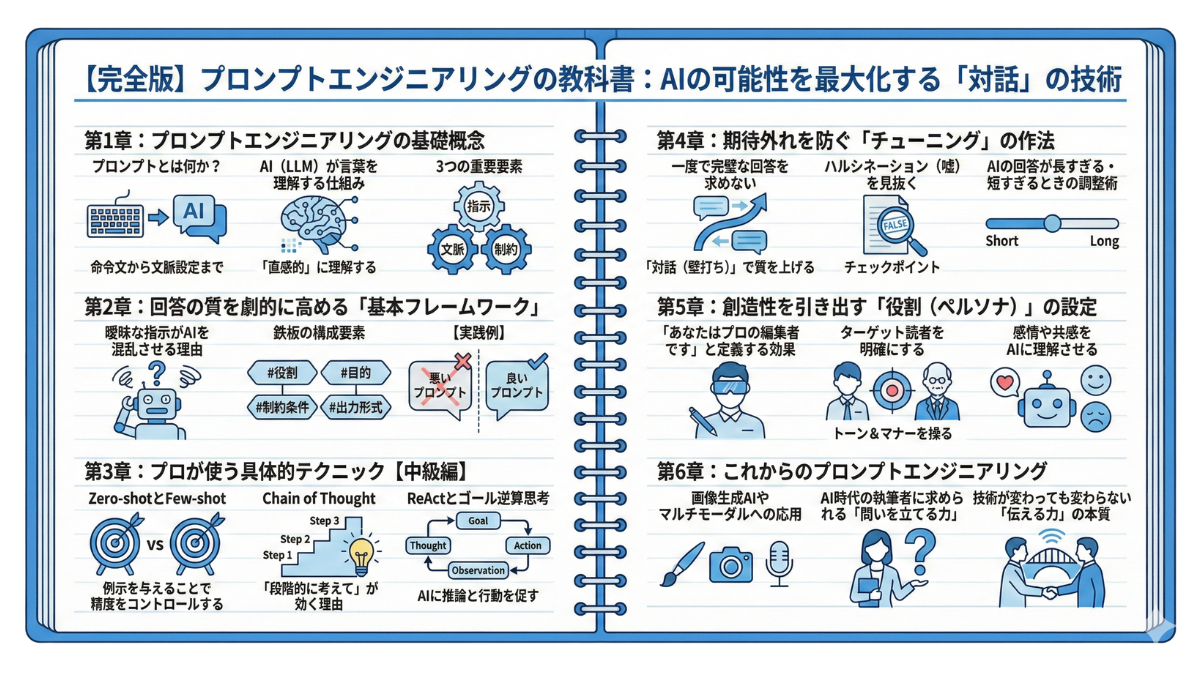
【完全版】プロンプトエンジニアリングの教科書:AIの可能性を最大化する「対話」の技術
IT-Notebooks.com
IT-Notebooks.com
どんなに流暢な言葉を紡ぐAIも、あなたの会社の「就業規則」や「極秘の契約書」のことは何一つ知らない。
業務効率化の切り札として生成AIを導入したものの、「もっともらしい顔をして、平然とウソをつく」「結局、人間が裏付け(ファクトチェック)をする手間のほうがかかっている」と頭を抱えてはいないでしょうか。AIは確かに膨大な知識を持っていますが、それが常に「あなたの目の前にあるビジネスの正解」とは限りません。自社のルールや独自のノウハウ、あるいは最新の専門データを与えられない限り、AIは悪気なく“知ったかぶり(ハルシネーション)”をしてしまうのです。
この「AIの限界」に直面した私たちが、次に手にするべき強力な武器。それが、生成AIの弱点を根本から克服する技術「RAG(検索拡張生成:Retrieval-Augmented Generation)」です。
RAGとは、記憶喪失の優秀なアシスタントに「外部の正確なカンニングペーパー」を渡し、確実な根拠に基づいた回答を出させる画期的な仕組みです。現在、世界のトップ企業がこぞってこの技術に熱狂し、自社のデータベースとAIを連携させる構築を急いでいます。
本記事では、AIの回答精度に限界を感じているビジネスパーソンから、自社システムへの本格的な実装を検討しているITエンジニアまでを対象に、RAGの全体像を徹底解説します。
難解な専門用語の羅列は避け、直感的な図解とビジネスの具体例を交えながら、「RAGが頭の中で何をしているのか」という基本構造から、「クラウドインフラを活用した実装の裏側」までを網羅しました。
AIの「もっともらしいウソ」に振り回されるのは、もう終わりにしましょう。AIと「自社の知識」を掛け合わせて、ビジネスにおける“最強の右腕”を創り出す。そのための第一歩を、ここから始めます。
「あ、それマニュアルの24ページに書いてあるよ。」
もしも、あなたの隣にいる生成AIが、社内の全ドキュメントを完璧に把握し、そう即答してくれたら――。あなたの業務は、どれほど劇的に効率化するでしょうか?
ChatGPTが登場した時、私たちは誰もが、SF映画のような未来が到来したと興奮しました。しかし、いざ日々の業務で本格活用しようとした瞬間、冷や水を浴びせられたような、ある「壁」にぶつかったはずです。
「ChatGPTは確かに便利だ。でも、肝心な『自社の業務』には、怖くて任せられない」
あなたがそう感じる、本当の理由をご存知でしょうか?それは、AIが社内の独自ルールや最新のマニュアルを知らないため、もっともらしい「嘘(ハルシネーション)」をつくリスクが拭えないからです。世界中の知識を持っていても、あなたの会社の「昨日改定されたばかりの経費規定」は、彼らの知識の外にあるのです。
この「理想と現実のギャップ」を埋め、AIをただの『物知りな他人』から、自社専用の『最強のパートナー』へと進化させる技術。それが、今世界中の企業が熱狂している「RAG(検索拡張生成)」です。
本記事では、このRAGという画期的な仕組みを、まずは技術的な数式や難解な専門用語に頼りきることなく、直感的に理解できるよう解説します。そして「では、自社にどう実装するのか?」という、ITエンジニアも納得する技術の裏側までを網羅した「実用的な地図」をご用意しました。
ビジネスを前進させたい企画担当者から、実装の糸口を探すエンジニアまで。AIに自社の「知能」を授け、業務を次のステージへ引き上げるための確実な一歩を、ここから一緒に踏み出しましょう。

「完璧な回答だ」と胸をなでおろした数分後、そのデータが全くのデタラメだったと気づき、背筋が凍るような思いをしたことはないでしょうか。
AIは、決して私たちを騙そうとして悪意のある嘘をついているわけではありません。まるで息を吐くように自然に、そして自信満々に「存在しない事実」を創造してしまうのです。この現象こそが、生成AIをビジネスの最前線で活用しようとする際に誰もが直面し、そして最も頭を悩ませる最大の壁です。
「AIはあらゆる問いに正確に答えてくれる魔法の箱である」という幻想を抱いたままでは、本質的な解決には辿り着けません。なぜなら、彼らの頭脳は「事実を検索して答える」のではなく、「確率的に最も自然な言葉の続きを予測して紡ぐ」ように設計されているからです。この根本的なメカニズムの違いを理解しない限り、私たちは永遠にAIの「もっともらしいウソ」のファクトチェックに追われ、本来の目的であるはずの業務効率化からは遠ざかってしまいます。
本章では、RAGという強力な武器を手にする前の準備段階として、まずは「敵」であるAIの弱点そのものを解剖していきます。なぜ彼らは嘘をつくのか。そして、私たちが現場でどのような落とし穴にハマっているのか。その真実を、目を逸らさずに見ていきましょう。
本章では、以下の2つのテーマについて詳しく解説していきます。
 1-1. 「AIは万能」という誤解と、現場で起きている3つの悲劇
1-1. 「AIは万能」という誤解と、現場で起きている3つの悲劇
魔法のツールと信じてAIを導入した現場で多発する、「知ったかぶり」「情報が古い」「社外秘を知らない」という3つの致命的な悲劇。AIの限界を知らずに起きる大失敗の典型例と、そのメカニズムを紐解きます。
1-2. プロンプト(指示文)の工夫だけでは、限界が来る理由
「指示の出し方が悪いから嘘をつくのだ」と、プロンプトの調整に何時間も費やしていませんか?実は、いくら命令文を洗練させてもAIの構造上「絶対に越えられない壁」が存在する残酷な理由を解説します。
AIの弱点を正しく恐れることこそが、次章で解説する「RAG」の劇的な効果を理解する最大の鍵となります。本章を読み終える頃には、あなたがAIに抱えていたモヤモヤとした不信感が、論理的な納得へと変わるはずです。
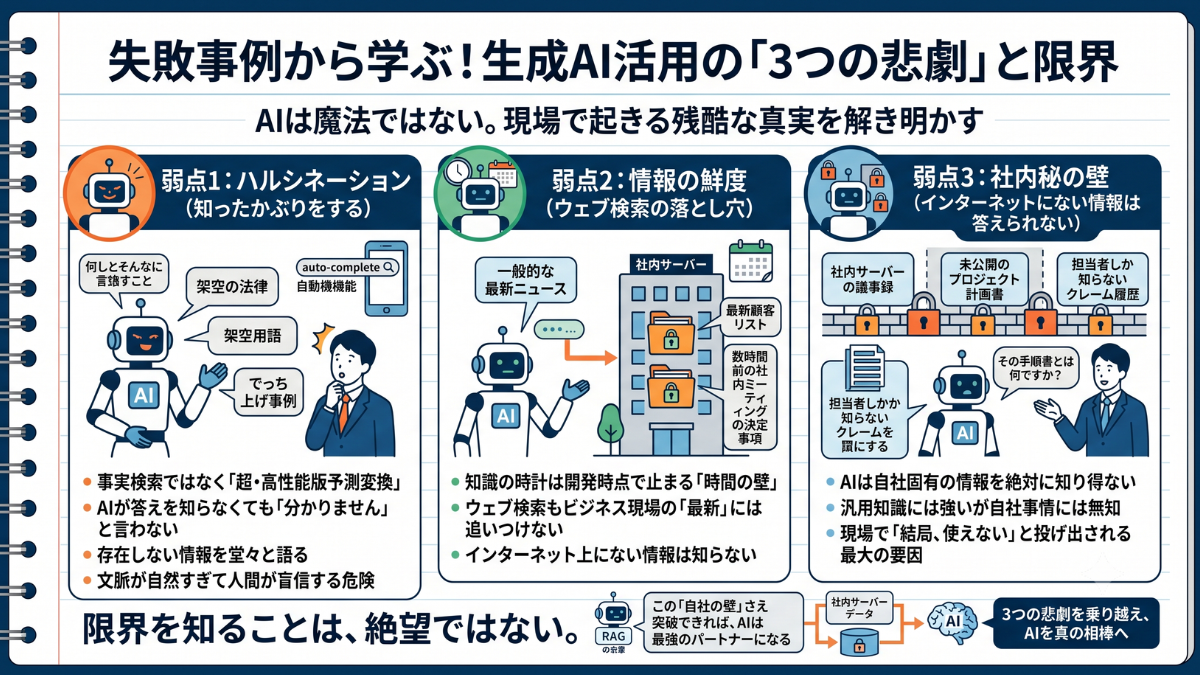
「AIに任せておけば、すべてが完璧に解決する」。その甘い期待は、実務に投入した初日に無残にも打ち砕かれます。
生成AIは魔法の杖ではありません。現場で多発する「もっともらしいウソ」「情報の鮮度」「社外秘への無知」という3つの悲劇。AIの限界から目を背けず、なぜ失敗が起きるのか、その残酷な真実を解き明かします。
メディアで連日報じられる華々しいAIの成功事例を目にしていると、私たちはつい「生成AIは全知全能のスーパーコンピューターである」と錯覚してしまいます。
膨大なデータを学習し、人間よりも遥かに早く、流暢な言葉で回答を導き出すその姿は、まるで魔法のようです。
しかし、いざ自社の業務に組み込もうとした途端、多くの企業が「こんなはずじゃなかった」と頭を抱えることになります。AIは万能神ではなく、極めて人間臭い「弱点」を抱えたシステムに過ぎません。
その本質を理解せずに現場へ投入した結果、今、あらゆる企業で以下の「3つの悲劇」が多発しています。
これが現場を最も混乱させる最大の悲劇です。生成AIは「事実をデータベースから検索して答えている」わけではありません。
仕組みとしては、「スマホの予測変換」の超・高性能版をイメージしてください。「この単語の次には、この単語が来る確率が高い」という計算を高速で繰り返し、もっともらしい文章を紡いでいるだけなのです。
そのため、AIが答えを知らない質問を投げかけられた時、「分かりません」とは言いません。存在しない法律、架空の専門用語、でっち上げられた事例を、さも真実であるかのように堂々と語り出します。文脈があまりにも自然で美しいがゆえに、人間側が盲信してしまい、重大なミスに繋がってしまうのです。
2つ目の悲劇は「時間の壁」です。生成AIのベースとなる頭脳は、開発された時点(学習データが収集された時点)で知識の時計が止まっています。
最近ではAI自体がウェブ検索を行う機能も一般的になりましたが、それでも万全ではありません。なぜなら、ビジネスの現場で今まさに更新された「最新の顧客リスト」や「数時間前の社内ミーティングの決定事項」は、インターネット上には転がっていないからです。「一般的な最新ニュース」には答えられても、「自社の最新の状況」には決して追いつけない。これが実務における致命的な足手まといになります。
そして3つ目が、私たちが最も直面する「自社の壁」です。
AIがどれほど賢くても、あなたの会社の「社内サーバーにある議事録」や「未公開のプロジェクト計画書」「担当者しか知らないクレーム履歴」は、絶対に知り得ません。
「いつもの手順書に沿って、この見積もりを作って」と指示しても、AIは「その手順書とは何ですか?」と立ち止まってしまいます。汎用的な知識には異常なほど強い一方で、目の前のあなたの会社の事情には全くの無知である。これが、現場で「結局、使えない」とAIが投げ出されてしまう最大の要因です。
しかし、逆に言えば「この自社の壁さえ突破できれば、AIは最強のパートナーになる」ということでもあります。これこそが、のちに解説する本作の主役・RAGが解決する最大のミッションなのです。
AIの構造的な弱点を理解することは、決して絶望ではありません。限界を知るからこそ、それを補う技術の価値がはっきりと浮き彫りになります。この3つの悲劇を乗り越え、AIを真の相棒に変える準備をここから始めましょう。
次節『1-2. プロンプト(指示文)の工夫だけでは、限界が来る理由』では、この弱点を『プロンプト(指示文)の工夫』だけで乗り切ろうとすると訪れる限界について解説します。
【生成AI導入の残酷な現実】
生成AIは魔法の杖ではありません。構造的な限界を知らずに実務に投入すると、大きな失敗を招きます。
【現場で多発する「3つの弱点」】
① ハルシネーション(知ったかぶり)
事実を検索しているのではなく「確率で言葉を紡いでいる」だけ。そのため、知らないことも自信満々にウソをつき、重大なミスを誘発します。
② 情報の鮮度(時間の壁)
AIの知識は過去で止まっています。ウェブ検索を使っても、今まさに更新された「自社のリアルタイムな最新情報」には追いつけません。
③ 社内秘の壁(自社の壁)
ネット上にない社内議事録やマニュアルを知らないため、あなたの会社特有の業務指示には応えられません。
【解決策:最強の相棒に変える「RAG」】
これらの限界を知ることが、AI活用の第一歩です。最大の課題である「自社の壁」を突破し、自社専用の優秀なパートナーへと進化させる画期的な技術。それこそが「RAG」なのです。
『完璧な魔法の呪文』を探し求める果てしない旅は、もう今日で終わりにしませんか?
生成AIの出力を良くしようと、プロンプトのテクニックを磨くことは重要です。しかし、どれだけ指示文を極めても、決して超えられない「壁」が存在します。本記事では、プロンプトの工夫がいずれ必ず限界を迎える、その構造的な理由を解き明かします。
「AIには役割を与えましょう」「ステップ・バイ・ステップで考えさせて」「出力形式を細かく指定する」
生成AIを使いこなそうと、こうしたプロンプト(指示文)のテクニックを熱心に学んでいる方は多いはずです。確かに、指示を工夫すればAIの回答精度は劇的に上がります。
しかし、実務で毎日使い込んでいくと、ある日ふと気づく瞬間がありませんか?
