇条書きにするだけで、AWSが自動で構築してくれる。 ■ IaCを導入する3つの絶大なメリット 究極の再現性(一瞬でクローン作成): 全く同じインフラ環境を何度でも自動生成でき、テスト環境と本番環境のズレによるトラブルを完全に根絶できる。 バージョン管理とタイムトラベル: Git等で変更履歴をすべて保存でき、万が一設定ミスが起きても、ボタン一つで過去の安全な状態へ巻き戻し(ロールバック)できる。 属人化の排除(最高の仕様書): コードそのものが「絶対に嘘をつかない最新の仕様書」となり、個人の記憶に頼らずチーム全員で安全に運用できる。
技術力だけでは生き残れない。月末の請求書に怯える「クラウド破産」の恐怖を断ち切り、無駄なコストを削ぎ落としてビジネスの利益に直結させる「稼げるインフラエンジニア」への最短ルートを、新たなページに刻み込みましょう。
6-3 定期的なコスト診断:クラウド破産を防ぎ、ビジネスに貢献するエンジニアへ
—— ある朝、目を覚ますとクレジットカード会社から「100万円の請求」を知らせるメールが届いている……。これは都市伝説ではなく、クラウドの世界で初心者が必ず一度は直面しかける「クラウド破産」というリアルな悪夢です。システムは完璧に動いているのに、あなたの銀行口座は致命傷を負ってしまう。この理不尽な恐怖から逃れる術を、今すぐ身につけましょう。
「運用フェーズ」に潜む、見えないコストの罠。
第5章で学んだ「サーバーレス(Lambda)」は構造的にコストを抑える設計術でした。しかし、実際の現場はEC2やRDSも入り混じる複雑なハイブリッド環境です。運用フェーズに入ると、設計時には見えなかった「人間による管理の隙」が必ず生まれます。
テスト用に立ち上げたハイスペックなEC2インスタンスの消し忘れ、使われなくなった古いRDSのバックアップデータ、とりあえず確保したまま放置されているIPアドレス。これらは、誰も見ていないのに毎月引き落とされ続ける「幽霊サブスクリプション」と同じです。家計の無駄遣いなら数千円で済みますが、クラウド環境での放置は、たった数日で数十万円の請求となって襲いかかってきます。
ステップ1:AWS Budgetsで「絶対防波堤」を築く
この悪夢を防ぐための最初の自動化ツールが「AWS Budgets(バジェット)」です。
これは、あなたのアカウントに「予算の防波堤」を作る機能です。「今月のAWS利用料金が3,000円を超えそうになったら、即座にスマホへ緊急アラート通知を送る」といった設定が数分で完了します。優秀な家計簿アプリが予算オーバーを警告してくれるのと同じように、AWSが24時間体制でコストの上限を見張ってくれます。
ステップ2:機械学習が異常を察知する「Cost Anomaly Detection」
予算の防波堤を作っても、DDoS攻撃やプログラムのバグ(Lambdaの無限ループなど)によって、たった数時間で異常な課金が発生することがあります。
ここでプロが使うのが「AWS Cost Anomaly Detection(コスト異常検出)」です。これは機械学習を用いた最新のツールで、あなたの普段の利用パターンをAIが学習し、「いつもと違う不自然なお金の動き」を検知した瞬間にアラートを飛ばしてくれます。予算に到達するのを待たずに、被害を最小限のボヤ騒ぎで食い止める強力な煙探知機です。
ステップ3:Cost Explorerで「メタボ(無駄)」を特定する
守りを固めたら、次は「AWS Cost Explorer(コストエクスプローラー)」を開きましょう。
これは、クラウド上の支出を美しくグラフ化してくれる強力な分析ツールです。「このEC2は夜間誰もアクセスしないから、自動で電源を落とそう」「このS3の古い画像データは、より安い保管庫(Glacier)に移動させよう」といった具合に、システムの贅肉(メタボ)を可視化し、的確に削ぎ落としていくことができます。
—— エンジニアの真の価値は「ビジネスの利益を生むこと」
インフラエンジニアの仕事は、ただサーバーを動かすことではありません。
月に10万円の無駄なインフラコストを見つけ出し、最適化してゼロにしたとしましょう。それは、会社にとって「毎月10万円の純利益を新しく生み出した」ことと全く同じ価値を持ちます。技術力に加えて、この「お金の感覚」を持ったエンジニアは、経営陣から最も信頼される圧倒的な武器を手に入れたことになります。システムを安定稼働させながら、徹底的に無駄を省き、ビジネスの利益を最大化する。これこそが、プロの道具箱を使いこなすインフラエンジニアの真の姿なのです。