「何度もプロンプトの言葉尻を書き直しているうちに、自分で作業した方が早かったと後悔する」 「AIを効率化のツールとして導入したはずなのに、いつの間にか『物分かりの悪い部下に、ひたすら細かく指示出しをする世話焼き係』になっている」
期待する答えが出ず、AIのご機嫌取りをして疲弊してしまう。安心してください。それはあなたのプロンプト作成スキルが低いからではありません。
生成AIというシステム自体が抱える、「構造的な限界」に突き当たっているだけなのです。
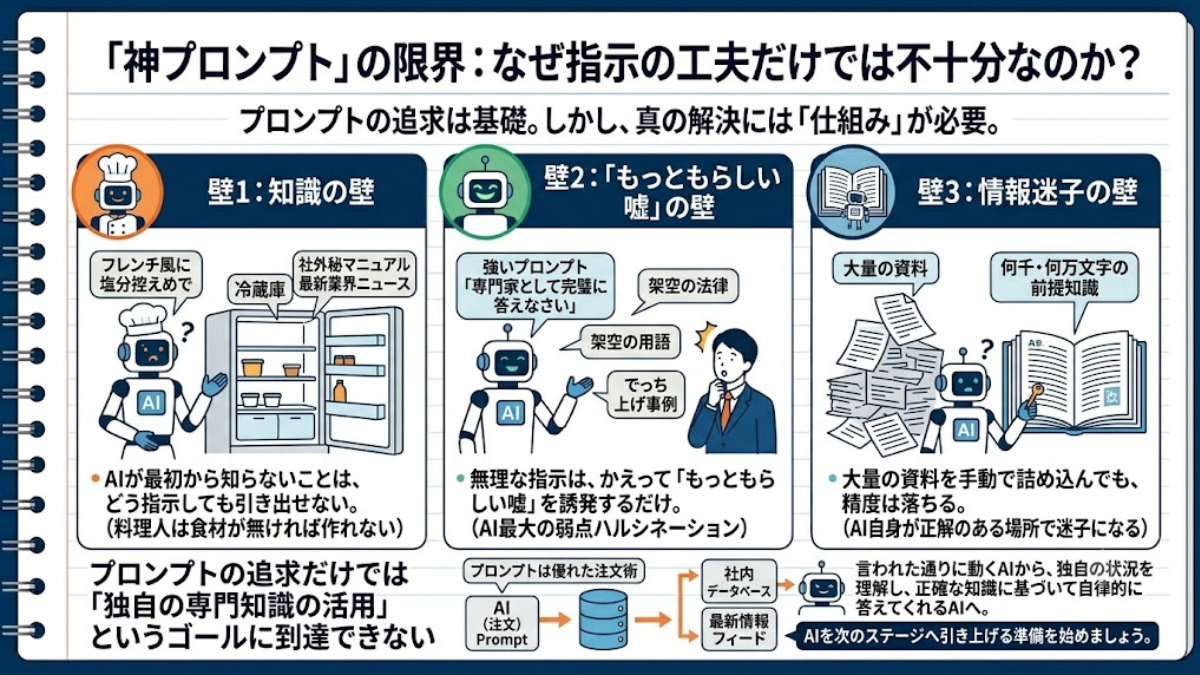
どれだけ指示の工夫を凝らしても限界が来る理由。それは、明確な「3つの壁」が存在するからです。
1. 「知識の壁」:無い食材で料理は作れない
生成AIとプロンプトの関係は、「料理人」と「注文」に似ています。
プロンプトの工夫とは、「フレンチ風に」「塩分控えめで」と、料理人(AI)に上手な注文を出すテクニックです。しかし、いくら注文の出し方が完璧でも、「冷蔵庫の中にその食材」が無ければ、料理は絶対に作れません。
AIの知識は、過去に学習したデータで止まっています。ネットに公開されていない「社外秘のマニュアル」や「最新の業界ニュース」という食材を持っていないAIに、プロンプトだけで「それを使った料理を出せ」と迫るのは物理的に不可能です。
【結論】AIが最初から知らないことは、どう指示しても引き出せない。
2. 「もっともらしい嘘(ハルシネーション)」の壁
知識がないAIに対し、強いプロンプトで「専門家として完璧に答えなさい」と強制すると何が起きるでしょうか。
ここで発生するのが、AI最大の弱点であるハルシネーション(もっともらしい嘘)です。AIは「分かりません」と謝るより、知ったかぶりをして堂々とそれっぽい嘘をつく厄介な癖があります。
「嘘をつかないで」とプロンプトで制御することは可能ですが、それでは単に「お答えできません」と機能停止するだけで、あなたの仕事は一歩も前に進みません。
【結論】無理な指示は、かえって「もっともらしい嘘」を誘発するだけ。
3. 「コピペの限界と、情報迷子の壁」
「AIが知らないなら、プロンプトに毎回資料をコピペして読み込ませればいい」
そう考える方もいるでしょう。確かにAIの性能は上がり、今では分厚いマニュアルを丸ごと読み込めるようになりました。しかし、ここに最大の落とし穴があります。
まず、毎回何千・何万文字もの前提知識を手作業で貼り付けるのは、あまりにも非効率です。さらに、AIに一度に大量の情報を渡しすぎると、「情報が多すぎて、大事なポイントを見落とす(または忘れる)」という現象が起きます。広すぎる辞書を渡されると、AI自身がどこに正解があるのか迷子になってしまい、結局ポンコツな回答になるのです。
【結論】大量の資料を手動で詰め込んでも、手間がかかる上に精度は落ちる。
誤解していただきたくないのは、「プロンプトの技術が不要になる」という意味ではありません。AIを思い通りに動かすための基礎スキルとして、今後も間違いなく必須です。
しかし、どれほど注文術(プロンプト)を極めても、肝心の知識(データ)を正しく・自動的にAIに渡す仕組みが無ければ、真に役立つビジネスパートナーにはなり得ません。
私たちが本当に求めているのは、「言われた通りに動くAI」から、「私たちの独自の状況を理解し、正確な知識に基づいて自律的に答えてくれるAI」への進化なのです。
プロンプトの追求は決して無駄ではありません。しかし、それ単体では「独自の専門知識の活用」や「絶対に嘘をつかない回答」というゴールには到達できません。AIを次のステージへ引き上げる準備を始めましょう。
プロンプトの限界という「壁」の正体が見えたところで、次なる疑問が浮かぶはずです。「では、AIに私たちの独自の知識を、手作業のコピペなしで正確に教え込むにはどうすればいいのか?」と。
次章の『第2章:【解決策】生成AIの弱点を克服する救世主「RAG」とは?』では、この限界を鮮やかに突破し、AIに「あなた専用の知識」を正確に語らせる最強の仕組みについて解説します。
プロンプト工夫の限界と「3つの壁」
プロンプトだけでは限界がある。
指示の工夫だけでは、AIの「構造的な限界」は決して超えられません。
「AIの世話焼き係」になっていませんか?
指示の微調整に時間を奪われ、かえって非効率に陥るケースが増えています。
立ちはだかる「3つの壁」
① 知識の壁
AIは未学習の情報(社外秘や最新ニュース等)を持っていないため、どう指示しても出力できません。
② 嘘の誘発
知識がないAIに無理に回答させようとすると、ハルシネーション(もっともらしい嘘)を引き起こします。
③ 手作業の限界と情報迷子
不足資料を毎回コピペするのは非効率。さらに情報量が多すぎると、AI自身が混乱して精度が落ちます。
解決策は「次の章」へ
プロンプト技術は基礎スキルとして必須ですが、それ単体では不十分です。 AIに「独自の知識」を自動的かつ正確に渡す仕組みへの移行が求められています。
前章で突きつけられた「AIは自社の事情を何も知らない」という残酷な現実。しかし、絶望するのはここで終わりです。
現在の生成AIは、例えるなら「難関の司法試験をトップ合格するほどの並外れた頭脳を持ちながら、あなたの会社の『就業規則』だけを読んでいないエリート法律家」のようなものです。基礎能力は桁外れですが、そのままでは現場の実務を任せることはできません。
このエリートを自社専用の即戦力に育て上げるため、これまでは「自社の分厚いマニュアルを、一からすべて暗記させ直す(再学習)」という、途方もない時間とコストがかかる茨の道しかありませんでした。 しかし今、その常識は完全に覆りました。
「無理にすべてを暗記させるのではなく、必要な時に、必要な資料だけをその場でカンニングさせればいいのではないか?」。このコロンブスの卵のような逆転の発想から生まれ、現在世界中のビジネス現場を席巻している画期的なアーキテクチャ。それこそが、生成AIの弱点を根本から克服する救世主「RAG(検索拡張生成:Retrieval-Augmented Generation)」です。
本章では、AIの歴史を変えたと言っても過言ではないこのRAGの正体を、専門用語を一切使わずに解き明かします。AIの限界に悩まされていた私たちの目の前に広がる、全く新しい世界地図を一緒に広げてみましょう。
本章では、以下の4つのテーマについて詳しく解説していきます。
2-1. RAG(検索拡張生成)を「優秀だが記憶喪失の助手」で例えてみる
RAGの仕組みを、直感的に理解できるよう解説します。「頭は劇的に良いけれど、自社の記憶がない助手」に、どうやって完璧な仕事をさせるのか?日常的な例えで、RAGの全体像がスッと腑に落ちます。
2-2. 「カンニングペーパー(外部知識)」を渡せば、AIは劇的に賢くなる
AIにすべてを暗記させる必要はありません。ユーザーからの質問に合わせて、社内のPDFやデータベースから「答えの載ったカンニングペーパー」を瞬時に探し出し、AIに渡して読ませる画期的なプロセスを解剖します。
2-3. RAGとファインチューニング(再学習)はどう違う?(コストと手間の圧倒的な差)
「AIに自社データを学習させよう」と考えた人が必ず陥る罠、ファインチューニングとの決定的な違いを解説。膨大なコストと数ヶ月の開発期間をすっ飛ばす、RAGの圧倒的なコストパフォーマンスに迫ります。
2-4. 世界のトップ企業がこぞってRAGを採用する決定的な理由
なぜ今、名だたる大企業がRAGの構築に巨額の投資をしているのか?「情報の権限管理」や「回答の根拠(出典)の明示」など、ビジネスの最前線で求められるシビアな要求をRAGがいかにクリアするのかを明かします。
本章を読み終える頃には、RAGが決して一部の天才エンジニアだけのものではなく、あなたのビジネスを劇的に変える「現実的で最も強力な手段」であることが確信できるはずです。さあ、AIの真の覚醒を始めましょう。
莫大なコストをかけて、世界中のあらゆる知識を持つ「超絶エリート助手」を雇ったとしましょう。しかし彼には、致命的な欠陥がありました。
RAGという難解な最新技術を、非エンジニアでも一瞬で腑に落ちる「記憶喪失の天才助手」という比喩で解き明かします。なぜ自社の業務でAIが使えないのか、その根本原因と解決の糸口を直感的に掴みましょう。
生成AIの弱点を克服する救世主「RAG(検索拡張生成)」。この技術をIT用語のまま理解しようとすると、すぐに挫折してしまいます。そこで、RAGの仕組みを「新しくあなたの部署に配属された、ひとりのアシスタント」に例えてみましょう。
彼(生成AI)の基礎能力は、控えめに言ってバケモノ級です。過去の膨大な判例から複雑な民法・商法の解釈までを完璧に暗記し、50カ国語を流暢に操り、誰もが唸るような美しいビジネス文書を1秒で書き上げます。
しかし、彼には「極度の記憶喪失」という致命的な欠陥がありました。
彼の記憶は、大学を卒業した数年前の時点で完全にストップしています。そのため、あなたが「昨日、A社と結んだ契約書の要点をまとめておいて」と指示を出すと、彼はパニックに陥ります。
「A社って誰ですか?昨日の契約とは何ですか?」
ここで前章でお話しした「ハルシネーション(知ったかぶり)」が発動します。彼は自分の優秀さをアピールしようと、存在しない架空のA社との契約内容を、完璧なフォーマットで勝手にでっち上げてしまうのです。
さて、あなたはこのエリート助手をクビにしますか?それとも、自社の情報をすべて暗記させるために、再び大学へ通わせますか?(ちなみに、この再学習のプロセスをIT用語で「ファインチューニング」と呼び、莫大なコストと時間がかかります)。
ここで登場するのが、RAG(検索拡張生成)という極めて現実的でスマートな解決策です。
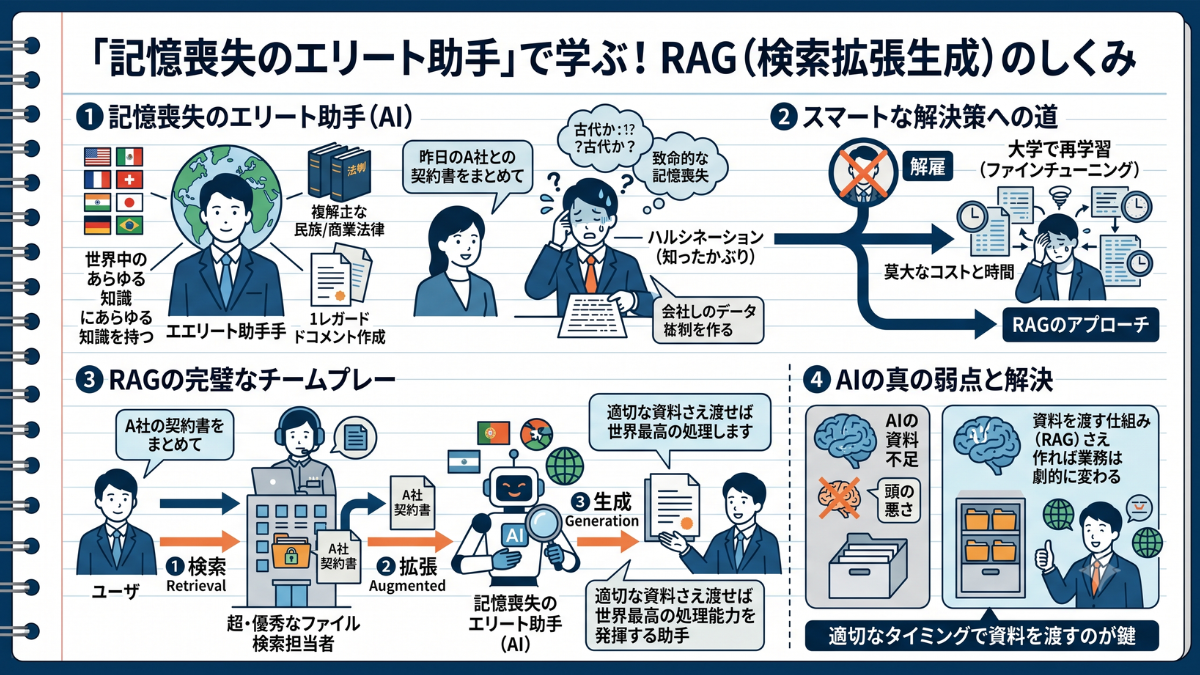
RAGのアプローチは、彼に何かを暗記させることではありません。彼の隣に、社内の全資料の保管場所を把握している「超・優秀なファイル検索担当者」を座らせるのです。
あなたが「A社の契約書をまとめて」と指示を出すと、裏側で完璧なチームプレーが発動します。
①検索担当者が、社内サーバーから瞬時にA社の契約書を探し出す(Retrieval:検索)
②そのファイルを、記憶喪失のエリート助手のデスクにポンと渡す(Augmented:拡張)
③エリート助手は渡されたファイル「だけ」を読み込み、完璧な日本語で要約文を作成する(Generation:生成)
ユーザーであるあなたは、自分でキャビネットを開ける必要すらありません。基礎能力が天才的な彼は、渡されたファイルを瞬時に読み解き、一切の嘘(ハルシネーション)を交えることなく、あなたに最高の回答を提出してくれます。
AIはすべてを知っている全知全能の神ではありません。しかし、「適切な資料さえ渡せば、世界最高の処理能力を発揮するアシスタント」であることは間違いないのです。
AIの真の弱点は「頭の悪さ」ではなく「手元に自社の資料がないこと」でした。この天才助手に適切なタイミングで資料を渡す仕組みさえ作れば、業務は劇的に変わります。では、その資料はどう渡すのでしょうか?