無駄なリソースを削ぎ落とし、利益を生み出すコスト最適化術。これこそが、単なる「作業者」からビジネスを牽引する「プロフェッショナル」へとあなたを押し上げる最後の武器です。コストの不安を払拭し、真の自由を手に入れましょう。
いよいよ、この壮大な連載も次が最後の章です。『【終章】技術の先にある、あなたの価値』へ続きます。 ゼロからインフラを学び、サーバーレスの魔法を知り、自動化の武器を手に入れたあなた。これらの知識が、今後の人生とキャリアをどう変えていくのか。
■ 運用フェーズに潜む「見えないコスト(幽霊サブスク)」の罠 構築完了後、消し忘れたテスト用EC2や古いバックアップデータなどが放置されると、数日で数十万円の高額請求(クラウド破産)を引き起こす危険性がある。 ■ コストを守り、最適化する3つのステップ AWS Budgets(予算上限のアラート): 月の予算(例:3000円)を超えそうになったらスマホへ事前通知。家計簿アプリのように支出の上限を監視する「絶対防波堤」。 Cost Anomaly Detection(AIによる異常検知): 機械学習が普段の利用パターンを学習し、DDoS攻撃やバグ等による「急激で不自然な課金」を瞬時に検知。被害をボヤ騒ぎで食い止める強力な「煙探知機」。 Cost Explorer(無駄の可視化と削減): 支出状況をグラフ化。利用していない夜間のサーバー停止や、古いデータの安価な保管庫への移動など、システムの「贅肉(メタボ)」を的確に削ぎ落とす。 ■ エンジニアが持つべき「経営視点」 サーバーをただ動かすだけでなく、「月10万円の無駄なコストを削る=月10万円の純利益を新しく生み出す」というお金の感覚を持つことが重要。 コスト最適化ができるエンジニアは、単なる作業者からビジネスの利益を最大化する「経営陣の頼れるパートナー」へと圧倒的に価値が高まる。
【終章】技術の先にある、あなたの価値
未知の用語に戸惑いながらページをめくったあの日から、あなたは確かな力を手に入れました。技術を単なる「道具」から、あなた自身の「市場価値」へと昇華させる最後の授業を始めましょう。
息を切らしながら走り抜けた、長くて険しいインフラ構築。ついにそのゴールテープを切る瞬間がやってきました。しかし、振り返って構築したシステムを見渡した時、あなたは気づくはずです。私たちがこれまでの章で本当に作っていたのは「サーバー」ではなく、あなた自身の「揺るぎない市場価値」であったことに。
—— 「技術力」はもう、ゴールではない
VPCという見えないネットワークの壁を手探りで構築した第1章。サーバーレスという常識を覆す魔法に触れ、自動化というプロの道具箱を手に入れた第6章。ここで共に学び、実際に手を動かしながらあなたが書き留めてきた「ITノート」には、もはや初学者の頃の迷いはありません。設計図を読み解き、自らの力でクラウド上に堅牢なシステムを立ち上げる確かな実力が備わっています。
しかし、インフラエンジニアとしての真の評価は「AWSの操作ができること」では決まりません。クラウドが当たり前となった現代において、技術はあくまで手段に過ぎません。その手に入れた技術を使って、「ビジネスの成功」にどうコミットできるかが、これからの激動のIT業界を生き抜く絶対条件となります。
本章では、技術書には決して書かれていない「エンジニアとしてのキャリア戦略」と「価値の最大化」について、以下の2つの視点から紐解いていきます。
✅ AWSを学ぶことは、ビジネスの構造を学ぶこと
インフラの設計図は、そのまま企業の「ビジネスモデル」を映し出す鏡です。コスト最適化やセキュリティ要件を通して、経営者と同じ視座でビジネスの利益に貢献する「提案型エンジニア」への進化を解説します。
✅ 学び続けるためのコミュニティと、次なる「ITノート」の執筆
技術の進化は止まりません。孤独な学習から抜け出し、仲間と繋がりましょう。そして何より重要なのは、あなたがここまで書き溜めてきた「ITノート」の知識を、今度は自らの言葉で世界へ発信(アウトプット)することです。あなたが誰かのために綴る新たなページこそが、技術を血肉に変え、市場価値を永続的に高める最強のループとなります。
最後のページをめくる準備はよろしいですか?コードや設定画面の先にある、エンジニアとしての「本当の価値」。技術をビジネスの力に変え、あなた自身のキャリアを劇的に飛躍させる答えが見つかるでしょう。
サーバーを立てる技術だけでは、AIに代替される時代。インフラの設計図に隠された「企業のビジネスモデル」を読み解き、経営視点を持つ圧倒的な市場価値を手に入れるためのパラダイムシフトをお届けします。
AWSを学ぶことは、ビジネスの構造を学ぶこと
—— 「君は、何のためにこのサーバーのスペックを上げたんだ?」もし経営陣からそう問われた時、「アクセスが増えてCPU使用率が上がったからです」としか答えられないのなら、あなたのエンジニアとしての価値はそこで頭打ちになります。インフラの設計図は、単なるITの配線図ではありません。それは、その企業が「どうやってお金を稼ぎ、何を守ろうとしているのか」を生々しく描き出した、ビジネスの構造そのものなのです。
構成図は「企業の家計簿」である。
これまで学んできたAWSのサービスを思い出してください。EC2、RDS、Lambda……。これらをどう組み合わせるかというアーキテクチャ設計は、そのまま「企業の投資戦略」に直結します。
例えば、24時間稼働を前提として重厚なEC2を立ち上げるのか、それとも第5章で学んだミリ秒単位で課金される身軽なLambdaを選ぶのか。これは単なる技術的な好みの問題ではありません。「固定費を許容して安定を狙うか、変動費にしてリスクを抑えるか」という、経営者のキャッシュフロー戦略そのものです。AWSの構成図を引くことは、企業の家計簿をデザインすることと同義なのです。
—— 可用性(Multi-AZ)とは「ビジネスの保険」である
第3章で、私たちは複数のデータセンターにサーバーを分散させる「Multi-AZ(マルチAZ)」という技術を学びました。技術的にはこれを「冗長化」と呼びますが、ビジネスの視点から見れば、これは「高額な保険」です。
「もしシステムが1時間止まったら、このECサイトは数百万円の売上と顧客の信頼を失う。だから、月額数万円のインフラコストを余分に払ってでも、サーバーを2台に増やすべきだ」。このように、技術による解決策(Multi-AZ)と、ビジネスの損失リスク(売上低下)を天秤にかけ、経営にとって最もコストパフォーマンスの良い落とし所を提案できるエンジニアこそが、真のプロフェッショナルです。
—— 「作業者」から「提案型パートナー」への劇的な進化
設定画面の手順を暗記しているだけの「作業者」は、これからの時代、AIや自動化ツール(IaC)に容易に取って代わられてしまうでしょう。
しかし、「この新規事業はまだ予算が少ないから、まずは初期投資ゼロのサーバーレスで小さく始めましょう。軌道に乗ったら、本格的な構成に移行しましょう」と、ビジネスの成長曲線に寄り添ってインフラの形を変幻自在に操れる「提案型パートナー」の価値は、決して揺らぐことはありません。
AWSを学ぶ本当の意義は、コマンドを叩けるようになることではありません。ITの力を使って、「ビジネスを勝たせるための強靭な構造」を描けるようになることなのです。
技術の裏にある「お金とリスクの動き」が見えるようになった時、あなたの目の前に広がる景色は一変します。インフラの知識を武器に、経営陣と肩を並べてビジネスを牽引する。そんなワクワクする未来はもう目の前です。
孤独な学習は今日で終わりにしましょう。手に入れた知識を真の武器に変えるのは、仲間との繋がりと自らの言葉による発信です。「ITノート」の最後のページに刻む、市場価値を永続させる最強のループとは。
学び続けるためのコミュニティとアウトプットの重要性
—— 最新のCPUを積み、完璧な冗長化を施した最強のサーバーを構築しても、外部からの通信(ポート)をすべて閉じたままでは、その存在を世界中の誰も知ることはできません。技術者のスキルもこれと全く同じです。画面の向こう側のAWSとどれだけ高度な対話ができても、それを「人間の言葉」として外部へ公開(アウトプット)しなければ、あなたの市場価値は誰の目にも留まらず、ひっそりと埋もれてしまうのです。
孤独な学習からの脱却。
ここまで、あなたは一人で画面と向き合い、難解なエラーや複雑な設定画面と格闘しながら、インフラ構築という険しい道のりを進んできました。しかし、IT業界の進化のスピードは残酷です。今日学んだ最新技術が、明日には古い常識に変わってしまうことも珍しくありません。