次の節は、『2-2. 「カンニングペーパー(外部知識)」を渡せば、AIは劇的に賢くなる』についてです。この記憶喪失の助手に、どうやって自社のマニュアルや過去の議事録という「カンニングペーパー」をシステムとして自動で渡し、最強の右腕へと変貌させるのか。その具体的なステップと驚くべき効果を解説します。順に読み進めて、RAGの真髄に触れてください。
【課題:記憶喪失のエリート助手】
・基礎能力は天才的だが、学習時以降の記憶がない。
・自社の最新情報や独自ルールを知らないため、もっともらしい嘘(ハルシネーション)をつく。
【従来の壁:再学習の限界】
自社データを一から覚え直させる(ファインチューニング)のは、莫大なコストと時間がかかり非現実的。
【解決策:RAG(検索拡張生成)の仕組み】
AIにすべてを暗記させるのではなく、質問に応じて「必要なカンニングペーパー」だけを渡すチームプレーです。
① 検索(Retrieval) システムが、社内サーバーから必要な資料を自動で探し出す。
② 拡張(Augmented) 探し出した資料を生成AIに渡す。
③ 生成(Generation) 生成AIは渡された資料「だけ」を基に、嘘のない正確な回答を作る。
【結論】 AIの真の弱点は「手元に自社の資料がないこと」。システムが自動で資料を渡す仕組み(RAG)さえ構築すれば、AIは自社専用の「最強の右腕」に進化する。
昨日まで「そんな会社のルールは知りません」とポンコツぶりを晒していたAIが、たった一つのPDFを渡した瞬間、社内で最も頼れるベテラン社員へと変貌を遂げます。
AIを賢くするために、膨大なデータを「暗記」させる必要はありません。必要なのは、適切なタイミングで「カンニングペーパー」を渡す仕組みです。魔法のような激変を生む、そのカラクリを解き明かします。
前節で、RAGの仕組みを「検索担当者が、記憶喪失のエリート助手に資料を渡すチームプレー」と例えました。
では、この「資料を渡す」という行為は、実際のシステム上ではどのように行われているのでしょうか?裏側で起きていることは驚くほどシンプルで、かつ合理的です。
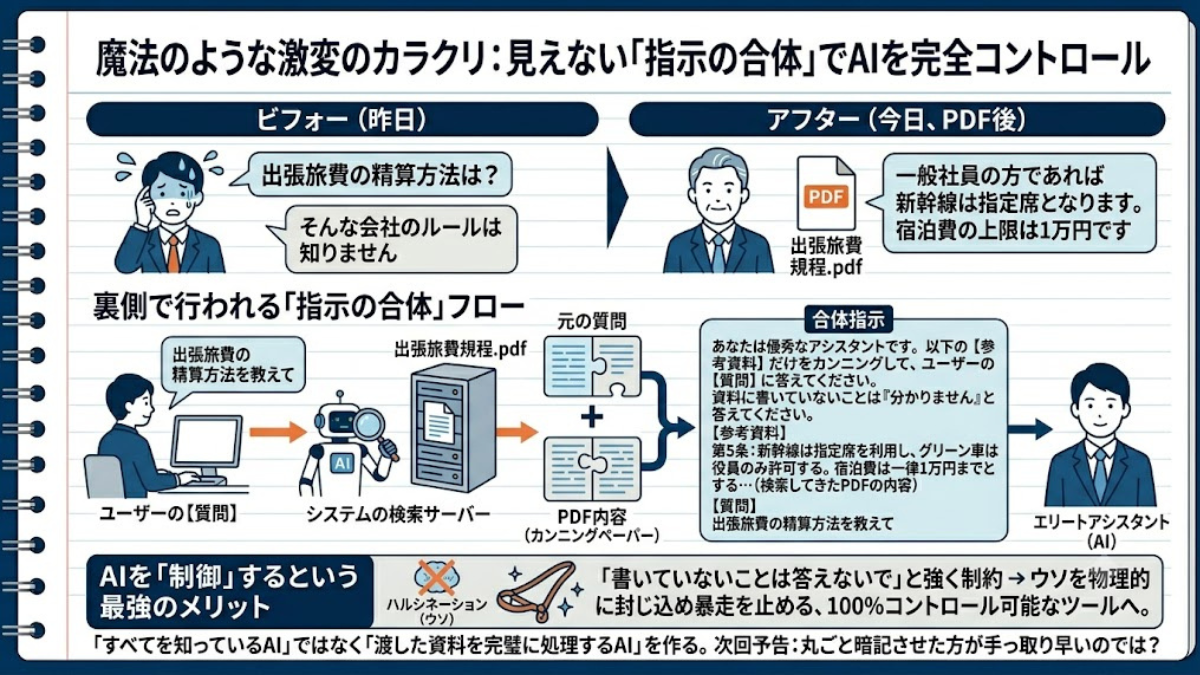
私たちが普段ChatGPTなどの生成AIを使うとき、入力画面に「出張旅費の精算方法を教えて」と短い質問を打ち込みますよね。
RAGを導入したシステムでは、あなたがこの短い質問を送信したコンマ数秒の間に、裏側でシステム(検索担当者)が猛烈な勢いで動きます。社内のデータベースを駆け巡り、「出張旅費規程.pdf」というファイルを見つけ出すと、システムはあなたの短い質問文を勝手に書き換えて(拡張して)しまうのです。
実際にエリート助手(AI)に届けられる指示文は、裏側で以下のような巨大な文章に変換されています。
「あなたは優秀なアシスタントです。以下の【参考資料】だけをカンニングして、ユーザーの【質問】に答えてください。資料に書いていないことは『分かりません』と答えてください。
【参考資料】 第5条:新幹線は指定席を利用し、グリーン車は役員のみ許可する。宿泊費は一律1万円までとする…(検索してきたPDFの内容)
【質問】 出張旅費の精算方法を教えて」
この巨大なカンニングペーパーを渡されたAIは、その桁外れの読解力を発揮し、「一般社員の方であれば新幹線は指定席となります。宿泊費の上限は1万円です」と、あなたの会社のルールに則った完璧な回答を生成します。
ここで重要なのは、AIが「自分の頭の中にある不確かな記憶」を探ったのではなく、「今、目の前に差し出されたカンニングペーパーの範囲内だけで仕事をした」という点です。
これにより、ビジネスにおいて最も恐ろしいハルシネーション(もっともらしいウソ)を物理的に封じ込めることができます。「書いていないことは答えないで」と強く制約をかけることで、AIは暴走を止め、100%コントロール可能な安全なツールへと生まれ変わるのです。
カンニングペーパー(外部知識)を渡すというアプローチは、AIに知性を与えるだけでなく、私たちがAIに「手綱」をつけるための最強の手段でもあります。
「すべてを知っているAI」を作るのではなく、「渡した資料を完璧に処理するAI」を作る。この発想の転換こそが、実務でAIを使いこなすための最適解です。しかし、ここで一つの疑問が浮かびませんか?
「毎回システムにカンニングさせるくらいなら、いっそのこと、そのルールブックを丸ごとAIの脳に暗記(再学習)させてしまった方が手っ取り早いのでは?」
次の節は、『2-3. RAGとファインチューニング(再学習)はどう違う?(コストと手間の圧倒的な差)』についてです。AIに自社データを学ばせようとした際、多くの企業が最初に陥る「再学習の罠」。なぜわざわざカンニングペーパー方式(RAG)を選ぶべきなのか、その残酷なまでのコストと手間の違いを徹底比較します。
【RAGの裏側:見えない指示の合体】
① 自動検索
ユーザーが短い質問を入力すると、システムが裏側で瞬時に社内の関連資料を探し出す。
② 指示文の拡張(カンニングペーパー化)
探し出した資料と、「この資料にないことは答えない」という強いルールをユーザーの質問に合体させ、AIへ送る。
【最大のメリット:AIの完全制御】
・事実に基づく回答
AIは曖昧な記憶に頼らず、渡された資料(カンニングペーパー)の範囲内だけで完璧に回答する。
・ウソ(ハルシネーション)の防止
「資料にないことは答えない」というルールにより、AIの知ったかぶりや暴走を物理的に封じ込める。
・100%コントロール可能
ただ賢くなるだけでなく、人間がAIの「手綱」を握ることで、ビジネスで安心して使える安全なツールに進化する。
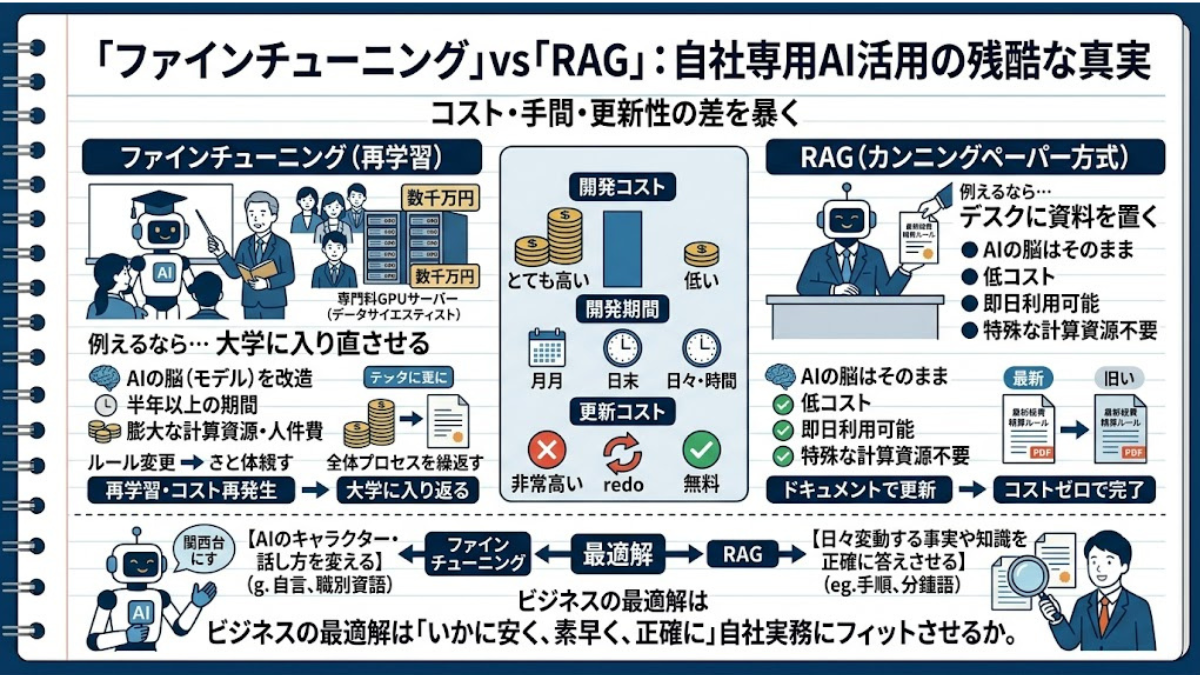
「よし、我が社専用のAIを開発するために、社内データをすべてAIに『再学習』させよう」。役員会議で飛び出したこの一言が、数千万円の予算と半年間のプロジェクトをドブに捨てる悲劇の始まりです。
自社専用AIを作る際、多くの企業が陥る「ファインチューニング(再学習)」の罠。AIの脳にすべてを暗記させる手法と、必要な時だけカンニングさせるRAG。ビジネスにおける両者の残酷なまでのコストと手間の差を暴きます。
AIを自社の業務に適合させようと考えたとき、真っ先に思い浮かぶのは「AIに自社のデータを直接読み込ませて、賢く鍛え直す」というアプローチでしょう。これをIT用語で「ファインチューニング(再学習)」と呼びます。
しかし、知識を「追加」する目的でファインチューニングを選ぶのは、実務において最悪の悪手となるケースがほとんどです。その理由は、両者の「コスト・手間・更新のしやすさ」の残酷なまでの差にあります。
前節のエリート助手の例えに戻りましょう。
自社の「新しい経費精算のルール」をエリート助手に覚えさせるために、ファインチューニングを行うとします。これは例えるなら、助手を一度休職させ、自社のルールだけを教え込むために数ヶ月間、専用の大学に通わせ直すようなものです。
AIの脳(モデルの重み)を直接書き換えるため、膨大な計算資源(超高額なGPUサーバー)と、データをAIが読み込める特殊な形式に整理するデータサイエンティストの途方もない人件費が必要になります。数千万円単位のコストと、半年以上の期間がかかることも珍しくありません。
一方、RAG(カンニングペーパー方式)はどうでしょうか。 こちらは、助手のデスクに「新しい経費精算ルールのPDF」をポンと置いてあげるだけです。AIの脳そのものを改造するわけではないため、特殊な計算資源も、数ヶ月の学習期間も不要です。今日からすぐに使い始めることができます。
さらに恐ろしいのは、ルールが変わった時です。
もし来月、経費精算のルールがまた変更されたらどうなるでしょうか?ファインチューニングの場合、AIの脳に古いルールが焼き付いてしまっているため、再び膨大なコストをかけて「記憶を上書きするための再学習」をやり直さなければなりません。
しかしRAGであれば、デスクに置くPDFを「最新版」に差し替えるだけ。たった数秒で、コストゼロで完了します。
誤解のないように補足すると、ファインチューニング自体が悪いわけではありません。「語尾を関西弁にする」「医療専門の特殊な言葉遣いをさせる」といった【AIのキャラクターや話し方】を変えるのには適しています。しかし、自社のマニュアルや過去の議事録といった【日々変動する事実や知識】を正確に答えさせるのであれば、圧倒的な低コストで即座に情報を書き換えられるRAGこそが、唯一無二の正解なのです。
ビジネスで求められるのは、数千万円かけてAIの脳をゼロから改造することではなく、今ある優秀な脳を「いかに安く、素早く、正確に」自社の実務にフィットさせるかです。RAGは、その最適解として君臨しています。
さて、「コストが安くて手間がかからない」というのは素晴らしいメリットですが、それだけの理由で世界中の名だたる大企業がこぞってRAGを選んでいるわけではありません。次の節は、『2-4. 世界のトップ企業がこぞってRAGを採用する決定的な理由』についてです。企業の命運を握る「機密情報のセキュリティ問題」や、ビジネスの決断において最も重要な「回答の根拠(出典)の明示」という、大企業がRAGを手放せなくなるさらにディープで決定的な理由を解き明かします。
【AIを賢くする2つの手法:決定的な違い】
❌ ファインチューニング(脳の改造)
手法: AIに自社データを一から丸暗記させる。
コストと手間: 莫大。数千万円の予算と半年以上の期間が必要(大学に入り直させるイメージ)。
情報の更新: 困難。ルールが変わるたびに高額な再学習が必要。
適した用途: 語尾や専門用語など「AIのキャラクターや話し方」を変える場合。
✅ RAG(カンニングペーパー方式)
手法: 質問に合わせて、必要な最新資料だけをAIに渡す。
コストと手間: 圧倒的低コスト。今日からすぐに使える(デスクにメモを置くイメージ)。
情報の更新: 一瞬。参照元のPDFを差し替えるだけで、コストゼロで最新情報に対応。
適した用途: マニュアルなど「日々変動する自社の事実・ルール」を正確に答えさせる場合。
【結論】 知識を追加するために何千万円もかけてAIの脳を改造するのは悪手。ビジネスの実務においては、安く・素早く・正確に情報を更新できるRAGが唯一無二の最適解です。

コストが安いから?手間がかからないから?──いいえ。名だたるグローバル企業がRAGを選ぶ本当の理由は、「企業の命運を握るトップシークレット」を絶対に守り抜くためです。
世界のトップ企業がRAGに巨額の投資をする決定的な理由は2つ。「情報のアクセス権限を完全にコントロールできること」と、「回答の根拠を100%提示できること」です。ビジネスの生命線を守る防壁の正体に迫ります。
前節までで、RAGがいかに低コストで、素早く自社の最新情報に対応できるかをお伝えしました。しかし、コンプライアンス(法令遵守)や情報統制に極めて厳しい世界のトップ企業たちがRAGをこぞって採用する「真の理由」は、実はもう一つの別の側面にあります。
それは、ビジネスの現場で絶対に妥協できない「セキュリティ(権限)」と「エビデンス(証拠)」の問題です。
実際の企業活動において、「社員全員が、社内のすべての資料を見られる」なんてことは絶対にあり得ません。新入社員が見るべきマニュアルもあれば、一部の経営幹部しか閲覧できない「取締役会議事録」や「未公開のM&A(企業買収)情報」「社員の給与データ」といった機密情報が存在します。
もし、これらすべてをファインチューニング(再学習)でAIの脳に叩き込んでしまったらどうなるでしょうか?新入社員が「次期社長は誰になりそう?」とAIに質問した瞬間、AIが極秘の役員会議の内容をペラペラと喋ってしまうという、背筋が凍るような情報漏洩が社内で起きてしまいます。AIの脳内で情報を「この人には見せる、この人には見せない」と切り分けることは、技術的に極めて困難なのです。
しかし、RAGならこの問題を完璧にクリアできます。RAGは「検索担当者」が資料を探してくるシステムだとお伝えしました。この検索システムを自社の権限設定と連携させれば、「新入社員が質問した時は、一般公開のフォルダからしかカンニングペーパーを探してこない」「役員が質問した時だけ、役員専用フォルダも探しに行く」というコントロールが簡単に実現できます。「見せてはいけない資料は、最初からAIに渡さない」。この強固なセキュリティラインを敷けることこそが、大企業がRAGを愛する最大の理由です。
もう一つの理由は、実務の「信頼性」に直結します。重大な商談や契約業務において、「なぜその結論になったのか?」と問われた際、「AIがそう言っていたからです」という言い訳は通用しません。
ファインチューニングされたAIは、なめらかな回答を出力しますが、「その情報源はどこか?」と聞かれても答えることができません。記憶がすべて混ざり合ってしまっているからです。
対してRAGは、「どのファイルの、どの部分をカンニングして答えたか」という情報源(出典ソースやリンク)を、回答とセットで提示することができます。「第3四半期の売上予測は〇〇億円です。(※根拠:社内資料『当期_第3四半期_財務予測.pdf』の4ページ目より)」
このように、ワンクリックで元の資料に飛んで人間自身の目で事実確認(ファクトチェック)ができる仕組み。この「圧倒的なトレーサビリティ(追跡可能性)」があるからこそ、企業は安心してAIに実務を任せることができるのです。
RAGは単なる「AIを賢くする便利ツール」ではありません。情報漏洩を防ぐ権限管理と、すべての回答に証拠を突きつける「最強のガバナンス(統治)装置」なのです。これで、なぜトップ企業がRAGを選ぶのか、すべての謎が解けました。
ここまでで、RAGの「なぜ必要なのか?」「どう優れているのか?」という疑問は完全に解消されたはずです。次の章は、『第3章:【仕組みの図解】RAGは頭の中で何をしているのか?(非エンジニア向け)』についてです。これまで概念でお伝えしてきたRAGの「検索と回答」の魔法のプロセスを、いよいよ具体的な図解イメージへと落とし込みます。あなたの頭の中で、AIのピースがカチッと組み合わさる瞬間を体験してください。準備はよろしいでしょうか?