この終わりのない知識のアップデートを、たった一人で乗り越え続けるのには限界があります。だからこそ、一流のエンジニアは「コミュニティ」という場を活用するのです。勉強会に参加し、同じ熱量を持つ仲間と繋がりましょう。他者の失敗談や最新の知見に触れることで、一人では何日も悩んだ壁を、たった5分の雑談で突破できることも多いのです。
—— 最大のインプットは「アウトプット」である
そして、本記事の最後に最も伝えたい最強のキャリア戦略。それが「アウトプット(発信)」です。
「自分はまだ初心者だから、発信するようなすごい技術はない」と謙遜する必要は一切ありません。昨日までVPCの概念すら知らなかったあなたが、今日エラーを解決できたその「泥臭い過程」こそが、明日同じエラーで絶望している見知らぬ誰かを救う最高の教科書になるのです。
—— 次なる「ITノート」の執筆者は、あなたです
学んだことを自分の言葉でブログに書き起こし、技術プラットフォームへ投稿する。あるいは、さらに熱量を高めて「いつか本を出版する」くらいの覚悟で、自分の知識を体系的にまとめてみる。この「人に教える(発信する)」というプロセスを経た時、あやふやだった知識は初めて強固な「血肉」へと変わります。
アウトプットを続けるエンジニアの元には、自然と優秀な仲間が集まり、やがて魅力的なビジネスのオファーが舞い込むようになります。知識を自分の頭の中だけに独占するのではなく、世界へ解放すること。それが、あなたの市場価値を複利で爆発的に高める唯一にして最強のループなのです。
これにてAWSにおけるインフラ構築の旅は完結です。しかし、エンジニアとしてのあなたの物語はここからが本番。さあ、今度はあなたが、誰かのために新しいノートを開く番です。画面の向こう側で、あなたの発信を待っています。
本記事はこれにて完結となります。最後までお付き合いいただき、本当にありがとうございました。
免責事項
本ブログ(以下「当サイト」といいます)に掲載されている情報の利用にあたっては、以下の免責事項を必ずお読みください。当サイトのコンテンツを利用された場合、以下の内容を承諾いただいたものとみなします。
1. 情報の正確性・完全性について
当サイトに掲載されているAWS(Amazon Web Services)に関する情報や技術解説は、執筆時点における個人の経験および調査に基づき、細心の注意を払って作成しております。しかしながら、クラウドサービスの仕様変更やアップデートは非常に速く、掲載から時間が経過した情報については、その正確性、完全性、最新性を保証するものではありません。
2. 自己責任の原則
当サイトで紹介している構築手順、設計思想、コードサンプル等の利用によって生じた、いかなるトラブル、損失、損害(直接的・間接的を問わず、システムの停止、データの消失、セキュリティ事故、金銭的損失等を含みます)についても、当サイトおよび運営者は一切の責任を負いかねます。すべての操作および設定は、利用者自身の判断と責任において行ってください。
3. コストおよび課金について
当サイトではAWSのコスト管理(AWS Budgets、Cost Explorer等)について解説しておりますが、実際の請求額は利用状況によって変動します。設定の誤りや消し忘れ、第三者による不正利用等によって予期せぬ高額な課金が発生した場合でも、当サイトは一切の責任を負いません。AWSアカウントの課金状況については、利用者自身で定期的に確認・管理してください。
4. 責任共有モデルの遵守
AWSには「責任共有モデル」が存在します。当サイトが提供する情報はインフラ設計の補助を目的としたものであり、OSのセキュリティパッチ適用、データのバックアップ、IAMによる適切な権限管理など、利用者の責任範囲に属するセキュリティ対策を免除するものではありません。
5. 外部サイトおよびリンクについて
当サイトからリンクやバナーなどによって他のサイトに移動された場合、移動先サイトで提供される情報、サービス等について一切の責任を負いません。
6. 著作権について
当サイトに掲載されている文章、画像、構成などの著作権は運営者に帰属します。私的利用の範囲を超えて、無断で転載、複製、放送、公衆送信、翻訳、販売、貸与等を行うことを禁じます。