【トップ企業がRAGを選ぶ2つの理由】
グローバル企業がRAGを選ぶ真の理由は、コスト削減ではありません。ビジネスで絶対に妥協できない「セキュリティ(権限)」と「エビデンス(証拠)」を完全に担保できるからです。
① アクセス権限のコントロール(情報統制)
従来のAI(再学習): 情報を切り分けられず、極秘の役員会議事録などが一般社員に漏洩するリスクがある。
RAGの強み: 質問者の権限に合わせて検索範囲(フォルダ)を制限できる。「見せてはいけない資料は最初からAIに渡さない」という強固なセキュリティラインを構築できる。
② 回答の根拠・出典の明示(ビジネス上の証拠)
従来のAI(再学習): 記憶が混ざり合っているため、情報源を提示できない。
RAGの強み: 「どのファイルのどの部分を参照したか」を回答とセットで提示する。人間がワンクリックで元資料を確認(ファクトチェック)できるため、圧倒的な信頼性を持つ。
【結論】 RAGは単にAIを賢くするツールではありません。情報漏洩を防ぎ、すべての回答に証拠を突きつける「最強のガバナンス(統治)装置」です。
魔法の裏側には、必ず美しく論理的な「タネ明かし」が存在します。ブラックボックスだったAIの頭の中を、今からあなた自身の目で直接覗き込んでみましょう。
前章までで、RAGがいかにビジネスの課題を解決し、最強のガバナンス装置として機能するのかをご理解いただけたはずです。しかし、非エンジニアの多くは「システムが自動で資料を検索して回答を作る」と聞いた瞬間、「なんだか難しそう」と思考を止めてしまいます。
ご安心ください。本章では、難解なプログラミング言語や、エンジニアしか使わないような専門用語は一切登場しません。
RAGという魔法の箱の中で、あなたの会社のデータとAIが一体どのようにバトンを繋いでいるのか。その華麗で無駄のない連携プレーを、非エンジニアでも一瞬で腑に落ちる「直感的な図解のイメージ」に落とし込んで解説します。
本章では、以下の2つのテーマについて詳しく解説していきます。
3-1. たった3つのステップで理解するRAGの思考回路
「検索(Retrieval)」「拡張(Augmented)」「生成(Generation)」。名前こそ難解ですが、やっていることは驚くほどシンプルです。AIの頭の中で起きている3つの思考プロセスを完全に解剖します。
3-2. 社内データベースとAIが裏側で連携する姿
あなたの会社のPDFや資料は、そのままではAIに読めません。バラバラのデータがどのように整理され、必要な瞬間にAIへとパスされるのか。システム裏側の「データの橋渡し」のカラクリを視覚化します。
この章を読み終える頃、あなたの頭の中にあった「よくわからないAI」というモヤモヤは完全に晴れるでしょう。仕組みが視覚的に腹に落ちた瞬間、AIは得体の知れない魔法から「使いこなせる確かな道具」へと変わります。
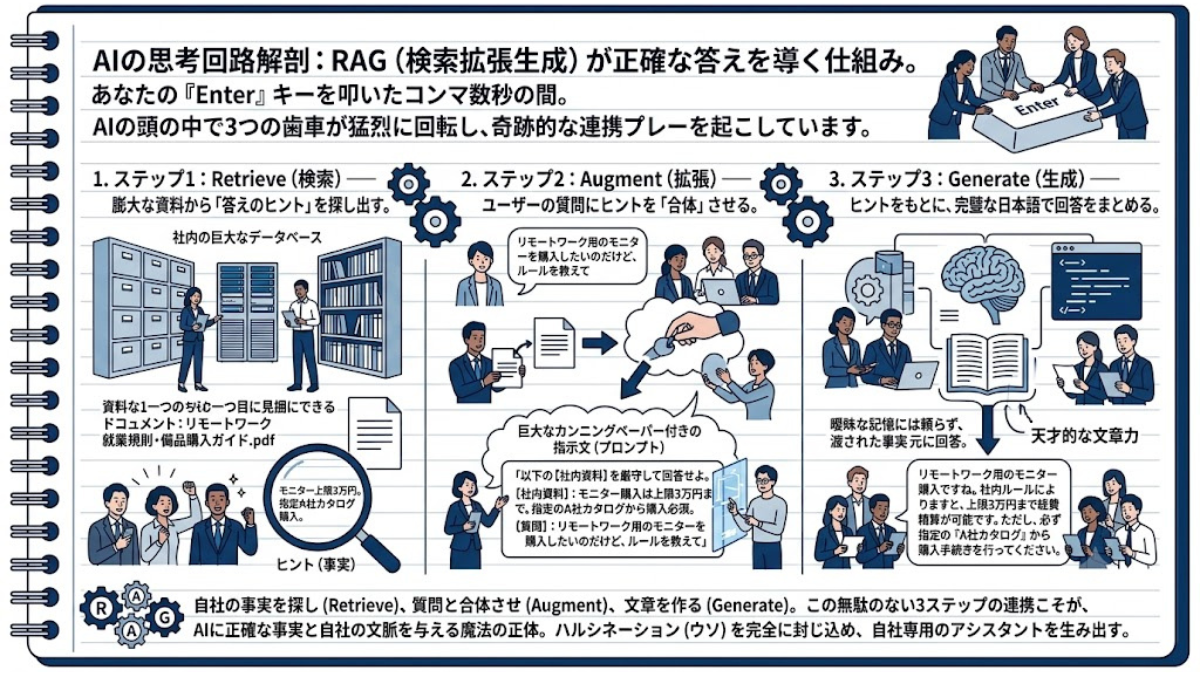
あなたがキーボードの「Enter」キーを叩いたコンマ数秒の間。AIの頭の中では、3つの歯車が猛烈なスピードで噛み合い、奇跡のような連携プレーを起こしています。
難解なRAGの仕組みも、分解すれば「検索(Retrieve)」「拡張(Augment)」「生成(Generate)」のたった3ステップ。AIがいかにしてウソをつかずに正確な答えを導き出すのか、その美しい思考回路を解剖します。
RAG(Retrieval-Augmented Generation)という言葉は、IT業界特有のいかにも難しそうな響きを持っています。しかし、その正体は英単語を3つ繋げただけのものであり、裏側で動いているステップも名前の通り「たったの3つ」しかありません。
ここでは、あなたが社内AIに向かって「リモートワーク用のモニターを購入したいのだけど、ルールを教えて」と質問したケースを例に、その3つの思考回路を順を追って見ていきましょう。
あなたが質問を送信した瞬間、最初に動き出すのはAI(脳)ではなく、「検索システム」です。システムは瞬時に社内の巨大なデータベースに潜り込み、数万件のファイルの中から「リモートワーク就業規則・備品購入ガイド.pdf」というドンピシャの資料を探し出してきます。その資料には、「モニターは上限3万円まで経費精算可能。ただし、指定のA社カタログから購入すること」という、社外の誰も知らない独自のルールが記載されています。これが回答の「ヒント(事実)」となります。
次に、システムは探し出してきたヒント(PDFの記述)と、あなたの最初の質問を「合体」させます。ここがRAGの最も賢いポイントです。単に「ルールを教えて」という元の質問を、裏側でこっそりと以下のような「巨大なカンニングペーパー付きの指示文(プロンプト)」へと拡張するのです。
「以下の【社内資料】を厳守して回答せよ。【社内資料】:モニター購入は上限3万円まで。指定のA社カタログから購入必須。【質問】:リモートワーク用のモニターを購入したいのだけど、ルールを教えて」
最後は、いよいよ天才的な文章力を持つ生成AIの出番です。ステップ2で拡張された「カンニングペーパー付きの指示文」を受け取ったAIは、自分の曖昧な記憶には一切頼らず、渡された事実【だけ】を元にして、流暢な日本語を紡ぎ出します。
「リモートワーク用のモニター購入ですね。社内ルールによりますと、上限3万円まで経費精算が可能です。ただし、必ず指定の『A社カタログ』から購入手続きを行ってください。」
いかがでしょうか。自社の事実を探し(Retrieve)、質問と合体させ(Augment)、文章を作る(Generate)。この見事な3区間のリレー競走こそが、AIのハルシネーション(ウソ)を完全に封じ込め、自社専用の完璧なアシスタントを生み出しているRAGの思考回路なのです。
検索し、合体させ、生成する。この無駄のない3つのステップ(R・A・G)こそが、AIに「正確な事実」と「自社の文脈」を与える魔法の正体です。しかし、ここで一つ、実務的な疑問が生まれるはずです。
「AIは、どうやって社内のPDFやWordの文章を瞬時に『検索』しているのだろうか?」次の節は、『3-2. 社内データベースとAIが裏側で連携する姿』についてです。この3ステップを成り立たせるためには、社内に眠るバラバラのデータを、AIが読める状態に整理しておかなければなりません。私たちが普段見ることのない「データの橋渡し(ベクトル化)」のカラクリを、分かりやすく紐解きます。
【RAGの思考回路:3つのステップ】
① Retrieve(検索):ヒントを探し出す
質問を受けると、まずは「検索システム」が社内データベースに潜り込み、関連する資料や事実を瞬時に発見する。
② Augment(拡張):質問とヒントを「合体」させる
探し出した資料を、質問の裏側で結合させる。「この資料の範囲内で回答せよ」という、強力な指示文(カンニングペーパー)へと自動的に書き換える。
③ Generate(生成):事実をもとに回答を作る
生成AIが、渡された資料(事実)のみを根拠にして、正確な回答をまとめる。自身の曖昧な記憶には頼らないため、ウソ(ハルシネーション)を完全に封じ込める。
【結論】 「探す(R)」「合体させる(A)」「作る(G)」。この無駄のない連携プレーにより、AIに正確な事実と自社の文脈を与えることができる。
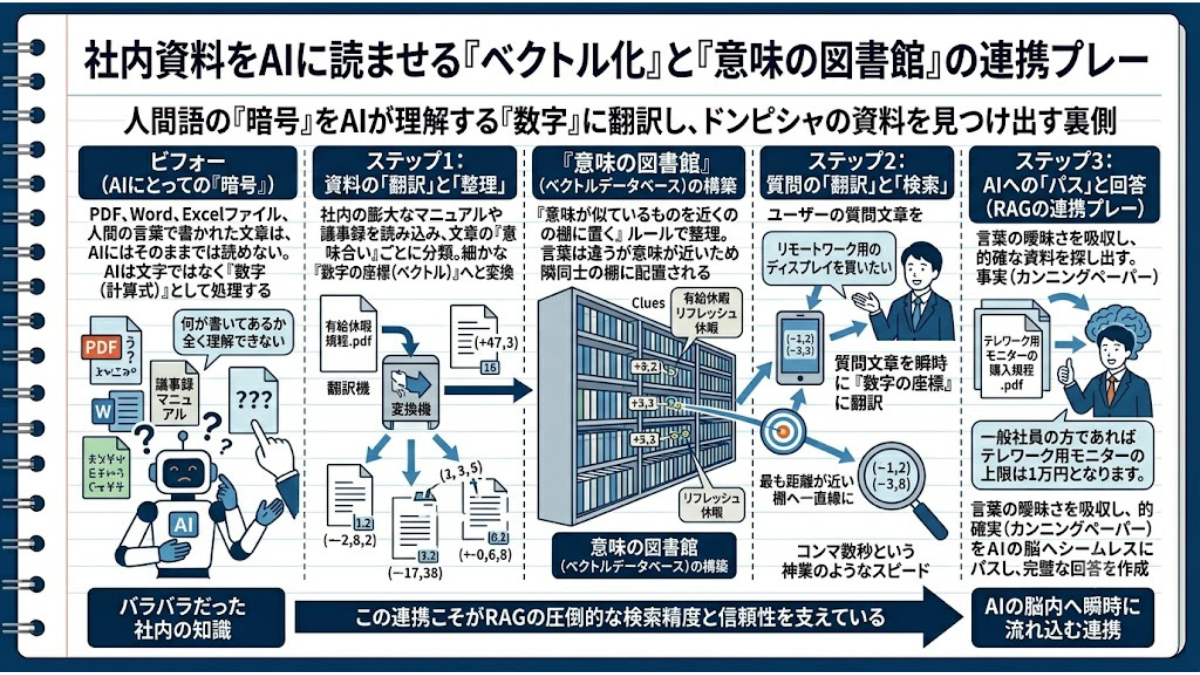
普段私たちが当たり前のように使っているPDFやWordの文章。実はそれ、そのままではAIにとって「何が書いてあるか全く理解できない暗号」だという衝撃の事実をご存知でしょうか。
人間の言葉で書かれた社内資料を、AIが瞬時に検索できるようにするための魔法の翻訳技術「ベクトル化」。バラバラのデータが整然と並べられ、AIへと受け渡される裏側の壮大な連携プレーを視覚的に解き明かします。
前節で、RAGの最初のステップは「検索システムが社内のデータベースからドンピシャの資料を探し出してくること(Retrieve)」だと解説しました。
しかし、ここに大きな壁が存在します。実は、私たちが普段業務で作っているPDF、Word、Excelといったファイルは、そのまま放り込んでもAIには読めません。AIは人間の言葉を「文字」としてではなく、「数字(計算式)」として処理する生き物だからです。
では、システムはどうやって自社の資料とAIを裏側で連携させているのでしょうか?その鍵を握るのが、「ベクトル化(意味の座標変換)」という鮮やかな翻訳プロセスです。
RAGを導入する際、システムはまず、社内にある膨大なマニュアルや過去の議事録をすべて読み込みます。そして、そこに書かれている文章を「意味合い(ニュアンス)」ごとに分類し、細かな「数字の座標(ベクトル)」へと変換していきます。
例えるなら、巨大な「意味の図書館」を作るようなものです。従来のキーワード検索(タイトルのあいうえお順で整理する図書館)とは異なり、この図書館は「意味が似ているものを近くの棚に置く」というルールで整理されます。例えば、「有給休暇」という資料と「リフレッシュ休暇」という資料は、言葉は全く違いますが「意味(座標)」が非常に近いため、隣同士の棚に配置されるのです。この魔法の図書館のことを、IT用語で「ベクトルデータベース」と呼びます。
準備が整った「意味の図書館」に、ユーザーから質問が投げ込まれます。「リモートワーク用のディスプレイを買いたい」
するとシステムは、この質問の文章も瞬時に「数字の座標」に翻訳します。そして、図書館の広大な空間の中から、その座標と「最も距離が近い棚」へ一直線に飛んでいくのです。結果として、書類に「ディスプレイ」という単語が一言も書かれていなくても、意味が近い「テレワーク用モニターの購入規程」という正解のPDFを、コンマ数秒という神業のようなスピードで見つけ出すことができます。
人間の言葉の曖昧さ(言葉の揺らぎ)を「意味の座標」に変換して吸収し、最も的確な資料を探し出す。そして、綺麗に整えられたその「事実(カンニングペーパー)」を、生成AIの脳内へシームレスに流し込む。
私たちがエンターキーを押した裏側では、「①資料の翻訳」→「②意味の図書館でのマッチング」→「③AIへのパス」という、息を呑むほど美しい連携プレーが展開されています。この強固なデータ連携の基盤があるからこそ、RAGはビジネスの現場で「絶対に使えるツール」として君臨しているのです。
バラバラだった社内の知識は「意味の座標」という新しい姿を与えられ、天才助手の脳内へ瞬時に流れ込みます。言葉の壁を越えてデータとAIが手を取り合うこの連携こそが、RAGの圧倒的な検索精度と信頼性を支えているのです。
仕組みの謎がすべて解けた今、いよいよ知識を「実践」へと移すフェーズに入ります。次の章は、『第4章:【ビジネス活用】RAGが変える「私たちの働き方」』についてです。この画期的なシステムを導入した企業で、実際にどのような「劇的な業務効率化」が起きているのか。営業、人事、カスタマーサポートなど、あなたの明日の働き方を根本から変える、具体的で生々しいユースケースに迫ります。
【RAGの裏側:データとAIの連携】
【前提の課題】
・PDFやWordなどの社内資料は「人間の言葉」。
・計算で処理を行うAIには、そのままでは理解できない。
【3つの連携ステップ】
① 資料の翻訳(ベクトル化)
・社内の全資料を読み込み、文章のニュアンスを「意味の数字(座標)」に変換。
・意味が似ているデータを近くに配置する「意味の図書館」を作る。
② 意味でのマッチング(検索)
・ユーザーの質問も瞬時に「数字の座標」に変換する。
・図書館の中から、最も座標が近い(意味が似ている)資料を探し出す。
・「ディスプレイ」と「モニター」のような言葉の違い(揺らぎ)も吸収できる。
③ AIへの完璧なパス
・見つけ出した的確な資料(事実)を綺麗に整え、生成AIへシームレスに受け渡す。
【結論】 単なるキーワード一致ではなく、「資料の翻訳」→「意味のマッチング」→「AIへのパス」というプロセスを踏むことで、圧倒的な検索精度と信頼性を発揮する。
「仕組みはわかった。でも結局、私の毎日の残業時間はどうやって減るの?」──その切実な問いに対する、最も鮮やかで具体的な答えがここにあります。
第3章までで、RAGの「頭の中の構造」を解剖してきました。しかし、どんなに美しいテクノロジーも、現場の汗と涙を拭えなければ意味がありません。本章ではいよいよ実験室を飛び出し、泥臭いビジネスの最前線へと向かいます。圧倒的な業務効率化を実現し、あなたの明日からの働き方を劇的に変える「RAGの実践ストーリー」の幕開けです。
本章では、以下の4つのテーマについて詳しく解説していきます。
4-1. ケース1:【社内ヘルプデスク】就業規則や経費精算の質問をAIが全自動回答
「パスワードを忘れました」「交通費の申請方法は?」。担当者の時間を奪う無限の「よくある質問」を、AIが社内規程を読み込んで24時間365日即答。人間はより高度な業務に集中できる環境を取り戻します。
4-2. ケース2:【営業支援】過去の提案書や議事録を瞬時に探し出す「最強の右腕」
「あの案件の過去資料、どこだっけ?」という不毛な捜索時間は今日で終わりです。数万件の提案書や議事録から、今必要な成功事例のハイライトだけを抽出して提案してくれる、最強の営業アシスタントが誕生します。
4-3. ケース3:【カスタマーサポート】顧客の過去の履歴を踏まえたパーソナライズ対応
マニュアル通りの冷たい返答ではなく、「前回は〇〇をご購入いただき…」と過去の履歴を自然に織り交ぜた神対応を実現。顧客データとAIが連携することで、人間以上に温かみのある顧客体験を提供する方法に迫ります。
4-4. 導入する際に気をつけたい「セキュリティ」と「著作権」の落とし穴
どんなに便利でも、ルールを破れば企業にとって致命傷になります。他社のデータ学習リスクや機密情報の取り扱いなど、実務でRAGを安全に運用するための「絶対外せない防衛線(ガードレール)」を徹底解説します。
理論は、実務に変わって初めて価値を持ちます。この章を読めば、「うちの部署ならこう使える!」という具体的なアイデアが次々と湧き上がるはずです。さあ、AIを最強の同僚として迎え入れる準備を始めましょう。
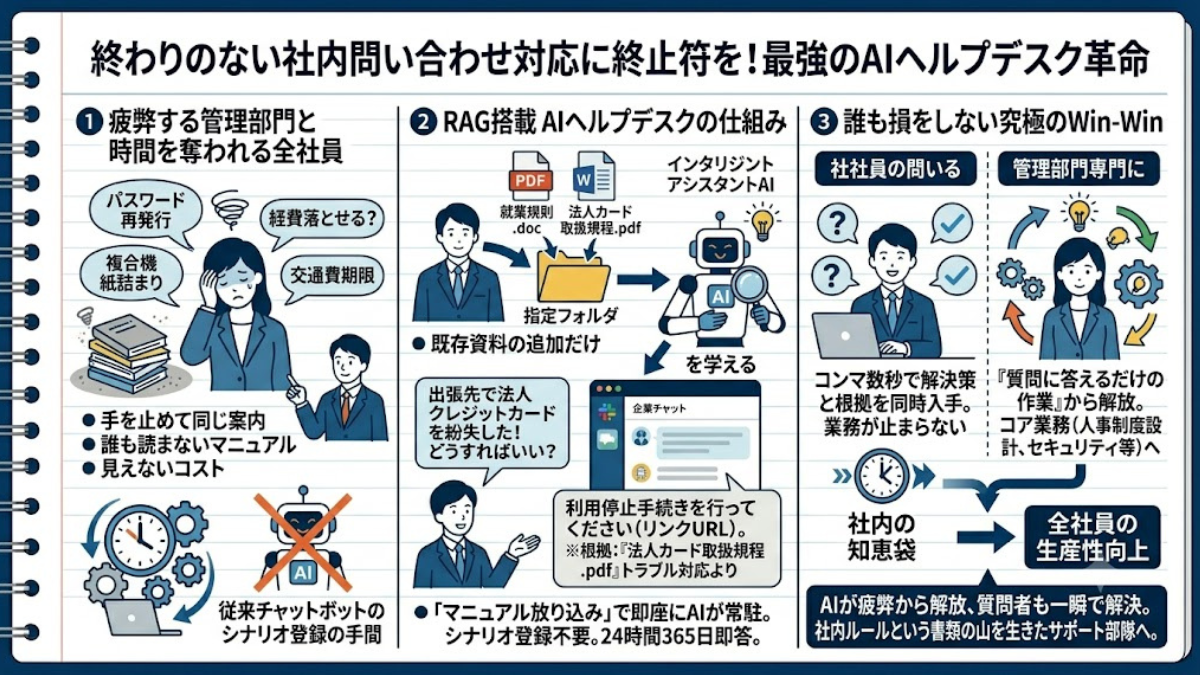
「パスワードの再発行はどうやるの?」「この経費は落とせる?」──総務や人事の担当者を毎日すり減らす、終わりのない「社内からの問い合わせ対応」という地獄。そのデスマーチに、今日、終止符を打ちます。
膨大な社内マニュアルを読み込んだRAGが、24時間365日、社員からの質問に即答する「最強のAIヘルプデスク」へと進化。担当者の時間を奪う無限のループを断ち切り、本来のコア業務を取り戻す革命の全貌に迫ります。
どの企業にも必ず存在する、しかし決して表舞台では評価されにくい隠れた重労働。それが、総務、人事、経理、そして情報システム部門などが日々追われている「社内からの問い合わせ対応(社内ヘルプデスク業務)」です。
「交通費の申請期限はいつまでですか?」「結婚したのですが、どんな手続きが必要ですか?」「複合機が紙詰まりを起こしました」
担当者はそのたびに作業の手を止め、「それはポータルサイトの〇〇フォルダにあるマニュアルの3ページ目に書いてありますよ」と、今日だけで3回目になる同じ案内を繰り返します。マニュアルを作っても誰も読んでくれない。この「質問する側もされる側も、少しずつ時間を奪われ続ける不毛なやり取り」は、日本中のオフィスで毎日発生している巨大な見えないコストです。
かつて、この問題を解決しようと「チャットボット」を導入した企業も多くありました。しかし、従来のチャットボットは「Aと聞かれたらBと答える」というシナリオ(ルール)を人間が一つ一つ手作業で登録しなければならず、結局メンテナンスの手間がかかりすぎて廃れてしまうケースがほとんどでした。
ここで、RAGの圧倒的な力が爆発します。
RAGを活用したAIヘルプデスクに、シナリオの登録は一切不要です。担当者がやるべきことは、「既存のPDFマニュアルや就業規則のWordファイルを、指定のフォルダにポンと放り込んでおくこと」だけ。たったこれだけで、社内チャット(SlackやTeamsなど)に常駐するAIが、完璧なコンシェルジュとして動き出します。
社員が「出張先で法人クレジットカードを紛失してしまった!どうすればいい?」とチャットに打ち込むと、AIは裏側で瞬時に危機管理マニュアルを検索(Retrieve)し、こう即答します。
「法人カードの紛失ですね。大変でしたね。まずは直ちに以下のリンクからカードの利用停止手続きを行ってください。(リンクURL)その後、経理部の〇〇さん宛に紛失届を提出する必要があります。(※根拠:『法人カード取扱規程.pdf』 第4条 トラブル対応より)」
質問した社員は、担当者の手が空くのを待つことなく、コンマ数秒で「正確な解決策」と「根拠となる資料」を同時に手に入れることができます。
誰も損をしない「究極のWin-Win」。AIが「一次受けの窓口」として機能することで、社員は知りたい情報へ即座にアクセスでき、業務が止まりません。そして何より、管理部門の担当者は「質問に答えるだけの作業」から解放され、より良い人事制度の設計や、強固なセキュリティ環境の構築といった「人間にしかできない本来のコア業務(クリエイティブな仕事)」に全力を注ぐことができるようになるのです。
AIが「社内の知恵袋」になることで、管理部門は疲弊から解放され、質問者も一瞬で悩みを解決できます。社内ルールという退屈な書類の山を、生きたサポート部隊に変える。これが全社員の生産性を押し上げる最初のRAG革命です。
「守り」のバックオフィス業務が効率化されたなら、次は「攻め」の最前線です。次の節は、『4-2. ケース2:【営業支援】過去の提案書や議事録を瞬時に探し出す「最強の右腕」』についてです。顧客の心を動かす提案書を、毎回ゼロから作る苦労はもう終わりです。社内に眠る過去の「勝ちパターン」を瞬時に引き出し、新入社員を一瞬でトップセールスマンと同じ情報武装レベルへと引き上げる、驚異の営業活用法をご紹介します。
【社内ヘルプデスク×RAGの劇的効果】
❌ 従来の課題(負のループ)
・総務・人事の疲弊: 終わりのない問い合わせ対応で、担当者の時間が奪われる
・旧チャットボットの限界: 手作業でのシナリオ登録が必要で、大半がメンテに挫折。
✅ RAGによる解決策(仕組み)
・シナリオ登録は一切不要。
・既存のマニュアル(PDFやWord)を専用フォルダに入れるだけ。
・社内チャットに「AIヘルプデスク」が常駐。
🚀 もたらされる変化(究極のWin-Win)
・質問する社員: AIが「解決策」と「根拠(出典)」を即答。待たされず業務が止まらない。
・管理部門: 無限の質問ループから解放され、「人間にしかできないコア業務」に集中できる。
【結論】 誰も読まないマニュアルの山を「24時間働くAIサポート部隊」に変え、全社員の生産性を飛躍的に高める。
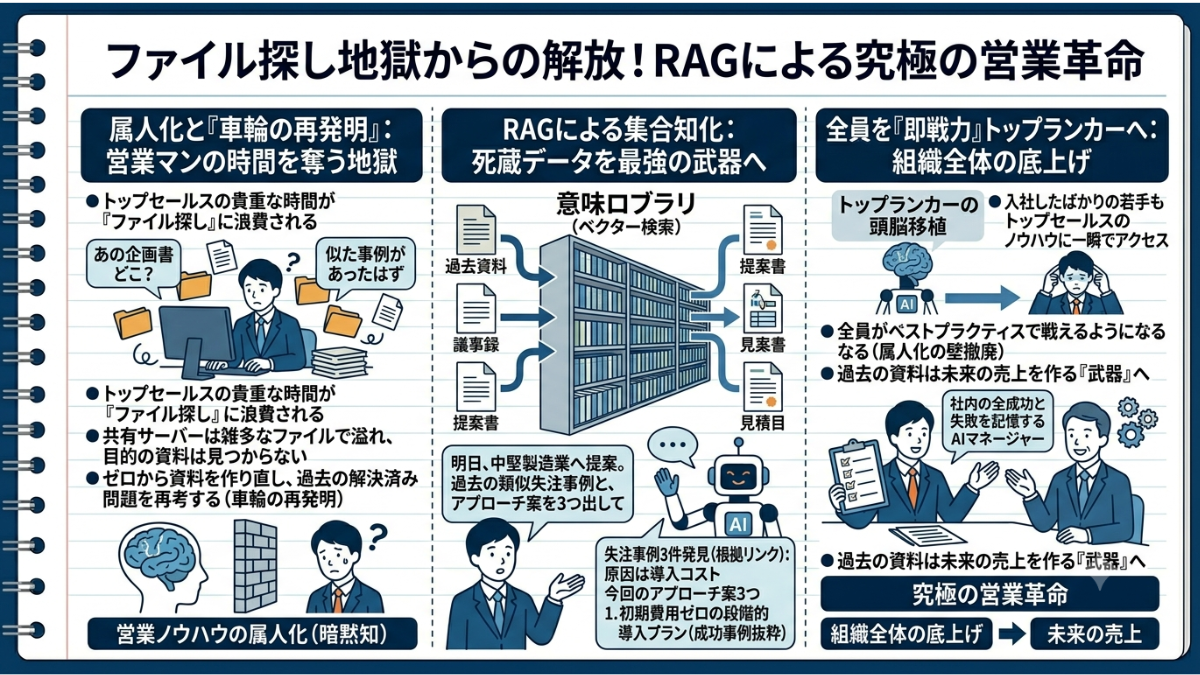
「あの時の提案書、どこに保存したっけ?」──トップセールスマンの貴重な時間を最も容赦なく奪っているのは、顧客との商談ではなく、社内の「ファイル探し」という名の不毛な宝探しゲームです。
属人化しがちな営業の「勝ちパターン」を、AIが全社規模で共有する時代が来ました。数万件の過去資料や議事録から、今すぐ使える最強の提案の切り口を数秒で引き出す、次世代の営業アシスタントの姿を描きます。
企業の売上を牽引する営業部門。しかし、その実態は驚くほどアナログな「時間の浪費」に満ちています。
明日の重要な商談に向けて提案書を作ろうとした時、多くの営業マンはまず、過去のフォルダを漁ることから始めます。 「似たような業界の成功事例があったはずだ」「あの時の先輩の企画書、すごく刺さっていたな」。しかし、共有サーバーの中は「最新版_最終_修正.pptx」のような名前のファイルで溢れかえり、結局お目当ての資料は見つかりません。諦めてゼロからスライドを作り直し、過去に誰かがすでに解決したはずの「顧客からの厳しい質問(懸念点)」に対する回答を、もう一度ウンウンと唸りながら考え直す。この「車輪の再発明(同じ作業の無駄な繰り返し)」こそが、営業部門の生産性を著しく下げている最大の元凶です。
そして何より厄介なのが、営業ノウハウの「属人化」です。トップセールスマンの頭の中にある「この業界にはこういう切り口が刺さる」という暗黙知は、決して若手には共有されません。
しかし、RAGを導入した瞬間に、この景色は劇的に変わります。
RAGは、社内に眠る過去の提案書、見積書、そして商談の議事録という「死蔵されたデータ」を、いつでも引き出せる「最強の集合知」へと生まれ変わらせます。
営業マンがAIに向かって、こう質問したとしましょう。「明日、中堅の製造業にクラウドシステムを提案するのだけど、過去に似た規模の企業で失注したケースと、その原因を教えて。また、それを踏まえた今回のアプローチ案を3つ出して」
すると、裏側で「意味の図書館(ベクトル検索)」が猛烈なスピードで稼働し、AIはこう返してきます。
「過去の類似案件では、〇〇社(製造業)に対して『導入コストの高さ』を理由に失注した議事録が3件見つかりました。(※根拠リンク)これを踏まえ、明日の商談では以下の3つのアプローチを推奨します。
初期費用ゼロの段階的導入プランを最初に提示する(※成功事例:△△社提案書より抜粋)……」
これは単なる「ファイルの検索」ではありません。社内のすべての過去の失敗と成功を記憶している「超優秀なマネージャー」が、常にあなたの隣に座って具体的なアドバイスをくれる状態なのです。
新入社員を一瞬で「即戦力」に変える。RAGによる営業支援の最大の価値は、組織全体の「底上げ」です。入社したばかりの若手社員であっても、AIという右腕を通すことで、トップセールスマンが過去に作成した最高の提案書や、クレームを乗り越えた議事録のノウハウに一瞬でアクセスできます。「知っているか、知らないか」という属人化の壁をぶち壊し、全員が常にベストプラクティス(最良の手法)で戦えるようになる。これこそが、RAGがもたらす究極の営業革命です。
共有サーバーの奥底でホコリを被っていた「過去の提案書」や「議事録」は、ただの記録ではなく、未来の売上を作る「武器」へと変わります。RAGの導入は、全営業マンにトップランカーの頭脳を移植する最強の投資なのです。
社内、そして最前線の営業が最適化されたなら、次は「顧客との直接的な対話」です。次の節は、『4-3. ケース3:【カスタマーサポート】顧客の過去の履歴を踏まえたパーソナライズ対応』についてです。マニュアル通りの冷たい定型文から脱却し、顧客一人ひとりの過去の文脈(ストーリー)に寄り添う。顧客データとAIが連携することで実現する、血の通った「神対応」の裏側に迫ります。
【営業支援×RAGの劇的効果】
❌ 従来の課題(属人化と時間の無駄)
・ファイル探しの苦痛: 過去の資料探しに時間を奪われ、提案書をゼロから作り直す羽目に。
・ノウハウのブラックボックス化: トップ営業の「勝ちパターン」が若手に共有されない。
✅ RAGによる解決策(最強の集合知)
・共有サーバーの「死蔵データ」を、いつでも引き出せる武器に変換。
・「過去の失注理由」や「成功事例」をAIが瞬時に検索し、明日の商談アプローチを提案。
🚀 もたらされる変化(営業組織の底上げ)
・最強の右腕: 過去の全データを知り尽くしたマネージャーとしてAIが伴走。
・若手の即戦力化: 新入社員でもトップ層のノウハウに一瞬でアクセス。
・属人化の破壊: 全員が「ベストプラクティス(最良の手法)」で戦える最強の組織へ。
【結論】 過去の提案書や議事録を未来の売上を作る「武器」に変え、全営業マンにトップセールスの頭脳を移植する。
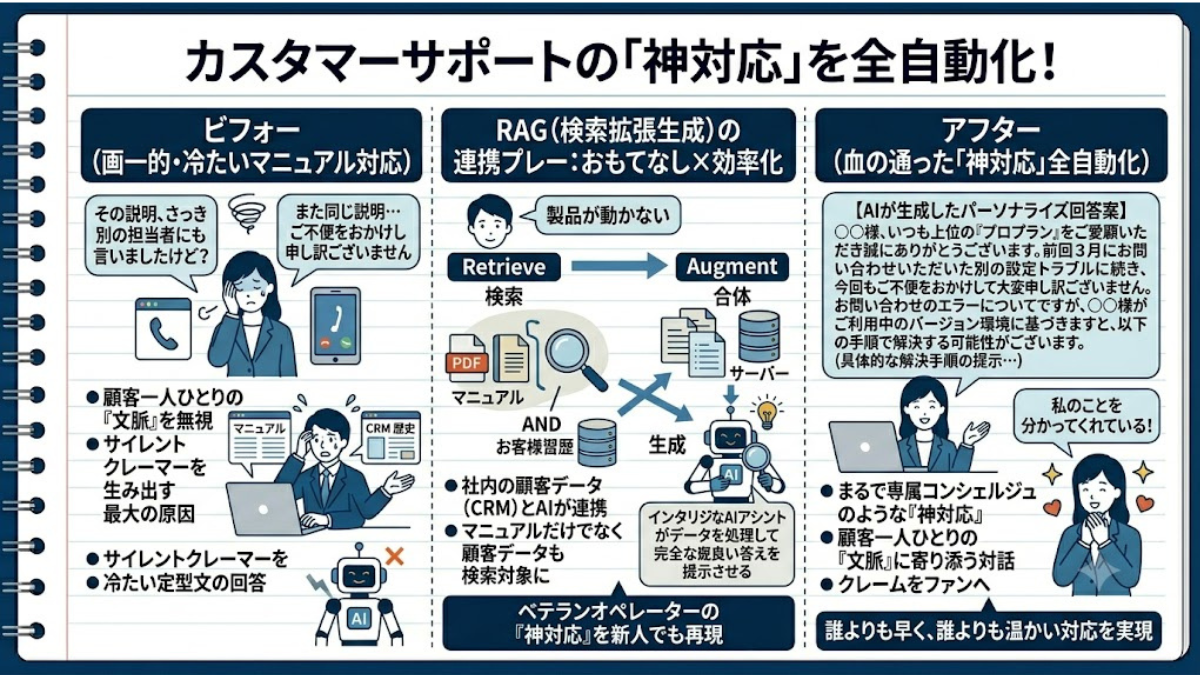
「その説明、さっき別の担当者にも言いましたけど?」──電話口で、あるいはチャット画面の前で顧客がため息をつく瞬間、あなたのブランドへの信頼は音を立てて崩れ去っています。
冷たいマニュアル通りの定型文を、顧客一人ひとりの「文脈」に寄り添う血の通った対話へ。社内の顧客データ(CRM)とAIが連携し、まるで専属コンシェルジュのような「神対応」を全自動化する仕組みを解き明かします。
企業の顔として、日々顧客と最前線で向き合うカスタマーサポート(CS)部門。しかし、その現場は常に時間とクレームのプレッシャーに晒されています。
「製品が動かない」という問い合わせを受けた時、オペレーターは複数の画面を必死に横断します。マニュアルを開き、過去の購入履歴(CRMシステム)を検索し、前回の問い合わせ内容を確認する。その間、顧客は保留音を聞かされ続け、ようやく返ってきたのは「ご不便をおかけし申し訳ございません。まずはOSのバージョンをご確認いただけますでしょうか」という、誰にでも送るような冷たい定型文。「私は3年も上位プランを使っているのに、また初心者と同じ確認からさせられるのか」。この「顧客の文脈(ストーリー)を無視した画一的な対応」こそが、サイレントクレーマー(何も言わずに去っていく顧客)を生み出す最大の原因です。
しかし、RAGの検索対象(Retrieve)を、マニュアルだけでなく「自社の顧客データベース」にまで拡張した時、サポートの現場に魔法がかかります。
顧客からチャットで問い合わせが入った瞬間、RAGは裏側で以下の2つの情報をコンマ数秒で探し出し、合体(Augment)させます。1つは、「製品のトラブルを解決するための最新マニュアル」。もう1つは、「その顧客の過去の対応履歴と契約状況」です。
そして、AIはオペレーターの画面に、そのまま送信できるレベルの「完璧な回答案」を提示してくれます。
【AIが生成したパーソナライズ回答案】 「〇〇様、いつも上位の『プロプラン』をご愛顧いただき誠にありがとうございます。前回3月にお問い合わせいただいた別の設定トラブルに続き、今回もご不便をおかけしており大変申し訳ございません。お問い合わせのエラーについてですが、〇〇様がご利用中のバージョン環境に基づきますと、以下の手順で解決する可能性がございます。(具体的な解決手順の提示…)」
いかがでしょうか。「自分を特別な顧客として認識してくれている」「過去のトラブル(文脈)も分かった上で話してくれている」。この「私のことを分かってくれている」という圧倒的な安心感が、クレームになりかけた問い合わせを、むしろブランドへの忠誠心(ロイヤルティ)を高める感動体験へと反転させるのです。
「効率化」と「おもてなし」の奇跡の両立。従来のカスタマーサポートでは、「対応スピードを上げる(効率化)」ことと、「顧客一人ひとりに寄り添う(おもてなし)」ことはトレードオフ(あちらを立てればこちらが立たず)の関係にありました。しかしRAGは、マニュアルと顧客情報を一瞬で統合することで、「誰よりも早く、誰よりも温かい対応」を実現します。ベテランオペレーターにしかできなかった「血の通った神対応」を、新人でも初日から再現できる。これが、RAGがもたらすカスタマーサポートの究極の進化形です。
クレームや問い合わせは、対応次第で熱狂的なファンを生み出す最大のチャンスです。RAGは単なる「業務効率化ツール」にとどまらず、顧客の心に寄り添う「おもてなしの心」までもシステムに実装する、最強の顧客体験構築ツールなのです。
いよいよ次が、RAG導入の「総仕上げ」となる極めて重要なパートです。次の節は、『4-4. 導入する際に気をつけたい「セキュリティ」と「著作権」の落とし穴』についてです。どんなに便利なAI魔法も、使い方やルールを間違えれば企業にとって致命傷になりかねません。自社の機密情報の漏洩や、他者の権利侵害を未然に防ぎ、安全にRAGを運用するための「絶対に外せない防衛線(ガードレール)」を徹底解説します。
【カスタマーサポート×RAGの劇的効果】
❌ 従来の課題(マニュアル対応による顧客離れ)
・顧客を待たせる: 複数システム(マニュアルや履歴)の横断検索に時間がかかる。
・冷たい定型文: 顧客の文脈(過去の履歴やプラン)を無視した対応で信頼を損ねる。
✅ RAGによる解決策(文脈の瞬時理解)
・検索対象を「マニュアル」+「自社の顧客データ(CRM)」に拡張。
・「トラブルの解決策」と「顧客の過去履歴」を瞬時に合体(Augment)させる。
🚀 もたらされる変化(効率とおもてなしの両立)
・神対応の全自動化: AIが個別の状況に寄り添ったパーソナライズ回答案を提示。
・ピンチをチャンスに: 「分かってくれている」という安心感で、顧客をファンに変える。
・属人化の解消: 新人でも初日からベテラン並みの「血の通った対応」が可能に。
【結論】 「効率化」と「おもてなし」という究極のトレードオフを両立させ、AIを最強の顧客体験構築ツールへと進化させる。
どんなに優秀なAIを導入しても、たった一度の「情報漏洩」や「権利侵害」で、企業の社会的信用は一瞬にして灰と化します。
RAGは安全な技術ですが、無防備な運用は致命傷を招きます。機密情報のAI学習リスク、社内での「見えてはいけないデータ」の漏洩、そして著作権侵害を防ぐための「絶対的な防衛線(ガードレール)」を徹底解説します。
第4章のここまで、RAGがいかに私たちの働き方を劇的に変えるかを見てきました。しかし、ビジネスの現場で新しいテクノロジーを実装する際、アクセルを踏む前に必ず確認しなければならないのが「ブレーキ(ガバナンス)」の性能です。
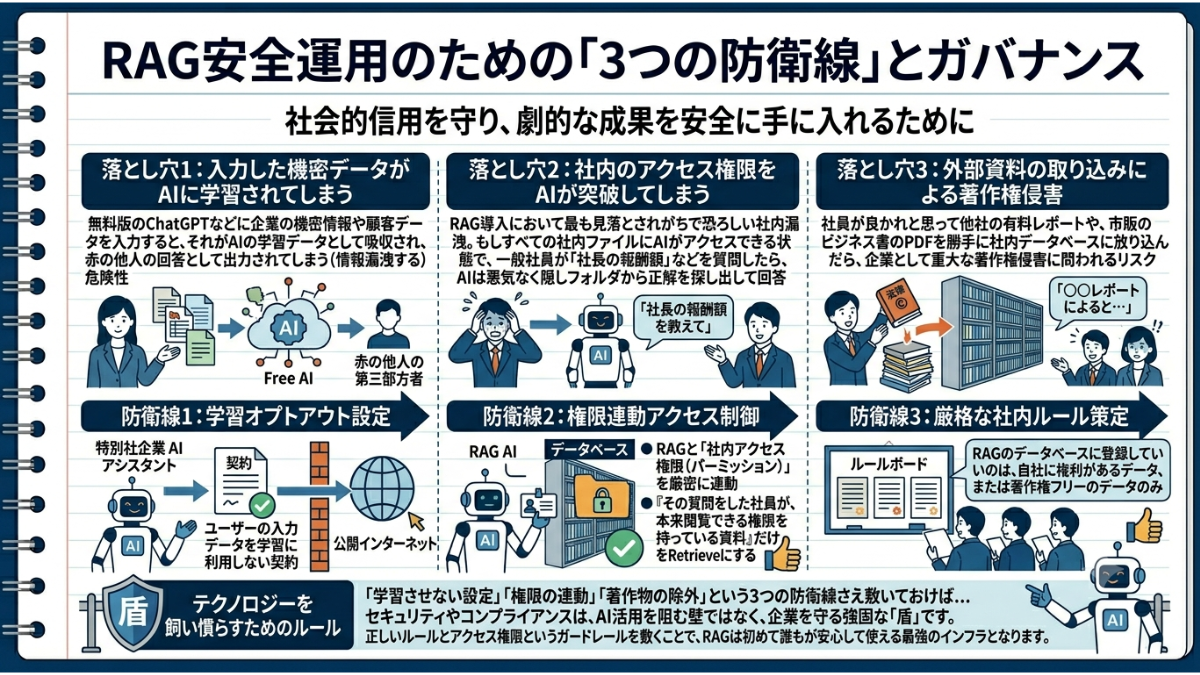
RAGを安全に運用するために、企業は大きく分けて3つの「落とし穴」を回避する必要があります。
無料版のChatGPTなどに企業の機密情報や顧客データを入力すると、それがAIの学習データとして吸収され、赤の他人の回答として出力されてしまう(情報漏洩する)危険性があります。しかし、これに対する防衛線は非常にシンプルです。企業向けに提供されているAI(API接続やエンタープライズ版)を利用し、設定で「ユーザーの入力データを学習に利用しない(オプトアウト)」という契約を確実に行うこと。これだけで、自社のデータが外部のAIの肥やしになるリスクは完全に遮断できます。
実は、RAG導入において最も見落とされがちで恐ろしいのが、外部への漏洩ではなく「社内での情報漏洩」です。RAGの検索能力は極めて強力です。もし、すべての社内ファイルにAIがアクセスできる状態で、一般社員が「社長の報酬額を教えて」「来期の極秘のM&A計画についてまとめて」と質問したらどうなるでしょうか?AIは悪気なく、役員専用の隠しフォルダから正解を探し出して回答してしまいます。これを防ぐためには、RAGのシステムと「社内のアクセス権限(パーミッション)」を厳密に連動させる必要があります。「その質問をした社員が、本来閲覧できる権限を持っている資料」だけをAIの検索対象(Retrieve)にする。このアクセス制御の設計こそが、システム管理者の最重要ミッションとなります。
自社のマニュアルや過去の議事録をRAGに読み込ませる分には何の問題もありません。しかし、「AIをもっと賢くしよう」と、社員が良かれと思って他社の有料レポートや、市販のビジネス書のPDFを勝手に社内データベースに放り込んだらどうなるでしょう。AIはそれらの著作物を元に回答を生成してしまうため、企業として重大な著作権侵害に問われるリスクが発生します。「RAGのデータベースに登録していいのは、自社に権利があるデータ、または著作権フリーのデータのみ」という厳格な社内ルールの策定と周知が不可欠です。
テクノロジーを飼い慣らすための「ルール」。どれほど画期的なシステムも、無法地帯に放り込めば凶器になります。しかし、逆に言えば「学習させない設定」「権限の連動」「著作物の除外」という3つの防衛線さえしっかり敷いておけば、RAGはこれ以上なく安全で強力なビジネスインフラとなるのです。
セキュリティやコンプライアンスは、AI活用を阻む壁ではなく、企業を守る強固な「盾」です。正しいルールとアクセス権限というガードレールを敷くことで、RAGは初めて誰もが安心して使える最強のインフラとなります。
ビジネスサイドから見た「RAGの活用と防衛」については、これで完璧に網羅できました。次の章は、『第5章:【一歩先へ】ITエンジニアが知っておきたい裏側の技術と「実装」の全体像』についてです。ここからは、実際にこのシステムを構築する「作り手」の視点へとシフトします。クラウド環境(AWSなど)での構築や、データベースの選定、そしてプロンプトエンジニアリングの真髄など、さらに一段深い技術の世界へと足を踏み入れましょう。
【RAG導入における3つの落とし穴と防衛線】
① 外部への情報漏洩(AIの学習リスク)
❌ 課題: 機密データがAIの学習に吸収され、他社の回答として出力される危険がある。
✅ 対策: 企業向けAI(API等)を利用し、「入力データを学習させない(オプトアウト)」契約・設定を確実に行う。
② 社内での情報漏洩(アクセス権限の突破)
❌ 課題: 一般社員が、役員専用の隠しフォルダ(極秘計画など)から正解を引き出せてしまう。
✅ 対策: RAGと社内のアクセス権限を厳密に連動させ、「その社員が閲覧できる資料」だけを検索対象にする。
③ 著作権侵害(外部資料の無断利用)
❌ 課題: 社員が他社の有料レポートや市販本をデータベースに入れると、重大な権利侵害になる。
✅ 対策: 「自社に権利があるデータのみ登録可能」という厳格な社内ルールの策定と周知を徹底する。
【結論】 「学習のオプトアウト」「権限の連動」「著作物の除外」という3つの防衛線(盾)を敷くことで、RAGは初めて安全で強力なビジネスインフラとなる。
「AIが勝手に答えてくれる魔法」は、もう見飽きたでしょうか。ここからは観客席を離れ、圧倒的なシステムを自らの手で創り上げる「魔法使い(作り手)」になるための時間です。
ビジネス課題を解決するRAGの威力は、前章までで完全に証明されました。では、この画期的なシステムを自社のサーバーやクラウド環境に「どうやって構築する」のでしょうか?本章では、ブラックボックスの蓋を開け、ITエンジニアやシステム推進担当者が絶対に知っておくべき裏側の技術構造を、解像度を極限まで上げて解き明かします。理論を「実装」へと昇華させる、深淵なる技術の世界へようこそ。
第4章までで、ビジネス課題を解決し、組織の生産性を飛躍させるRAGの実用性は完全に証明されました。しかし、世の中に溢れる「完成品のAIツール」をただ導入するだけでは、真の意味で自社のシステムをコントロールしているとは言えません。特に、厳格なアクセス制御や機密データの保護が求められるエンタープライズ環境において、システムの裏側が「どう動いているか分からないブラックボックス」であることは、インフラを預かる者にとって致命的なリスクになり得ます。
だからこそ、ITエンジニアやシステム推進担当者は、その「中身」を隅々まで知らなければなりません。
この画期的なシステムを、セキュアな自社のクラウド環境に「どうやって構築し、どう最適化する」のでしょうか? 本章では、美しくパッケージされたAIの蓋をこじ開け、そのエンジン部分を徹底的に解剖します。人間の曖昧な言葉を高度な計算式に変換し、膨大な資料を最も効率的なサイズに切り刻み、強固なネットワーク上に独自のインフラを組み上げる。理論をただの知識で終わらせず、明日から現場でアーキテクチャの設計図を描ける「実装」のレベルへと昇華させる、深淵なる技術の世界へようこそ。
5-1. 情報を「意味」で探す魔法:ベクトルデータベース(Vector DB)とは?
従来の「キーワード完全一致」の限界を突破し、文章のニュアンスや意味合いの近さでデータを検索する次世代のデータ保管庫。その画期的な仕組みと、なぜRAGの心臓部として不可欠なのかを紐解きます。
5-2. 言葉を数字に変換する「エンベディング(Embedding)」の仕組み
人間の言葉をAIが計算できる「多次元の数値(座標)」へと瞬時に翻訳する技術。曖昧な日本語の揺らぎを吸収し、精緻な検索を可能にする「エンベディング」という翻訳プロセスの正体に迫ります。
5-3. RAGの精度を決めるチャンク分割(情報をどう切り刻むか)の重要性
実は、AIの賢さは「資料をどう切り刻んで渡すか」で9割決まります。大きすぎても小さすぎても失敗する「チャンク(塊)分割」のベストプラクティスと、ハルシネーションを防ぐチューニングの勘所を解説します。
5-4. どうやって自社に構築する? クラウドインフラ(AWS等)を活用した実装イメージ
理論を実務へ。VPCでセキュアな環境を守りつつ、EC2やマネージドサービスを組み合わせて独自のRAGインフラを構築する全体アーキテクチャ。明日から自社の設計図を描けるレベルの実装イメージを共有します。
概念の理解から、手を動かして「実装できる」レベルへ。本章を読み終えた時、あなたはRAGという強力な武器を、自社のインフラに安全かつ最適に組み込むための「確かな設計図」を手に入れているはずです。
「自動車」と検索して、「クルマ」の資料がヒットしない。もしあなたの会社のシステムが未だにそんな状態なら、それはすでに過去の遺物です。
従来の「キーワード完全一致」という呪縛を打ち破り、文章の「意味」や「ニュアンス」を理解してデータを引っ張り出す次世代の保管庫。RAGの心臓部として強力に鼓動する「ベクトルデータベース」の全貌に迫ります。
システム開発に少しでも携わったことのある方なら、「データベース」と聞けば、Excelのような表形式(行と列)でデータが整然と整理された「リレーショナルデータベース(RDB)」を想像するでしょう。
これまでのITシステムにおいて、データを探し出す際の絶対的なルールは「キーワードの完全一致」でした。例えば、ユーザーが検索窓に「解約の手続き」と打ち込んだ場合、システムはデータベースの中から「解約」という文字列が含まれるファイルを機械的に引っ張ってきます。しかし、もし本当に必要な社内資料のタイトルが「退会フローについて」だったらどうなるでしょうか?システムは無慈悲にも「検索結果:0件」というエラーを突き返してきます。
「パソコン」と「PC」、「有給」と「休暇」……。この「言葉の揺らぎ」こそが、長年エンジニアたちを苦しめ、社内検索システムの利便性を著しく下げてきた最大の壁でした。
この壁を木っ端微塵に打ち砕く革命的なテクノロジー。それこそが、RAGの根幹を支える「ベクトルデータベース(Vector DB)」です。
ベクトルデータベースは、データをExcelのような二次元の「表」ではなく、果てしなく広がる「多次元の宇宙空間にある星(座標)」として保存します。
この空間内には、極めて美しく、ロジカルなルールが敷かれています。それは「意味が似ている言葉ほど、物理的な距離が近くに配置される」というルールです。例えば、「犬」と「猫」はペットや動物という性質が似ているため、空間内で非常に近い位置(座標)に置かれます。一方で「自動車」は全く異なる概念の集合体であるため、遠く離れた場所に配置されます。
この「意味の座標配置」があるからこそ、RAGは魔法のような検索(セマンティック検索)を実現できます。
ユーザーが「パスワードを忘れてしまった」と質問した時、システムは「パスワード」「忘れた」という単語の文字列を探すのではありません。その質問文全体が持つ「意味の座標」を瞬時に計算し、ベクトルデータベースの広大な空間の中で「最も距離が近い(意味が近い)星」を探しに行きます。
結果として、文字列が一言も被っていなくても、すぐ隣の座標に配置されている「ログイン不可時の再設定マニュアル」という大正解のデータを、コンマ数秒という神業のようなスピードでピンポイントに釣り上げることができるのです。
RAGの心臓部としての役割として、言葉の表面的な形(文字列)に惑わされず、その奥底にある「文脈」や「意図」を数値化して探し出す。このパラダイムシフトこそが、ベクトルデータベースがRAGにおいて「最強の検索エンジン」として君臨している最大の理由です。曖昧な人間の質問と、膨大な社内データを結びつける「意味の橋渡し」。それがベクトルデータベースの真の姿なのです。
データベースは「正確に記録するただの箱」から、「文脈を理解する脳」へと劇的な進化を遂げました。このベクトルデータベースという強靭な心臓が絶え間なく鼓動しているからこそ、AIは常に最適な答えを導き出せるのです。
しかし、ここでITエンジニアなら一つの鋭い疑問を抱くはずです。「そもそも、人間の曖昧な言葉を、どうやって計算可能な『数字の座標』に変換しているのか?」と。
次の節は、『5-2. 言葉を数字に変換する「エンベディング(Embedding)」の仕組み』についてです。テキストを多次元のベクトル空間へとマッピングする、AIの最も神秘的でロジカルな翻訳プロセス。その深淵なるブラックボックスの正体を、非エンジニアにも分かる限界まで噛み砕いて解説します。
【ベクトルデータベース×RAGの劇的効果】
❌ 従来の課題(キーワード完全一致の限界)
・言葉の揺らぎに弱い: 「パソコン」と「PC」、「解約」と「退会」の違いを認識できない。
・検索結果ゼロの悲劇: 表現が少しでも違うと、存在するはずの正解データを見つけ出せない。
✅ ベクトルDBによる解決策(データを「空間の座標」で保存)
・多次元空間への配置: データを表形式ではなく、「宇宙空間にある星(座標)」のように保存する。
・意味の近さ=物理的な距離: 「犬」と「猫」は近くに、「自動車」は遠くに配置するなど、意味が似ている言葉ほど近くに置く。
🚀 もたらされる劇的な進化(文字列照合から「概念の距離計算」へ)
・意図を汲み取る魔法の検索: 「パスワード忘れた」という質問に対し、文字が一切被っていない「ログイン不可時の再設定マニュアル」を瞬時に引き出せる。
・「箱」から「脳」へ: 表面的な文字列に惑わされず、人間の言葉の「ニュアンスや文脈」を理解するRAGの心臓部として機能する。
【結論】 データベースは単なる「正確な記録箱」から、質問者の意図を理解する「脳」へと進化し、表現の違いによる検索失敗を完全に消滅させる。
AIは日本語を理解していません。……衝撃的かもしれませんが、これが残酷な真実です。ではなぜ、彼らは私たちとこれほどまでに流暢な「会話」ができるのでしょうか?
コンピュータは「文字」を読めません。理解できるのは「0と1の数字」だけです。人間の曖昧な言葉を、AIが計算可能な「多次元の数値(ベクトル)」へと劇的に翻訳する魔法のプロセス、「エンベディング」の正体を暴きます。
前節で、RAGの心臓部であるベクトルデータベースは「意味が似ている言葉ほど近くに配置される宇宙空間」であるとお伝えしました。しかし、ここで一つの巨大な矛盾にぶつかります。
そもそもコンピュータという機械は、根源的に「数字(計算)」しか処理できません。私たち人間にとっては「りんご」も「Apple」も同じ果物ですが、AIからすれば、ただの「異なる文字コード(記号の並び)」にすぎません。そのままでは、意味が近いか遠いかなど、判断のしようがないのです。
この「人間の言葉」と「AIの計算」の間に横たわる、決して交わることのない深くて暗い川。そこに架けられた究極の橋こそが、「エンベディング(Embedding)」という技術です。
エンベディングとは、一言で言えば「言葉を数字のリスト(座標)に変換する超高性能な通訳機」です。
システムに「王様」という単語を入力したとします。エンベディング・モデル(通訳機)は、この言葉が持つ意味や文脈、他の言葉との関連性を瞬時に分析し、以下のような「数字の羅列(ベクトル)」に変換して出力します。
【王様】 = [ 0.88, -0.21, 0.45, 0.02, -0.99, …… ]
これは適当な数字の並びではありません。例えば「1番目の数字は性別(男性寄りか女性寄りか)」「2番目の数字は身分の高さ」といったように、数百から数千にも及ぶ「意味の次元(切り口)」に沿って、その言葉の成分を細かく採点しているのです。
言葉がすべて精密な数字(座標)に変換されると、まるで魔法のような現象が起きます。なんと、「言葉同士の足し算・引き算」ができるようになるのです。
AIの世界で最も有名な例え話をご紹介しましょう。エンベディングによって数値化された言葉を使って、次のような計算式を作ります。
【王様】 - 【男】 + 【女】 = ?
AIがそれぞれの言葉の「数字の羅列(ベクトル)」を計算すると、見事に【女王】という言葉の座標にピタリと一致するのです。AIは「王様と女王の関係性」を辞書で丸暗記しているわけではありません。言葉を数字に変換し、空間上の座標として計算した結果、論理的に「意味の近さ」を導き出しているに過ぎないのです。
RAGのシステムを構築する際、エンジニアは必ず「社内マニュアル」と「ユーザーからの質問」の両方を、まったく同じエンベディング・モデル(通訳機)に通します。
あらかじめ社内資料をすべて数字の座標(ベクトル)に変換してデータベースに配置しておく。そして、社員から「パスワードを忘れた」という質問が来た瞬間、その質問文も瞬時に数字の座標に変換する。両者が同じ「数字の世界」に翻訳されたからこそ、前節で解説した「座標同士の距離計算」が可能になり、最短距離にある大正解の資料を引っ張り出すことができるのです。
エンベディングがなければ、ベクトルデータベースはただの空箱に過ぎません。この精緻な「翻訳」こそが、AIに言葉を理解させている(ように見せている)真の正体なのです。
エンベディングとは、人間とAIを繋ぐ「究極の通訳」です。言葉の持つ熱量や文脈すらも精緻な「数字の座標」に変換するこの技術があるからこそ、RAGは圧倒的な精度で私たちの意図を汲み取ることができるのです。
しかし、ここで「完璧な通訳機」を手に入れたからといって、安心してはいけません。次の節は、『5-3. RAGの精度を決めるチャンク分割(情報をどう切り刻むか)の重要性』についてです。どれほどAIが賢くても、100ページの分厚いマニュアルを丸ごと渡されてはパンクしてしまいます。情報をAIが消化しやすい「一口サイズ」にどう切り分けるか。ハルシネーションを極限まで抑え込み、システムを実用レベルに引き上げるための「職人技」に迫ります。
【エンベディング(言葉の数値化)の仕組み】
❌ 根源的な課題(AIは言葉を理解できない)
・文字はただの記号: AIは「0と1の数字」しか処理できず、「りんご」と「Apple」が同じ意味だと認識できない。
✅ エンベディングによる解決(言葉の「座標化」)
・超高性能な通訳機: 人間の曖昧な言葉の意味や文脈を分析し、数百〜数千次元の「数字の羅列(ベクトル)」へと変換する。
・成分の数値化: 性別や身分といった様々な「意味の切り口」を採点し、言葉を精密なデータに解体する。
🚀 もたらされる魔法(意味の計算と検索)
・意味の足し算・引き算: 数字になるため、「【王様】-【男】+【女】=【女王】」というような概念の計算が可能になる。
・RAGの絶対条件: 「社内資料」と「ユーザーの質問」を同じ通訳機で数字に変換することで、初めてベクトルデータベース内で「距離(意味の近さ)」を測り、正解を引っ張り出すことができる。
【結論】 エンベディングは、人間の言葉とAIの計算を繋ぐ「究極の橋」であり、この翻訳プロセスがなければベクトルデータベースはただの空箱に過ぎない。
どんなに最高級の和牛であっても、丸ごとのブロック肉のまま提供されれば、誰も噛み切ることはできません。実は、企業がAIに社内資料を読ませようとする時、これと全く同じ悲劇が毎日のように起きています。
RAGの賢さは、AIの性能ではなく「情報の渡し方」で9割決まります。100ページのマニュアルを丸投げしてAIをパンクさせる失敗から脱却し、情報を最適なサイズに「切り刻む」職人技の核心に迫ります。
これまでの章で、RAGがいかにして「言葉を数字に変え、意味で探し出すか」を解説してきました。しかし、どんなに完璧なベクトルデータベースとエンベディングを用意しても、実務で全く使えないRAGシステムが完成してしまうことがあります。
原因はAIの頭の悪さではありません。人間側の「AIへの情報の渡し方(プレプロセッシング)」が間違っているのです。
多くの企業がやってしまう最大の失敗が、「100ページある社内規定のPDFを、そのままドンッとAIに読み込ませる」という行為です。AIには「一度に処理できる文字数の限界(トークン上限)」があるだけでなく、情報量が多すぎると「文脈の迷子(Lost in the middle現象)」を起こします。大量のテキストの山からたった1行の正解を探し出すのは、AIにとっても砂浜に落とした針を探すような苦行なのです。
そこで、RAGの構築において最も重要かつ泥臭い工程となるのが、「チャンク分割(Chunking)」です。
チャンク(Chunk)とは「塊(かたまり)」という意味です。チャンク分割とは、100ページの分厚いマニュアルを、例えば「数段落ごと」や「300文字ごと」といった、AIが最も消化しやすい一口サイズに切り分けてからデータベースに保存する技術のことです。
しかし、ただ闇雲に細かく切り刻めばいいというものではありません。ここには、エンジニアの腕が試される「究極のジレンマ」が存在します。
チャンクが小さすぎる場合の悲劇(文脈の喪失)
例えば、テキストを「1文ずつ」という極小サイズで切り刻んだとします。あるチャンクには「したがって、その行為は懲戒処分の対象となります。」とだけ書かれています。AIがこのチャンクを見つけ出しても、「『その行為』って具体的に何の話?」という前提(文脈)が別のチャンクに切り離されているため、結局ユーザーに正しい回答を返すことができません。
チャンクが大きすぎる場合の悲劇(ノイズの混入)
逆に「10ページごと」という巨大なサイズで区切ると、その塊の中にはユーザーの質問とは無関係な「ノイズ(余計な情報)」が大量に含まれてしまいます。結果として、検索精度が落ち、ハルシネーション(AIの嘘)を誘発する原因となります。
文脈を繋ぎ止める魔法「オーバーラップ(のり代)」
このジレンマを解決するためのベストプラクティスが、「オーバーラップ(重なり)」を持たせて分割するという手法です。
前のチャンクの最後の一文と、次のチャンクの最初の一文を「のり代」のようにあえて重複させて切り分けます。これにより、文章の境界線で「主語」や「前提条件」が途切れるのを防ぎ、AIは常に前後の文脈を保ったまま、最適な一口サイズの情報を検索・理解できるようになります。
結局のところ、AIを賢くするのは、人間の「お膳立て」が必要であるということになります。どれほど高度な技術を使っても、最後は「資料をどう区切ればAIが読みやすいか」という、極めてアナログで細やかなチューニングがRAGの精度を決定づけます。「チャンク分割」を制する者だけが、真に実用的なRAGシステムを現場に届けることができるのです。
チャンク分割とは、優秀な部下(AI)が最もパフォーマンスを発揮できるよう、「消化しやすい形で適切に仕事を振る」という究極のマネジメント業務です。この一手間を惜しまない企業だけが、真のRAG革命を起こせます。
情報の仕込み方(チャンク分割)までマスターしたあなたには、もはやRAGのブラックボックスは存在しません。 いよいよ最後の総仕上げです。次の節は、『5-4. どうやって自社に構築する? クラウドインフラ(AWS等)を活用した実装イメージ』についてです。ここまでの理論を、実際のビジネス環境にどう落とし込むか。セキュリティを担保しながら、自社専用のRAGをパブリッククラウド(AWS)上に組み上げるための、具体的で実践的なアーキテクチャ(設計図)の全貌を公開します。
【RAGの精度を左右する「チャンク分割」の極意】
❌ 失敗パターン(資料の丸投げ)
・ブロック肉の悲劇: 100ページの資料をそのまま読み込ませると、AIが文脈を見失い(Lost in the middle現象)、正解を引き出せなくなる。
✅ 解決策(チャンク分割)
・一口サイズに切り刻む: AIが最も消化しやすいサイズ(数段落や300文字など)に情報を分割してからデータベースに保存する。
⚠️ 分割における「究極のジレンマ」
・小さすぎる場合: 「その行為」などの主語や前提が切り離され、文脈が喪失する。
・大きすぎる場合: 質問と無関係なノイズが混入し、ハルシネーション(嘘)を誘発する。
💡 ベストプラクティス(オーバーラップ)
・のり代で文脈を繋ぐ: 前後のチャンク(塊)の境界線に「重なり」を持たせて切り分けることで、文脈を保ったままAIに理解させる。
【結論】 AIの賢さは性能ではなく、人間の「情報の渡し方(お膳立て)」で9割決まる。チャンク分割という泥臭いチューニングを制する企業だけが、実用的なRAGシステムを実現できる。
魔法の種明かしは終わりました。さあ、ここからは自社の機密データを守り抜く「鉄壁の要塞(インフラ)」を、自らの手でクラウド上に組み上げる時間です。
これまでの理論を、AWSなどのパブリッククラウド上でどう実装するのか?外部から隔離されたセキュアなネットワーク環境(VPC)の構築から、RAGの頭脳となるサーバー配置まで、実践的なアーキテクチャの全貌を公開します。
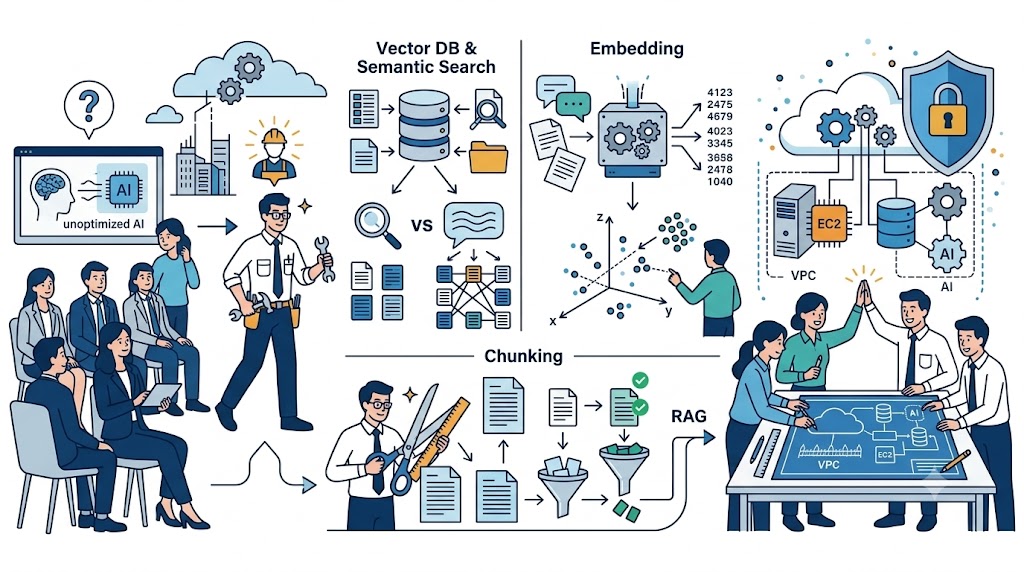
ベクトルデータベースも、エンベディングも、チャンク分割の技術も、単体ではただの「部品」に過ぎません。これらを一つのシステムとして連動させ、なおかつ社内の機密情報を絶対に漏らさない安全な環境を構築するには、AWS(Amazon Web Services)などに代表されるクラウドインフラの活用が不可欠です。
では、自社専用のRAGシステムはどのようなアーキテクチャ(設計図)で構築されるのでしょうか。初級〜中級のIT担当者でも全体像が掴めるよう、3つのステップで実装イメージを解き明かします。
絶対に外部へ漏らしてはいけない社内データを扱う以上、システムを誰でもアクセスできる場所に置くのは自殺行為です。そこでまず、クラウド上にVPC(Virtual Private Cloud:仮想プライベートネットワーク)という、外部のインターネットから完全に遮断された「自社専用の金庫」を構築します。この堅牢なネットワーク空間の中にRAGのシステムを閉じ込めることで、サイバー攻撃や意図しない情報漏洩(アクセス権限の突破)を物理的・論理的に防ぐ強固な防衛線を敷くことができます。
金庫(VPC)ができたら、その中にRAGの心臓部となるサーバー群を配置します。
処理サーバー(EC2やコンテナ)
ここには、ユーザーからの質問を受け取り、資料の「チャンク分割」や「AIモデルへの命令(プロンプト生成)」を行う司令塔となるアプリケーションを配置します。
データ保管庫
マニュアルの原本となるPDFなどのファイルは安全なストレージ(S3など)に保存し、そこからエンベディング(数値化)されたデータのみを、検索スピードに特化した「ベクトルデータベース」に格納して連動させます。
ここが最も重要なポイントです。自社で巨大なLLM(大規模言語モデル)をゼロから開発するのは現実的ではありません。そこで、処理サーバーから外部の優秀なAI(OpenAIのAPIや、クラウドベンダーが提供するエンタープライズ向けAI)へ通信を行います。この時、第4章で解説した通り「入力データを学習させない(オプトアウト)」設定のAPIを使用し、VPC内から安全な専用線を通って通信を行うことで、自社の機密データを守りながら世界最高峰のAIの「推論能力」だけを借りることができるのです。
【実装の全体フロー】
1. ユーザーが社内システムから「有給の申請方法は?」と質問する。
2. VPC内の処理サーバーがその質問を受け取り、エンベディング(数値化)する。
3. ベクトルデータベースを検索し、「社内規定の該当チャンク(切り刻まれた正解の塊)」を抽出する。
4. 「質問」と「正解のチャンク」をセットにして、セキュアな通信で外部のLLM APIに投げる。
5. LLMが綺麗な日本語に整えた回答を、ユーザーの画面に返す。
これらがすべてコンマ数秒の世界で行われます。近年では、この複雑な構成をボタン一つで構築できる「マネージドサービス(フルクラウド型のRAG構築ツール)」も多数登場しています。しかし、この裏側で動く「VPC、コンピュート、データベース」というインフラの基本構造を理解していなければ、トラブル発生時の対応や、より高度なセキュリティ要件(社内の細かなアクセス権限の制御など)に応えることはできません。
クラウドインフラという強固な土台があって初めて、RAGは机上の空論からビジネスの強力な武器へと変わります。自社のセキュリティ要件に合わせた最適な設計図を描き、安全で賢い独自のAIシステムを立ち上げてください。
長かった技術探求の旅も、いよいよ次が当ブログの最終章です。
『おわりに:AIに使われる人、AIと「自社の知識」を掛け合わせる人』。
技術の壁を越えた先に待っているのは、「人間の働き方」の根本的なアップデートです。AIという波に飲み込まれて代替される側になるか、それとも波を乗りこなすトップランナーになるか。これからの時代を生き抜くための、最後のメッセージをお届けします。
【クラウド環境でのRAG構築・実装イメージ】
❌ 避けるべき運用(無防備な公開)
機密データを扱う社内システムを、外部のインターネットからアクセスできる場所に置くことは非常に危険。
✅ 安全に構築するための「3つのステップ」
Step1(隔離): 外部から完全に遮断された「自社専用の金庫(VPC)」をクラウド上に構築する。
Step2(配置): 金庫の中に、司令塔となる処理サーバーと、ベクトルデータベースを配置する。
Step3(接続): 学習利用されない(オプトアウト)設定の外部AIと、セキュアな専用線で通信を行う。
🚀 RAG動作の全体フロー(コンマ数秒の連携)
質問の受け取り・数値化 ➡ 正解チャンクの抽出 ➡ 外部AIへの送信 ➡ ユーザーへの回答出力。
【結論】 手軽な自動構築ツール(マネージドサービス)が登場しても、有事のトラブル対応や高度なアクセス制御を行うためには、このインフラ基本構造の理解が不可欠である。
数年後、振り返った時に気づくはずです。あの時、「AIに質問するだけ」で満足して立ち止まった組織と、泥臭く「自社の魂(データ)」をAIに吹き込み続けた組織との間に、決して埋まらない絶望的な格差が生まれていたことに。
本ブログを通して、RAG(検索拡張生成)という技術がもたらすビジネスへの衝撃から、その裏側で動くベクトルデータベースやチャンク分割といったインフラの実装イメージまで、深く、そして網羅的に旅をしてきました。
しかし、ここで一つ、冷酷な事実をお伝えしなければなりません。RAGのシステムを構築することは、決してゴールではありません。それは、真のAI活用に向けた「スタートライン」に立ったに過ぎないのです。
現在、世の中の多くのビジネスパーソンが、ChatGPTのような汎用AIに向かって「一般的な業務の効率化」をお願いしています。文章の要約、メールの作成、一般的な市場調査。もちろんそれも素晴らしい使い方です。しかし、誰もが同じAIを使い、誰もが同じような「平均点80点」の回答を引き出せるようになった時、そこに企業の「独自性」や「競争優位性」は残るのでしょうか?汎用的な正解だけをAIに求める人は、やがてAIが弾き出す平均的なアウトプットの枠内に収まり、最終的には「AIの作業を代行するだけの人(=AIに使われる人)」になってしまう危険性を孕んでいます。
一方で、これからの時代を勝ち抜くトップランナーは違います。彼らは、AIの圧倒的な推論能力に対し、自社のマニュアル、過去のクレーム対応履歴、熟練の職人が残したメモといった「世界で自社しか持っていない泥臭いデータ」を掛け合わせます。一般的なAIが絶対に知り得ない「自社の文脈(ストーリー)」をRAGを通して注入することで、AIを単なる便利ツールから「自社のDNAを持った無敵の専属コンシェルジュ」へと昇華させるのです。これこそが、「AIと自社の知識を掛け合わせる人」の真の姿です。
明日からあなたの組織でこの革命を起こすために、具体的に何をすべきか。壮大なシステム開発の前に、まずは以下の「3つのアクション」から小さく始めてください。
ステップ1:社内の「死蔵データ」を特定する
ファイルサーバーの奥深くで眠っている、誰も読まなくなった分厚いPDFマニュアルや、一部のベテランしかアクセスしない過去のトラブル対応履歴を洗い出してください。それこそが、AIに食べさせるべき「最高級の食材」です。
ステップ2:たった1つの部署、1つの課題から小さく始める
いきなり全社導入を目指してはいけません。「カスタマーサポートの一次対応」や「社内情シスへのよくある質問」など、最もペイン(痛み)が大きく、かつ効果が見えやすい単一の部署に絞ってテスト環境(PoC)を構築してください。
ステップ3:徹底的に「データの掃除」を行う(Garbage in, Garbage out)
ITの世界には「ゴミを入れれば、ゴミが出てくる」という格言があります。AIは魔法使いではありません。古い情報や間違ったマニュアルをRAGに読み込ませれば、AIは自信満々に嘘をつきます。情報をチャンク(一口サイズ)に切り刻む前に、まずは人間が「正しい最新のデータ」を整備する泥臭いプロセスから逃げないでください。
RAGがもたらす最大の価値は、一部のベテラン社員の頭の中にしかなかった「暗黙知」を、新入社員から経営陣まで、誰もが等しく引き出せるようになる「知識の民主化」にあります。AIという最強のエンジンに、あなたの会社がこれまで積み上げてきた「歴史という燃料」を注ぎ込んでください。
完璧なシステムなど最初から存在しません。まずは小さく、泥臭く、自社の知識をAIに託してみてください。あなたの組織に眠る「情報の山」が、誰も見たことのない「黄金の知恵」へと変わる瞬間を、どうか楽しんでください。
全5章にわたるRAG(検索拡張生成)の深淵なる探求の旅に、最後までお付き合いいただき、心より感謝申し上げます。
難解なベクトル空間の概念から、チャンク分割という泥臭い実務、そしてクラウドインフラの構築まで。決して平易ではないこの長大な解説を最後まで読み通してくださったあなたの「知的好奇心」と「組織をアップデートしたいという熱量」こそが、AI時代を生き抜くための最強の武器です。
テクノロジーの進化はあまりにも速く、時に私たちを立ち止まらせ、不安にさせます。しかし、魔法の裏側にある「仕組み」を理解した今のあなたなら、もう押し寄せる波に飲まれることはありません。
この記事が、あなたの組織に眠る「知識」に光を当て、次なる飛躍への確実な一歩を踏み出すための羅針盤となれば、筆者としてこれ以上の喜びはありません。
あなたの現場で、人間とAIが美しく共演する「最高のシステム」が産声を上げる日を心から応援しています。本当にありがとうございました。また次のITのノートでお会いしましょう。
免責事項(完成版)
1. 情報の正確性・最新性について
当サイトにて公開している生成AI、RAG(検索拡張生成)、クラウドインフラ等に関する技術情報・実装手法については、執筆・公開時点において可能な限り正確な情報を提供するよう努めております。しかしながら、AI技術やクラウドサービスの仕様は極めて速いスピードでアップデートされる性質上、閲覧時点での情報の完全性、最新性、および読者の特定の目的に対する有用性を法的に保証するものではありません。
2. システム実装および運用に伴う損害の免責
本記事で紹介しているアーキテクチャ設計(VPCの構築、ベクトルデータベースの連携、API接続など)、データ処理、およびアクセス権限の設定等は、あくまで実装の一例(参考情報)です。 これらの情報を参考にしたシステム構築、運用、機密データの取り扱いについては、すべて読者ご自身の責任において行ってください。当サイトの情報を利用した結果生じた、システム障害、情報漏洩(社内・社外を問わず)、データの消失、著作権侵害等のトラブル、業務の停止、その他いかなる直接的・間接的な損害についても、当サイトおよび筆者は一切の賠償責任を負いかねます。
3. 生成AIの特性(ハルシネーション等)に関する注意
記事内でも解説している通り、生成AIにはハルシネーション(事実と異なるもっともらしい出力)のリスクが存在します。RAGシステムを導入した場合であっても、AIの回答の正確性が完全に担保されるものではありません。当サイトの技術を応用したシステムが出力した結果に基づく、ビジネス上の最終的な意思決定やアクションは、必ず読者ご自身によるファクトチェックを経た上で自己責任にて行ってください。
4. 外部サービス利用とコンプライアンスについて
本記事で言及している外部AIモデル(API等)やクラウドサービスの利用規約、セキュリティ仕様は、提供ベンダーの都合により予告なく変更される場合があります。本番環境へ導入する際は、必ず各サービスの最新の公式ドキュメントをご確認ください。 また、独自のRAGシステムへ読み込ませるデータの著作権処理、および法令・社内コンプライアンスの遵守につきましても、読者ご自身の責任において適法に行っていただきますようお願いいたします。
5. 外部リンクについて
当サイトからのリンクやバナーなどで移動した先の第三者が運営するウェブサイトやサービスにおいて提供される情報、サービス等について、当サイトは一切の責任を負いません。
6. コンテンツの変更・削除について
当サイトのコンテンツ(記事内容、画像、コードスニペット等)や免責事項は、技術動向の変化やサイト運営上の理由により、予告なしに変更、修正、または削除されることがあります。あらかじめご了承ください。
